Discover companies you will love
What we do
Sparkline is a leading digital analytics consultancy headquartered in Singapore with a presence across the APAC region. Founded in 2013, Sparkline was launched with the aim of helping Fortune 500 companies develop a practical, strategic and scaleable approach to Digital Analytics. Through a range of customised consulting, education and in-house technology solutions, Sparkline helps businesses focus on digital maturity, capability building and data governance.
Why we do
Sparkline supports companies making the leap into digital and the world of data-centric measurement frameworks. We've helped businesses of all sizes across the region leverage the power of digital data to take control of their digital strategy; drive brand engagement, optimise online experiences and ultimately increase profitability, we do this because we love to see people and businesses flourish!
Two of our core mottos are 'teamwork makes a dream work' and 'Work hard and stay humble' and we often use the phrase 'Kick Ass'!!
We love what we do and how we do it, we are always looking for hungry, bright sparks to join our team, channeling and utilising your passion for Data, analytics and people and be driven by the challenge and reward which is found through our client delivery. You must want to help people 'flourish'!!
When describing our people, we would say we are a diverse and empowered team, we work closely and tirelessly to deliver the quality of data analytics projects and training programmes because we know the impact this has on the industry and the people within it!
How we do
Sparkline takes a business first strategy to customer engagement. Our team of ‘Sparks’ are highly qualified, passionate and strive to build partnerships that deliver results through creative and practical suggestions that have immediate impact on businesses while maintaining an agnostic approach to the industry, and integrity through transparency.
We want to support our awesome team to grow in their career and develop their core and undiscovered expertise. We all have a passion for supporting our peer's development. Our Sparks see the marriage between people and data as an integral one and we strive to ensure we keep abreast of all technical changes and developments in the industry to stay relevant and able to consult with knowledge (this is power after all). Along the way we constantly work to build and grow a team of wonderful, empowered and excited 'Sparks' who make this dream a reality!
Of course while we do this, when we can, we want to have fun, enjoy who we work with and learn as much as we can while we do it. One recurring theme we see when we look at the feedback from our esteemed 'Sparkline alumni' is that all our people naturally strive to embrace our 'learning environment'. There is never a dull day at Sparkline, we move at lightning speed but with passion and energy we are able to do this with smiles on our faces and the knowledge we have a solid team around us to support us along the way.
We often refer to ourselves as the 'United Nations of Sparkline', how awesome is that? We not only work with International clients (some pretty impressive folks may we add!) but we have a wonderfully eclectic team, eclectic in terms of nationality, skills sets and personality!!!
Oh did we mention we are all superheroes? More on that when we speak!! :)
/assets/images/13182021/original/cf10163f-dfff-4e84-8ad1-02526424ae80?1683013581)
/assets/images/2107564/original/1537d1e7-dd0a-4e30-85b0-c3f953bd4bd5?1683013575)
/assets/images/2107563/original/3f2d0df7-033b-41fb-a9f2-2955232e9fdc?1683013575)
/assets/images/13182000/original/1fd0e8c5-9317-4c3c-81d2-488392d807db?1683013576)
/assets/images/2200296/original/27cf8437-ac4e-47b7-beae-0a9cb5b56636?1683013575)
/assets/images/13182028/original/e5738203-a792-42ce-bbae-4f6cb303615f?1683013581)
As a new team member
ABOUT SPARKLINE:
At Sparkline, we’re not interested in being ‘the smartest guy in the room’! We want to be a trusted partner, strategic asset and integral part of our client’s business. We are a small team and at our strongest when we leverage each other’s strengths. We roll up our sleeves and move at lightning pace to get the job done!
OUR DNA:
Passion for digital and data, and the value it brings to both consumers and businesses
Dedication to become a value based partner, delivering above and beyond client expectations
Humility to work integrity, good intent and transparency
Curiosity to explore the possibilities and the opportunities from the information you are given
Creativity to see beyond the answer and use insights to effectively reach potential customers
Fail Fast, Learn Faster it’s about progress not perfection
Entrepreneurial in attitude and action, effortlessly innovating and adapting
Embrace Change - ‘It’s not the strongest or the most intelligent who will survive, but those that can best manage change’....that’s Charles Darwin by the way!
THE ROLE:
You will work with our valued client base and peers across the Regional team base to help to design, implement, and manage data pipelines from end-to-end.
This will include:
Gather and process raw data at scale (including writing ETL scripts, scraping webpages, calling APIs, writing SQL queries, etc.).
Explain in layman terms how the data flows between processes and systems.
Work closely with clients' engineering teams to integrate your innovations and algorithms into their production systems.
Take ownership of systems' up-time, including resolving application, performance, and systems incidents and errors as quickly as possible.
Support business decisions with ad hoc analysis as needed.
THE PERSON
You should be a creative problem solver, resourceful in getting things done, and productive when working independently or collaboratively. You should also have the ability to undertake new initiatives to deliver the best work. You will be hands on and technically savvy and have the passion to support varied points of contact internally and externally to achieve success through effective delivery.
YOU WILL BRING
2-5 years of experience in data application development, including building machine learning projects from start to end.
Google Cloud, especially with Kubernetes, BigQuery and other data analytics services provided by Google Cloud.
Python: 3 years, especially with libraries like numpy, scikit, Flask and pandas.
Development tools and frameworks: Docker, Node.js + Gulp, D3.js.
Required: Please provide publicly accessible links to your sample code of your data analytics and machine learning applications.
What we do
/assets/images/13182021/original/cf10163f-dfff-4e84-8ad1-02526424ae80?1683013581)
/assets/images/2107564/original/1537d1e7-dd0a-4e30-85b0-c3f953bd4bd5?1683013575)
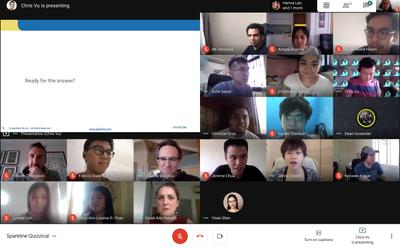
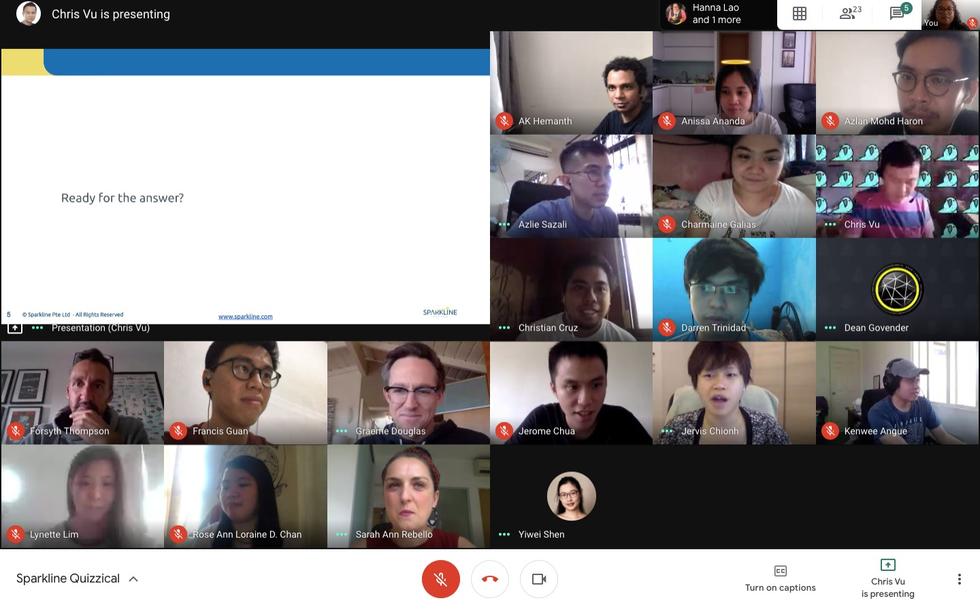
Sparkline: Internal Training and Sharing Sessions - we kicked off this New Year with a HR workshop, we were able to learn more about how we can all work together better and about how our Social Styles impact our working style!
Sparkline is a leading digital analytics consultancy headquartered in Singapore with a presence across the APAC region. Founded in 2013, Sparkline was launched with the aim of helping Fortune 500 companies develop a practical, strategic and scaleable approach to Digital Analytics. Through a range of customised consulting, education and in-house technology solutions, Sparkline helps businesses focus on digital maturity, capability building and data governance.
Why we do
/assets/images/2200296/original/27cf8437-ac4e-47b7-beae-0a9cb5b56636?1683013575)
Happy TGIF! Every Friday our team gets together to toast to the weekend after a busy week and the hard working Delivery and Ops Team get to spend time together to day thanks for everyone's hard graft and team work!
/assets/images/13182028/original/e5738203-a792-42ce-bbae-4f6cb303615f?1683013581)
Sparkline supports companies making the leap into digital and the world of data-centric measurement frameworks. We've helped businesses of all sizes across the region leverage the power of digital data to take control of their digital strategy; drive brand engagement, optimise online experiences and ultimately increase profitability, we do this because we love to see people and businesses flourish!
Two of our core mottos are 'teamwork makes a dream work' and 'Work hard and stay humble' and we often use the phrase 'Kick Ass'!!
We love what we do and how we do it, we are always looking for hungry, bright sparks to join our team, channeling and utilising your passion for Data, analytics and people and be driven by the challenge and reward which is found through our client delivery. You must want to help people 'flourish'!!
When describing our people, we would say we are a diverse and empowered team, we work closely and tirelessly to deliver the quality of data analytics projects and training programmes because we know the impact this has on the industry and the people within it!
How we do
/assets/images/2107563/original/3f2d0df7-033b-41fb-a9f2-2955232e9fdc?1683013575)
Sparks: We LOVE training! This is the team with Sparkline Alumni from Go Jek and OVO talking to our trainees from our IMDA Partner programme - TIPP! We are passionate to build Future Skills and Train Future Analysts!
/assets/images/13182000/original/1fd0e8c5-9317-4c3c-81d2-488392d807db?1683013576)
Sparkline takes a business first strategy to customer engagement. Our team of ‘Sparks’ are highly qualified, passionate and strive to build partnerships that deliver results through creative and practical suggestions that have immediate impact on businesses while maintaining an agnostic approach to the industry, and integrity through transparency.
We want to support our awesome team to grow in their career and develop their core and undiscovered expertise. We all have a passion for supporting our peer's development. Our Sparks see the marriage between people and data as an integral one and we strive to ensure we keep abreast of all technical changes and developments in the industry to stay relevant and able to consult with knowledge (this is power after all). Along the way we constantly work to build and grow a team of wonderful, empowered and excited 'Sparks' who make this dream a reality!
Of course while we do this, when we can, we want to have fun, enjoy who we work with and learn as much as we can while we do it. One recurring theme we see when we look at the feedback from our esteemed 'Sparkline alumni' is that all our people naturally strive to embrace our 'learning environment'. There is never a dull day at Sparkline, we move at lightning speed but with passion and energy we are able to do this with smiles on our faces and the knowledge we have a solid team around us to support us along the way.
We often refer to ourselves as the 'United Nations of Sparkline', how awesome is that? We not only work with International clients (some pretty impressive folks may we add!) but we have a wonderfully eclectic team, eclectic in terms of nationality, skills sets and personality!!!
Oh did we mention we are all superheroes? More on that when we speak!! :)
As a new team member
ABOUT SPARKLINE:
At Sparkline, we’re not interested in being ‘the smartest guy in the room’! We want to be a trusted partner, strategic asset and integral part of our client’s business. We are a small team and at our strongest when we leverage each other’s strengths. We roll up our sleeves and move at lightning pace to get the job done!
OUR DNA:
Passion for digital and data, and the value it brings to both consumers and businesses
Dedication to become a value based partner, delivering above and beyond client expectations
Humility to work integrity, good intent and transparency
Curiosity to explore the possibilities and the opportunities from the information you are given
Creativity to see beyond the answer and use insights to effectively reach potential customers
Fail Fast, Learn Faster it’s about progress not perfection
Entrepreneurial in attitude and action, effortlessly innovating and adapting
Embrace Change - ‘It’s not the strongest or the most intelligent who will survive, but those that can best manage change’....that’s Charles Darwin by the way!
THE ROLE:
You will work with our valued client base and peers across the Regional team base to help to design, implement, and manage data pipelines from end-to-end.
This will include:
Gather and process raw data at scale (including writing ETL scripts, scraping webpages, calling APIs, writing SQL queries, etc.).
Explain in layman terms how the data flows between processes and systems.
Work closely with clients' engineering teams to integrate your innovations and algorithms into their production systems.
Take ownership of systems' up-time, including resolving application, performance, and systems incidents and errors as quickly as possible.
Support business decisions with ad hoc analysis as needed.
THE PERSON
You should be a creative problem solver, resourceful in getting things done, and productive when working independently or collaboratively. You should also have the ability to undertake new initiatives to deliver the best work. You will be hands on and technically savvy and have the passion to support varied points of contact internally and externally to achieve success through effective delivery.
YOU WILL BRING
2-5 years of experience in data application development, including building machine learning projects from start to end.
Google Cloud, especially with Kubernetes, BigQuery and other data analytics services provided by Google Cloud.
Python: 3 years, especially with libraries like numpy, scikit, Flask and pandas.
Development tools and frameworks: Docker, Node.js + Gulp, D3.js.
Required: Please provide publicly accessible links to your sample code of your data analytics and machine learning applications.
0 upvotes
Highlighted stories
0 upvotes
What happens after you apply?
- ApplyClick "Want to Visit"
- Wait for a reply
- Set a date
- Meet up
Company info