
はじめに
こんにちは。ブランドソリューション開発本部FAANSバックエンドブロックの田村です。普段はサーバサイドエンジニアとしてFAANSのバックエンドシステムの開発をしています。
FAANSとは、弊社が2022年8月に正式ローンチした、アパレル店舗のショップスタッフの販売サポートツールです。FAANSでは、データベースとしてGCPのサーバレスでドキュメント指向のNoSQLデータベースであるCloud Firestoreを当初採用していました。Cloud Firestoreはサーバレスなので運用負荷が掛からず、また安価でスケーラビリティにも優れたハイパフォーマンスなデータベースです。
しかし、Cloud Firestoreを使用して開発・運用していく中で直面した様々な課題からGCPのフルマネージドのリレーショナルデータベースであるCloud SQLのPostgreSQLにデータベースのリプレイスを実施しました。
本記事では、Cloud FirestoreからPostgreSQLへのリプレイス過程を紹介します。
Cloud Firestoreを採用していた理由
FAANSのバックエンドのシステムで利用するデータベースとしてCloud Firestoreを当初採用していました。FAANSのシステムは、アパレル企業毎にその企業と紐付いたスタッフ情報やショップ情報をデータベースで管理します。ユーザーが自分の所属企業とは別の企業のデータにアクセスできてしまわないように、データベース内で企業をテナントの単位としたマルチテナンシーを実現できるデータベースが必要でした。
Cloud Firestoreにはサブコレクションという概念があり、階層構造でデータを保持できます。トップレベルのコレクションとして企業データを管理し、その配下のサブコレクションとしてその企業と紐づくデータを保持することによって、企業単位でデータを完全に分離しマルチテナンシーを安全に運用できます。
Cloud Firestore時代の開発と直面した課題
Cloud Firestoreはドキュメント指向のNoSQLデータベースであるにも関わらず、普段使い慣れているリレーショナルデータベースで求められるようなリレーションモデルの正規化思考が抜けずにデータモデリングしてしまっていて反省すべき点でもあるのですが、データを取得するために仕方なくN+1問題が発生するようなクエリを発行していました。
その結果、Web APIサーバの一部のエンドポイントではリクエストあたりのCloud Firestoreへのクエリ発行回数が極めて多い実装となり、Web APIサーバへのリクエストのレスポンスタイムが大変遅くなってしまうという問題が発生しました。
この問題を解決するために、画面仕様に合わせて適切に非正規化されたデータモデルを設計する必要があると考えました。具体的にどういうことかを、スタッフ一覧の画面を例に説明していきます。
画面仕様を「スタッフの名前とスタッフが所属している店舗の名前をリストで表示する」とします。Cloud Firestoreのデータベース設計を下記のように仮定します。
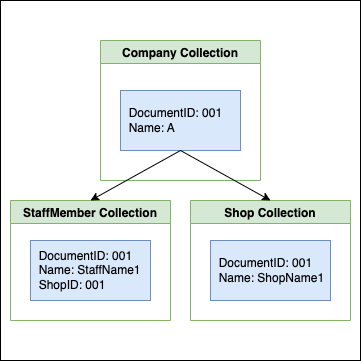
StaffMemberは、とある企業に所属しているスタッフを表現しています。Shopは、店舗ショップ情報を表現しており、スタッフはいずれかのショップに所属しているとします。必要な情報を取得する場合、StaffMemberコレクションから取得した後に、ShopIDを基にShopコレクションからデータを取得する必要があります。パフォーマンス最適化のことを考えると、1コレクションのみから取得できるのが理想です。
そのため、画面仕様に合わせてスタッフ名や所属ショップ名といったデータを適切に非正規化されたデータモデルで保持するために、そのための新しいコレクションを用意するのが良いと考えられます。以下の例では、StaffMemberInfoという新規コレクションを作成しています。
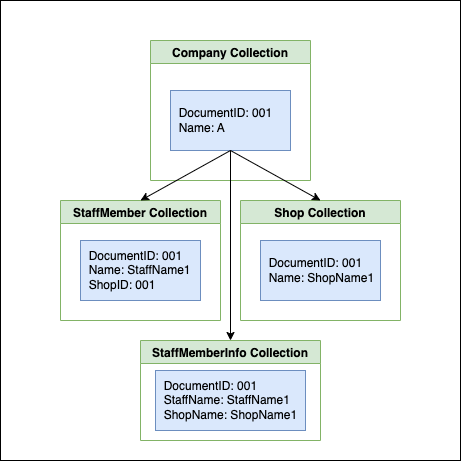
そうすることでN+1問題は回避できますが、新たな問題が生まれてしまいます。画面仕様が「スタッフ名、所属ショップ名、所属事業名のリストを表示する」に変更された場合、新たなフィールドの追加が必要となります。仕様変更の度に変更する必要があり、仕様変更に弱い作りとなります。
さらに、ショップ名等更新があるたびに非正規化している値も更新する必要があります。更新処理が複雑になったり、実装漏れによる更新忘れが発生してしまうことも考えられます。また、非正規化された設計がゆえに、依然として1リクエストあたりのクエリの発行回数が多いためWeb APIサーバーのレスポンスタイムが遅いという問題も残りました。
今後FAANSは事業や組織としても大きくなり、仕様変更の頻度も増えていくと考えられます。そのため、データはできる限り正規化して正しく保持して仕様変更に強くしておくべきだと考えていました。
PostgreSQL採用理由
マルチテナンシーの要件に対応できるデータベースを改めて技術調査したところ、PostgreSQLでRLS(Row Level Security)の機能を利用して実現できることが分かりました。Row Level Securityとは、行単位へのアクセス制御を可能にする仕組みで、PostgreSQL Version 9.5から利用できます。
例えば、企業情報を保持しているcompaniesというテーブルがあるとします。下記のように設定することで、特定のcompany_idに一致するデータのみ取得可能となります。
ALTER TABLE companies ENABLE ROW LEVEL SECURITY;
CREATE POLICY multi_tenant_policy ON companies AS PERMISSIVE FOR ALL TO public USING ((id)::text = current_setting('app.company_id'::text));データ取得の際は、下記のようにクエリを発行することで、company_idが123である企業情報を取得することが可能となります。
BEGIN;
SET LOCAL app.company_id = '123';
SELECT * FROM companies;
COMMIT;SET LOCALにすることにより、このトランザクション内で有効なcompany_idを指定できます。ここでapp.company_idを指定せずにcompaniesを取得しようとするとエラーが出てクエリの実行に失敗します。これにより、誤って別企業のデータを閲覧してしまうことは無くなります。また、適切に正規化できていれば、画面仕様を変更する際は取得するクエリを変更するだけで済みます。
Row Level Securityで安全にマルチテナンシーを運用できる点と、 リレーショナルデータベースで採用されているリレーショナルモデルの方が画面仕様の変更に強い作りとしやすい点からPostgreSQLを採用しました。
Row Level Securityの適用方法
Row Level Securityを利用することになり、安全に運用するために必ずトランザクション内でCRUD処理を行うようにしています。指定された企業ID(companyID)で企業情報を取得する処理のGo言語による実装例を以下に示します。RunTransaction内では、前述のSET LOCAL app.company_idが実行され、必ず企業IDが設定されている状態にしています。もし、RunTransactionを忘れて取得処理を記述してしまっても、クエリの実行時にエラーで失敗するように実装していますのでそのようなミスは発生しません。
err = txm.RunTransaction(ctx, companyID, func(ctx context.Context) error {
// 企業情報取得処理...
})
if err != nil {
return err
}PostgreSQL移行実装
PostgreSQL移行の実装をするにあたり、下記の項目を決定しつつ行いました。
- スキーマ管理方法
- 開発環境、本番環境へのDDL(Data Definition Language)適用方法
- データベースアクセスライブラリの選定
- 既存開発と並行して移行を実装する方針
- データベースマイグレーション
- リリース作業
スキーマ管理方法
開発時のDDLの定義方法は、自分でSQLを実行するかデータベース管理ツールでテーブル定義をするかは、個人の選択に任されています。ただし、最終的なテーブル定義は、チーム全体で揃える必要があります。
そこで利用したのが、sqldefというツールです。sqldefは、適用先のデータベーススキーマとの差分を検出して、必要なDDLを自動で生成や実行してくれる、データベース変更管理ツールです。その中の機能で、指定のデータベースに存在するテーブルのDDLをSQLファイルとして出力できます。生成されたSQLファイルをコミットして管理することで、開発時の定義方法は異なっていたとしても、最終的な成果物は同じ形式で出力されます。
開発環境、本番環境へのDDL適用方法
適用時もsqldefを用いて、コミットされているsqlファイルと適用先のデータベースのスキーマとの間で差分を検出し、その差分のDDLを適用する形で運用しています。テーブル定義に変更が入るような改修をする場合は、差分DDLの結果をPull Requestのコメントとして自動出力されるようにしました。そうすることで、意図しない変更をしようとしていないかを確認できます。レビューで問題なくマージされた場合、CI/CDにより自動でDDL適用がされます。
まとめると、下記の流れとなります。
- ローカル環境のデータベースに新規テーブル定義を追加する
- sqldefで生成されるSQLファイルをgit commitする
- Pull Requestを作成して、開発環境で実行されるDDLがPull Requestのコメントに自動で出力される
- 問題なければ、mainブランチにマージして開発環境に自動的に適用される
データベースアクセスライブラリの選定
Go言語でPostgreSQLにクエリを発行する際に使用するライブラリとして、データベースのテーブル定義を元にコードの自動生成が可能で、型安全で記述ができるSQLBoilerを採用しました。マイグレーション機能はありませんが、前述の通りマイグレーションに関してはsqldefを利用しています。
下記にデータ投入時と取得時のコード例を記載します。ここでは、企業データのモデルをCompanyとします。
データ投入例
company := &model.Company{
Name: company.Name,
}
if err := company.Insert(ctx, db, boil.Infer()); err != nil {
return nil, err
}データ取得例
企業名が、「株式会社ZOZO」のデータを取得する際を例にすると、次のように型安全で記述できます。
companies, err := model.Companies(
model.CompanyWhere.Name.EQ("株式会社ZOZO"),
).All(ctx, db)
if err != nil {
return nil, err
}既存開発と並行して移行を実装する方針
FAANSのバックエンドで動作しているWeb APIサーバーのアーキテクチャとして、クリーンアーキテクチャとRepositoryパターンを採用しています。省略している箇所もありますが、アーキテクチャ図は下記のようになります。
続きはこちら
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


