
株式会社STAR AIの技術チームです。
弊社ではテックブログを更新しているのですが、そこで公開された技術情報を
wantedly内でも共有します。
今後もテックブログシリーズや技術の最新情報などがあれば発信していきます。
どうぞよろしくお願いいたします。
少し長くなりますが、ぜひお時間のある方は最後まで見ていただけると嬉しいです。
目次
1. はじめに
2. ケース背景(ロボット自律ナビゲーション)
3.基礎概念
3.1. 強化学習の基本
3.2. アルゴリズム
4. 実装方法
4.1. 開発環境の構築
4.2. ROS2ノードの定義方法
4.2. 強化学習用の環境実装(Gym形式)
4.3. PPOアルゴリズムでの学習
4.4. 学習済みモデルの利用
5. まとめと展望
1. はじめに
ロボットに自律的な行動を学習させる――そんな夢のような技術が、ROS2と強化学習を組み合わせることで現実味を帯びてきています。ROS2はロボット制御の土台を提供し、強化学習はロボットに試行錯誤から学ぶ知能を与えます。たとえば、ロボットにゴール地点までの行き方を逐一プログラムする代わりに、強化学習を使えばロボット自身が経験を積んでベストな動きを習得できるのです。これはまるでゲームの主人公(ロボット)をトレーニングしてレベルアップさせるようなもので、初心者にとってもワクワクするアプローチではないでしょうか。
本記事では、ROS2と強化学習を用いた自律ナビゲーションの例を解説します。
まずロボットの自律ナビゲーションとは何かを紹介し、次に強化学習の基礎概念を押さえます。その後、Ubuntu上で環境を構築し、コード例(ROS2ノードや強化学習用環境の実装、学習部分)を少しずつ説明していきます。最後に、関連する他の強化学習アルゴリズムや今後の展望についてまとめます。
2. ケース背景(ロボット自律ナビゲーション)
まず「ロボット自律ナビゲーション」とは、ロボットが自分で経路を判断して障害物を避けながら目的地に移動することを指します。
従来、こうした移動ロボットには地図作成(SLAM)や経路計画アルゴリズム(A*やDijkstra、局所経路計画では DWA: Dynamic Window Approach など)が用いられてきました。しかしこれら従来手法はパラメータ調整が多く、環境の変化に対する適応にも限界があります。一方、強化学習を使えばロボット自身が最適な動きを学習できるため、人手による細かなチューニングを減らせる可能性があります。
例えば、シミュレーション上に廊下と曲がり角を用意し、ロボットが端から端まで壁にぶつからず進むタスクを考えましょう。最初ロボットは何も知らないのでランダムに動きますが、壁に衝突すればペナルティ(負の報酬)、ゴールにたどり着けばご褒美(正の報酬)を与えるようにします。するとロボットは試行を重ねる中で「どう動けばぶつからないか」「どのタイミングで曲がれば良いか」を徐々に学習していきます。
これは強化学習ならではの面白さで、ロボットがまるで自分で考えて上達していくように見える瞬間です。
3.基礎概念
3.1. 強化学習の基本
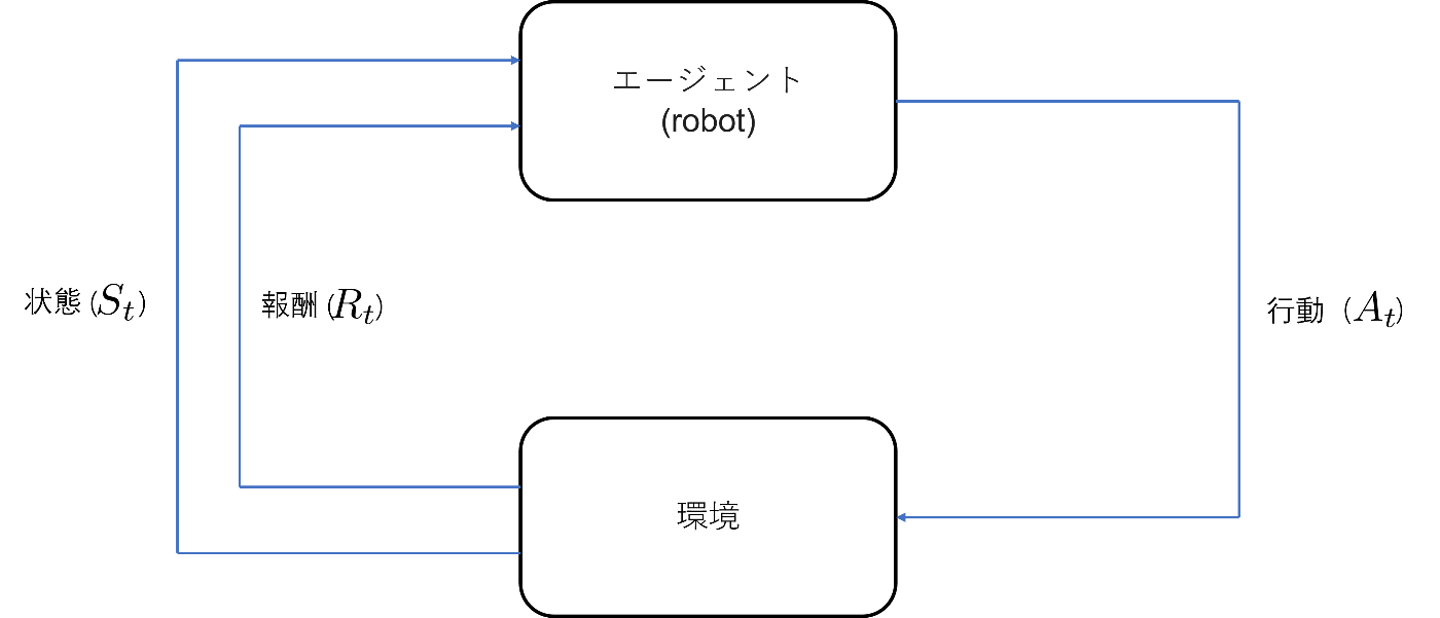
強化学習(Reinforcement Learning, RL)は、エージェント(学習者となる主体)が環境との相互作用を通じて、与えられる報酬を最大化するよう行動方針(ポリシー)を学ぶ機械学習手法です。強化学習にはいくつかの基本要素があります。
- エージェント(Agent): 学習を行い、行動を決定する主体(ここではロボット)。
- 環境(Environment): エージェントが行動する世界(ロボットを取り巻く周囲やシミュレーション空間)。
- 状態(State): 環境の観測可能な状況を表すデータ(センサー情報やロボットの位置など)。
- 行動(Action): エージェントが環境に対して起こす操作(ロボットの速度指令や旋回動作など)。
- 報酬(Reward): エージェントの行動に対して環境から与えられる評価値。
強化学習におけるエージェントの目標は、「累積報酬が最大となるような行動戦略」を見つけ出すことです。具体的には、エージェントは現在の状態をもとに行動を選択し、その結果環境が次の状態と報酬を返します。このサイクルを繰り返しながら、エージェントは試行錯誤によってどの行動が良い結果(高い報酬)をもたらすかを学習していきます。これは人間や動物が試行錯誤を通じて成長する過程に似ているとも言われます。自律ナビゲーションの例で言えば、ゴールに近づけば報酬を与え、衝突すれば罰を与えることで、ロボットは「どう動けば報酬を稼げるか」を経験から学ぶわけです。
3.2. アルゴリズム
強化学習のアルゴリズムには様々な種類がありますが、本記事で用いるPPO(Proximal Policy Optimization)は近年広く使われている代表的な手法の一つです。
PPOはポリシー勾配法(Policy Gradient)に属するアルゴリズムで、エージェントの行動ポリシーそのものをニューラルネットワークで表現し最適化します。PPOの特徴は、方策(ポリシー)を更新する際に信頼領域と呼ばれる考え方を導入し、ポリシーの変化が極端になりすぎないよう制御している点です。
具体的には、新旧ポリシーの差異にペナルティを課したり、更新幅をクリップする手法を用いることで、学習の安定性と効率を両立しています。この仕組みにより、PPOはロボットの連続制御のようなタスクでも安定して性能を発揮しやすく、現在最も効果的な強化学習アルゴリズムの一つとされています。
PPOは以下の特徴を持っています:
- 目的関数の近似: 方策の更新が大きくなりすぎないように制約をかける
- クリッピング: 方策の比率に上限と下限を設けて安定性を確保
数学的な定式化は以下のようになります:
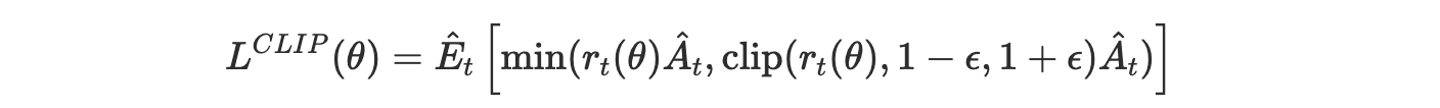
ここで:

4. 実装方法
4.1. 開発環境の構築
まずは開発・学習を行う環境を準備しましょう。本記事では以下のソフトウェア構成を使用します。
- Ubuntu 22.04 LTS:OS(ROS2 Humbleの推奨環境)
- ROS2 Humble : ROS2本体。各種ROSパッケージも必要です。
- Python 3.10 : 実装言語(ROS2のPythonクライアントライブラリ
rclpyを使用)。 - Stable-Baselines3 : 強化学習アルゴリズム実装ライブラリ(PPOを簡単に利用可能)。
pipでインストールします。 - OpenAI Gym / Gymnasium:強化学習環境用インタフェース
上記の環境を用意し、ROS2ワークスペースを作成しておきます。
4.2. ROS2ノードの定義方法
まずROS2ノードの基本的な作り方を押さえます。ROS2では先述のようにノード同士がトピックを介して通信します。Pythonでシンプルなパブリッシャーノードを作成する例を示します。
import rclpy
from rclpy.node import Node
from geometry_msgs.msg import Twist
from sensor_msgs.msg import LaserScan
from nav_msgs.msg import Odometry
import numpy as np
import math
class RLNavigationNode(Node):
"""ROS2強化学習ナビゲーションノード"""
def __init__(self):
# ノードの初期化
super().__init__('rl_navigation_node')
# パブリッシャーの作成(速度指令用)
self.cmd_vel_publisher = self.create_publisher(
Twist, '/cmd_vel', 10)
# サブスクライバーの作成(レーザースキャン用)
self.scan_subscriber = self.create_subscription(
LaserScan, '/scan', self.scan_callback, 10)
# サブスクライバーの作成(オドメトリー用)
self.odom_subscriber = self.create_subscription(
Odometry, '/odom', self.odom_callback, 10)
# タイマーの作成(制御ループ用)
self.timer = self.create_timer(0.1, self.control_loop)
# 状態変数
self.current_scan = None
self.current_pose = None
self.goal_position = np.array([5.0, 5.0])
# 学習済みモデル(実際の使用時にロード)
self.rl_model = None
self.get_logger().info('RLナビゲーションノードが初期化されました')
def scan_callback(self, msg):
"""レーザースキャンデータの処理"""
scan_step = len(msg.ranges) // 8
self.current_scan = np.array([
min(msg.ranges[i * scan_step], 10.0)
for i in range(8)
], dtype=np.float32)
def odom_callback(self, msg):
"""オドメトリーデータの処理"""
pos = msg.pose.pose.position
self.current_pose = np.array([pos.x, pos.y])
# 方向の計算(四元数からヨー角へ)
quat = msg.pose.pose.orientation
self.current_yaw = math.atan2(
2.0 * (quat.w * quat.z + quat.x * quat.y),
1.0 - 2.0 * (quat.y * quat.y + quat.z * quat.z)
)
def get_observation(self):
"""観測ベクトルの構築"""
if self.current_scan is None or self.current_pose is None:
return np.zeros(9)
# 目標への方向を計算
dx = self.goal_position[0] - self.current_pose[0]
dy = self.goal_position[1] - self.current_pose[1]
angle = math.atan2(dy, dx) - self.current_yaw
angle = math.atan2(math.sin(angle), math.cos(angle))
# センサーデータと目標角度を結合
return np.append(self.current_scan, angle / math.pi)
def control_loop(self):
"""メイン制御ループ"""
if self.current_scan is None or self.current_pose is None:
self.get_logger().warn('センサーデータを待機中...')
return
# 現在の観測を取得
observation = self.get_observation()
# 行動を決定(学習済みモデルまたは単純な障害物回避)
if self.rl_model is None:
action = self.simple_obstacle_avoidance()
else:
action, _ = self.rl_model.predict(observation)
# 行動を実行
self.execute_action(action)
def simple_obstacle_avoidance(self):
"""シンプルな障害物回避ロジック"""
if self.current_scan is None:
return 0
min_distance = np.min(self.current_scan)
min_index = np.argmin(self.current_scan)
if min_distance > 1.0:
return 0 # 前進
elif min_index < 4:
return 2 # 右折
else:
return 1 # 左折
def execute_action(self, action):
"""行動を実行して速度指令を送信"""
cmd = Twist()
if action == 0: # 前進
cmd.linear.x = 0.5
cmd.angular.z = 0.0
elif action == 1: # 左折
cmd.linear.x = 0.2
cmd.angular.z = 0.5
elif action == 2: # 右折
cmd.linear.x = 0.2
cmd.angular.z = -0.5
self.cmd_vel_publisher.publish(cmd)
def main():
rclpy.init()
node = RLNavigationNode()
try:
rclpy.spin(node)
except KeyboardInterrupt:
pass
finally:
# ロボットを停止
stop_cmd = Twist()
node.cmd_vel_publisher.publish(stop_cmd)
node.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()ナビゲーションのためのノードは、センサーからの入力を処理し、アクチュエータに指令を送る中枢として機能します。
このナビゲーションノードは、レーザースキャナーとオドメトリーからのデータを処理し、ロボットの現在状態を把握します。control_loop メソッドが実行されるたびに、最新の観測データから最適な行動を決定し、ロボットに速度指令を送信します。
特に重要なのは観測データの前処理部分です。生のセンサーデータは直接使用せず、8方向のレーザー距離と目標への相対角度という形で抽象化しています。これにより、強化学習モデルが扱いやすい形式のデータを提供しています。また、学習済みモデルが利用できない場合でも、シンプルな障害物回避ロジックを用いて基本的なナビゲーションが可能な設計になっています。
4.2. 強化学習用の環境実装(Gym形式)
強化学習アルゴリズムを適用するためには、OpenAI Gymのインターフェースに準拠した環境が必要です。この環境クラスがROS2とGymの橋渡し役となります。
import gym
from gym import spaces
import numpy as np
import rclpy
from rclpy.node import Node
from geometry_msgs.msg import Twist
from sensor_msgs.msg import LaserScan
from nav_msgs.msg import Odometry
import threading
import math
class RobotNavEnv(gym.Env):
"""ROS2ロボットナビゲーション強化学習環境"""
def __init__(self):
super().__init__()
# ROS2の初期化
if not rclpy.ok():
rclpy.init()
self.node = rclpy.create_node('rl_nav_env')
# 行動空間と観測空間の定義
self.action_space = spaces.Discrete(3) # 前進、左折、右折
low = np.zeros(9, dtype=np.float32)
high = np.ones(9, dtype=np.float32) * 10.0
self.observation_space = spaces.Box(low=low, high=high)
# ROS2パブリッシャーとサブスクライバーの作成
self.cmd_pub = self.node.create_publisher(Twist, '/cmd_vel', 10)
self.scan_sub = self.node.create_subscription(
LaserScan, '/scan', self.scan_callback, 10)
self.odom_sub = self.node.create_subscription(
Odometry, '/odom', self.odom_callback, 10)
# 状態変数
self.current_scan = None
self.current_pose = None
self.current_yaw = 0.0
self.goal_position = np.array([5.0, 5.0])
self.episode_steps = 0
# ROS2スレッドの開始
self.executor = rclpy.executors.SingleThreadedExecutor()
self.executor.add_node(self.node)
self.ros_thread = threading.Thread(target=self.executor.spin)
self.ros_thread.daemon = True
self.ros_thread.start()
def scan_callback(self, msg):
"""レーザースキャンデータの処理"""
ranges = np.array(msg.ranges)
ranges[np.isnan(ranges) | np.isinf(ranges)] = msg.range_max
scan_step = len(ranges) // 8
self.current_scan = np.array([
min(ranges[i * scan_step], 10.0) for i in range(8)
], dtype=np.float32)
def odom_callback(self, msg):
"""オドメトリーデータの処理"""
pos = msg.pose.pose.position
self.current_pose = np.array([pos.x, pos.y])
# 四元数からヨー角への変換
quat = msg.pose.pose.orientation
self.current_yaw = math.atan2(
2.0 * (quat.w * quat.z + quat.x * quat.y),
1.0 - 2.0 * (quat.y * quat.y + quat.z * quat.z)
)
def get_observation(self):
"""観測ベクトルの構築"""
if self.current_scan is None or self.current_pose is None:
return np.zeros(9)
# 目標への相対角度を計算
dx = self.goal_position[0] - self.current_pose[0]
dy = self.goal_position[1] - self.current_pose[1]
angle = math.atan2(dy, dx) - self.current_yaw
angle = math.atan2(math.sin(angle), math.cos(angle))
# スキャンデータと目標角度を結合
return np.append(self.current_scan, angle / math.pi)
def reset(self):
"""環境をリセット"""
stop_cmd = Twist()
self.cmd_pub.publish(stop_cmd)
self.episode_steps = 0
return self.get_observation()
def step(self, action):
"""行動を実行して結果を返す"""
self.episode_steps += 1
previous_pose = self.current_pose.copy() if self.current_pose is not None else None
# 行動を実行
cmd = Twist()
if action == 0: # 前進
cmd.linear.x = 0.5
elif action == 1: # 左折
cmd.linear.x = 0.2
cmd.angular.z = 0.5
elif action == 2: # 右折
cmd.linear.x = 0.2
cmd.angular.z = -0.5
self.cmd_pub.publish(cmd)
# 行動の効果を待つ
import time
time.sleep(0.2)
# 新しい観測を取得
observation = self.get_observation()
# 報酬と終了条件の計算
reward = 0.0
done = False
if self.current_pose is not None and previous_pose is not None:
# 目標への距離変化に基づく報酬
current_dist = np.linalg.norm(self.current_pose - self.goal_position)
previous_dist = np.linalg.norm(previous_pose - self.goal_position)
reward = (previous_dist - current_dist) * 10.0
# 衝突検出
if np.min(self.current_scan) < 0.3:
reward = -10.0
done = True
# ゴール到達検出
if current_dist < 0.5:
reward = 20.0
done = True
# 結果を返す
info = {'distance': np.linalg.norm(self.current_pose - self.goal_position)
if self.current_pose is not None else None}
return observation, reward, done, info
def close(self):
"""環境をクローズ"""
stop_cmd = Twist()
self.cmd_pub.publish(stop_cmd)
if hasattr(self, 'executor'):
self.executor.shutdown()
if hasattr(self, 'node'):
self.node.destroy_node()この環境クラスは、ROS2を通じてロボットシミュレーターと相互作用します。stepメソッドでは行動を実行し、新しい観測と報酬を返します。報酬は目標への接近度、衝突の有無、ゴール到達に基づいて計算されます。
また、resetメソッドは環境を初期状態に戻します。LaserScanメッセージのコールバックで最新の距離センサーデータをメンバ変数に保持し、step()内でそれを読み取って観測ベクトルを構成します。
報酬設計も重要なポイントです。
本実装では主に次の要素から報酬を構成しています:
- 距離ベースの報酬: ゴールに近づくほど正の報酬、遠ざかるほど負の報酬
- 衝突ペナルティ: 障害物に近づきすぎると大きな負の報酬
- ゴール到達ボーナス: ゴールに到達した場合に大きな正の報酬
- 時間経過ペナルティ: 効率的な経路選択を促すための小さな負報酬
4.3. PPOアルゴリズムでの学習
環境が定義されたら、次は強化学習アルゴリズムによる学習です。
ここではStable Baselines 3ライブラリのPPO(Proximal Policy Optimization)アルゴリズムを使用します。
from stable_baselines3 import PPO
env = RobotNavEnv() # 先ほど定義した環境
model = PPO("MlpPolicy", env, verbose=1, tensorboard_log="./log/") # モデル
model.learn(total_timesteps=100000) # 10万ステップ学習
model.save("nav_ppo_model")わずか数行ですが、これでPPOエージェントによる学習が開始できます。model.learn(...)を呼ぶと、エージェントは環境envとの間で何度もreset()とstep()を繰り返し、内部的にポリシーネットワークのパラメータを更新していきます。10万ステップの学習を行う設定ですが、実際の環境の複雑さに応じてこの値は調整する必要があります。また、学習の安定性を高めるために、10000ステップごとにチェックポイントを保存する仕組みを導入しています。
4.4. 学習済みモデルの利用
学習が完了したモデルは、実際のナビゲーションタスクで利用することができます。
from stable_baselines3 import PPO
# 学習済みモデルの読み込み
model = PPO.load("./models/nav_ppo_model")
# 評価用環境の作成
env = RobotNavEnv()
# モデルの評価
obs = env.reset()
done = False
total_reward = 0
while not done:
# モデルを使用して行動を予測
action, _ = model.predict(obs)
# 行動を実行
obs, reward, done, info = env.step(action)
# 報酬の累積
total_reward += reward
print(f"行動: {action}, 報酬: {reward}, 目標までの距離: {info['distance']}")
print(f"合計報酬: {total_reward}")
# 環境のクローズ
env.close()実際の応用では、学習済みモデルをROS2ノードに組み込み、リアルタイムで行動決定を行います。この際、モデルの推論速度がロボットの制御周期に対して十分速いことが重要です。また、モデルの不確実性を考慮した行動選択や、複数のモデルを組み合わせたアンサンブル手法も検討価値があります。
5. まとめと展望
本記事では、ROS2と強化学習を組み合わせてロボット自律ナビゲーションを実現する方法を概観しました。はじめに自律走行タスクの面白さと利点を確認し、ROS2や強化学習(PPO)の基礎を紹介しました。PythonでROS2ノードとGym形式の環境クラスを実装する手順を示しました。Stable-Baselines3を用いることでPPOによる学習も少ないコードで実行でき、ロボットが試行錯誤を通じてナビゲーション能力を獲得していく様子をイメージしていただけたかと思います。
今後の展望としては、シミュレーションで学習したポリシーを実ロボットに移行する際の手法の発展や、強化学習と従来の経路計画手法のハイブリッド統合が考えられます。また、自律走行以外にも、マニピュレータの物体把持動作の学習や複数ロボットの協調動作(マルチエージェント強化学習)など、ROS2と強化学習の組み合わせは幅広い応用可能性を秘めています。
/assets/images/22987988/original/88d1726f-9873-47f6-9bf3-7cc801ac5010?1769566145)

/assets/images/21114699/original/ecbd5c65-0a89-4592-8424-105d8b27d11a?1747240698)

/assets/images/22892927/original/ecbd5c65-0a89-4592-8424-105d8b27d11a?1768446888)


