Beautiful algorithms used in a compiler and a stack based virtual machine ~Part 3. How to compile global bindings~

This is the December 13th article for Wantedly 2021 Advent Calendar.
This is the third part of the series "Beautiful algorithms used in a compiler and a stack based virtual machine". In this series, I share algorithms, which I found interesting while implementing a compiler in Go by following two books, "Writing an interpreter in Go" and "Writing a compiler in Go" by Thorsten Ball. The specification of the Monkey language is explained in this page.
In this post, I will focus on how global bindings, which means defining and resolving variables in the global scope, are compiled and executed in Monkey. This is picked up in the fifth chapter of a book "Writing a compiler in Go". I recommend that you read part 1 of this series, which introduces the whole set of steps the compiler and the VM in Monkey take to execute the source code. The tokenizing step and the parsing step are not explained in this post.
- Part 1. Design of the Monkey compiler
- Part 2. How the Pratt parser in the Monkey compiler works
- Part 3. How to compile global bindings (this post)
- Part 4. How to compile functions
- Part 5. What Monkey does not have, but Java has
This post consists of three sections. In the first section, I wil introduce the strategy used by the compiler and the VM in Monkey to handle global bindings. In the second section, I will show the interfaces of the compiler and the VM. In the final section, I will work on the implementation of them.
§1. The compiler and the VM in Monkey
In this section, I will first briefly introduce how the compiler and the VM work together in Monkey, which was already explained in part 1 of the series. Then, I will go into the main topic of this post, the mechanisms in which they handle global bindings.
Role of the compiler and the VM in Monkey
After the lexer and the parser generate the AST from source code, it is converted into the bytecode in the final step of the compiler. The bytecode is comprised of two components: the instructions and the constant pool. The VM follows instructions in this bytecode. During this execution, intermediate results, which are objects, are stored in the data stack.
Strategy used to define/resolve global bindings in Monkey
First, I will explain how the definition and the resolving of the bindings are represented in the bytecode, and how the VM executes it.
In the Monkey source code, a binding is defined by a let statement like below.
let two = 2;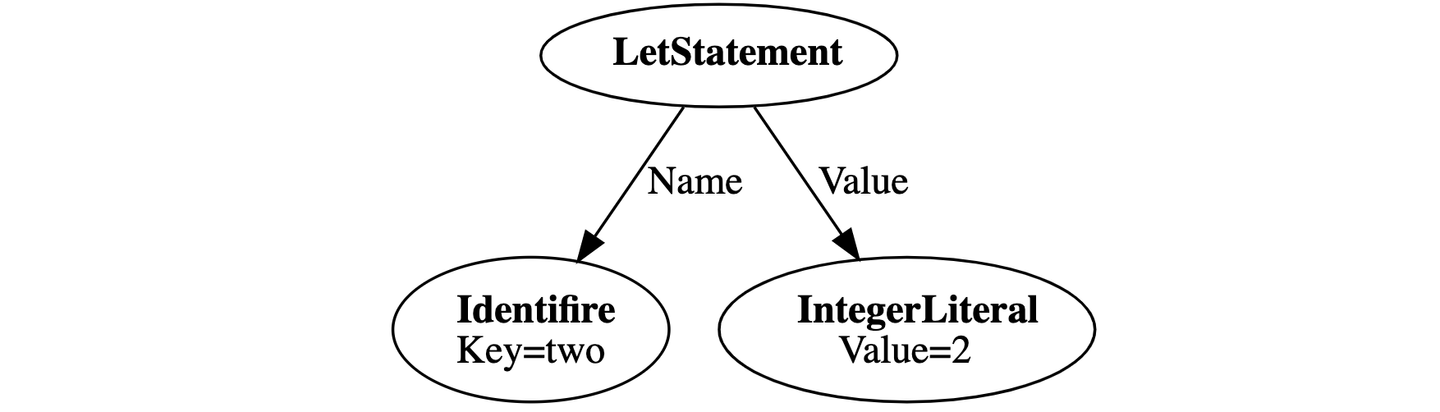
This source code is converted into the LetStatement node by the lexer and the parser. From this node, the compiler should emit instructions in the way below. Please keep in mind that an integer is held as an object in Monkey.
- First, the instruction(s) is/are emitted by compiling the expression which is the value on the right side of the statement. In the VM, this results in putting the generated object on the top of the data stack.
- Then, an instruction of OpSetGlobal is emitted. This tells the VM to pop the object which is at the top of the data stack, and put it in the globals store, where the objects bound to the variables are stored. The operand specifies which index in the data store it should be put.
The most important idea used here is that in the VM, the objects are stored in a 1-dimension data store held by the VM, and the index in the store is used as the identifier in order to get the object. This is one of the reasons why compiled languages are executed faster than interpreted languages. The mechanism used in the compiler to manage the mapping from a variable name to the index in the store will be illustrated later.
In the Monkey source code, an identifier (variable) is resolved with the bound value.
two;
This source code is converted into an Identifier node, and then the compiler emits the instruction below.
- An instruction of OpGetGlobal is emitted. This tells the VM to get the object from the globals store. The operand specifies the index in the data store.
Now, I will illustrate the mechanism taken in the compiler to count the indexing of the bindings. It uses a hashmap named SymbolTable to associate the original variable name and the index in the data store of the VM.
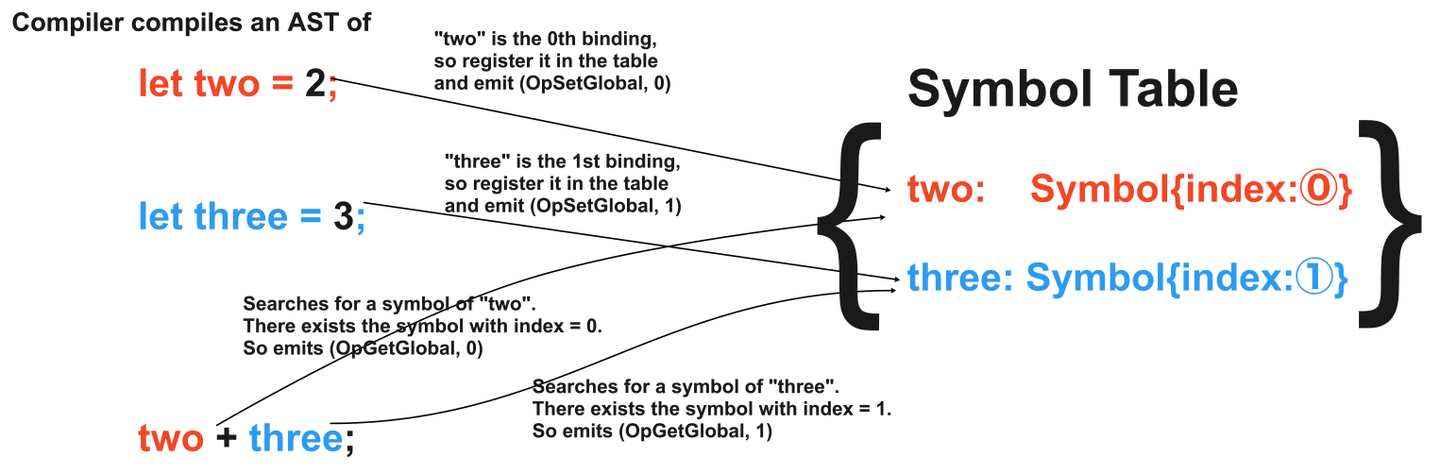
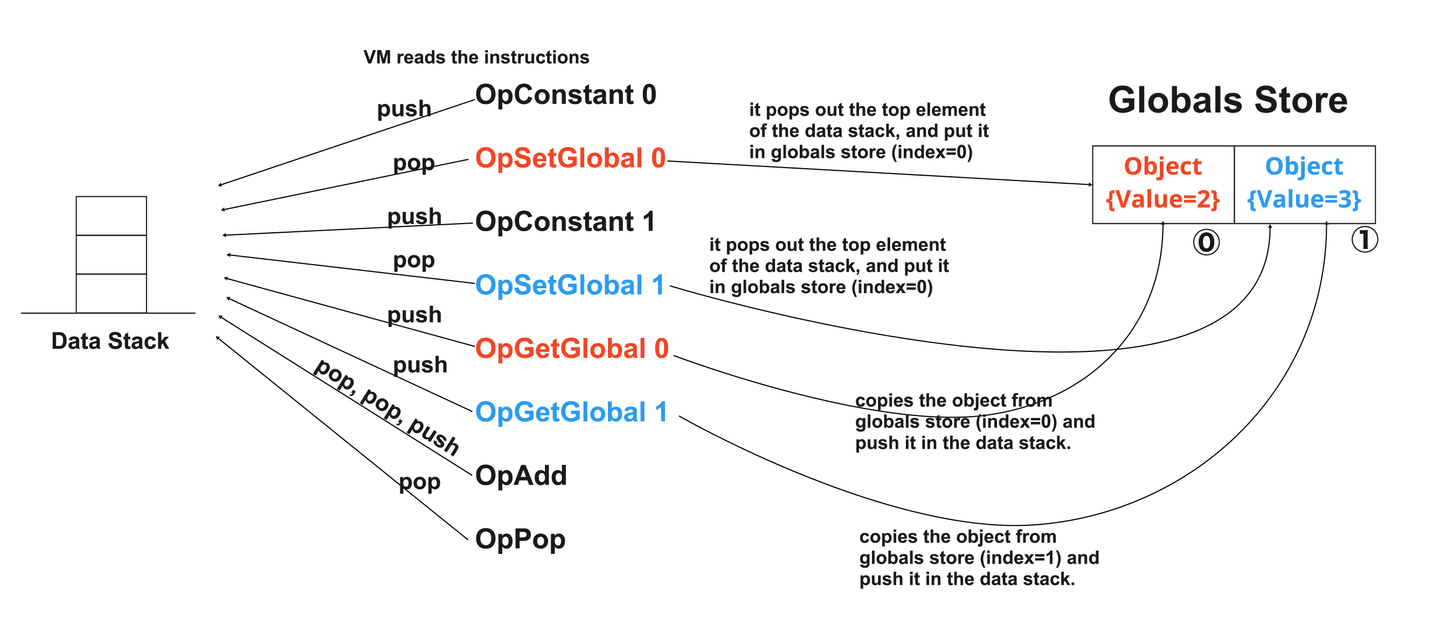
The VM works as shown below when it encounters an OpSetGlobal/OpGetGloabl instruction in the bytecode. As aforementioned, it holds the bound objects in a slice named globals store. The operand of an OpSetGlobal/OpGetGlabal instruction specifies the index in the store.
§2. Interfaces of the compiler and the VM in Monkey
In this section, I will show the interfaces of the compiler and the VM, which will be implemented in the following section.
For simplicity, I will narrow down the scope. The compiler and VM will be implemented so that they can execute the AST which includes only integer literals, let statements, and plus operations in the global scope. That is, the goal in this section is to parse the expression below.
// input: ast of
let two = 2;
let three = 3;
two + three;Please note that the snippets in this section are not the same as the codebase of kudojp/MonkeyCompiler-Golang2021. This is because this post focuses on introducing how to handle global bindings. Thus, the snippets are simplified as much as possible to satisfy this objective. In the part 3 of this series, they will be updated to handle local bindings. Also, even though the compiler and the VM execute a valid AST correctly, they are not guaranteed to throw compile/runtime errors as expected when an invalid AST is given.
Interfaces of the Compiler and the VM
First, I introduce how the compiler and the VM are constructed and then run.
compiler := &compiler.Compiler{
constants: []object.Object{},
symbolTable: symbolTable,
}
compiler.Compile(ast) // `ast` is the output of the parser.
vm := &vm.VM{
instructions: bytecode.Instructions,
constants: bytecode.Constants,
globals: make([]object.Object, GlobalsSize), // globals store
stack: make([]object.Object, StackSize), // data stack
sp: 0, // stack pointer
}
vm.Run()The interfaces of three structs: Bytecode, Compiler, and VM will be shown below.
The Bytecode includes the instructions, which is a byte array, and the constant pool which is a slice of objects.
package compiler
type Bytecode struct {
Instructions []code.Instructions
Constants []object.Object
}The Compiler holds the instructions, the constants which are created from a given AST, and the symbol table as the fields.
package compiler
type Compiler struct {
instructions []code.Instructions
constants []object.Object
symbolTable *SymbolTable
}
func (c *Compiler) Compile(node ast.Node) {
switch node := node.(type) {
case xxx:
// the logic to compile xxx node here.
// TODO: Add cases to compile other types of nodes.
}
/*
helper method
Returns instructions generated from an opcode and operand(s).
*/
func (c *Compiler) emit(op code.Opcode, operands ...int) int {
ins := code.Make(op, operands...)
c.instructions := append(c.instructions, ins...)
}
/*
Returns bytecode created from an AST given at the construction.
Compiler method should be called before this method is called.
*/
func (c *Compiler) ByteCode() *Bytecode {
return &Bytecode{
Instructions: c.instructsions,
Constants: c.constants,
}
}The VM is shown below. Please note that the instruction pointer, which indicates the current offset in the bytecode, is held as a local variable in the Run method.
package vm
type VM struct {
instructions code.Instructions
constants []object.Object
globals []object.Object // globals store
stack []object.Object // data stack
sp int // stack pointer which points to the index where an object is to be put next.
}
func (vm *VM) Run() {
ip := 0
for ip < len(vm.instructions)-1 {
ip += 1
op := code.Opcode(ins[ip])
switch op {
case code.OpXXX:
// the logic which folllows the instruction OpXXX here.
// TODO: Add cases to handle other instructions like above.
}
}
}
/*
helper method
Pop an object from the data stack.
*/
func (vm *VM) pop() object.Object {
obj := vm.stack[vm.sp-1]
vm.sp--
return obj
}
/*
helper method
Push an object into the data stack.
*/
func (vm *VM) push(obj object.Object) {
if vm.sp >= StackSize {
panic("stack overflow")
}
vm.stack[vm.sp] = obj
vm.sp += 1
return nil
}§3. Implementation the Monkey compiler and the VM
In this section, I will work on the implementation of the compiler and the VM in two steps. The compiler will be implemented in the first step, and the VM in the second step. I will strongly focus on explaining the logic to handle global bindings.
Implementation 1. Enable the compiler to compile an AST
As aforementioned, a variable name in the source code is mapped into the index in the globals store in the compiler. For this, I will define the SymbolTable struct which is responsible for that logic.
The SymbolTable struct holds not just an integer of index, but a Symbol struct as its values. This is because the SymbolTable is used to define/resolve not only global bindings, but also local bindings in the next post. For this purpose, the bindings should be uniquely identified by the combination of the name and the scope.
package compiler
type Symbol struct {
Name string
Scope SymbolScope // SymbolScope is an alias of string
Index int
}
type SymbolTable struct {
store map[string]Symbol
numDefinitions int
}
/*
Register a newly created Symbol struct which corresponds to a given variable name,
and returns the symbol.
*/
func (s *SymbolTable) Define(name string) Symbol {
symbol := Symbol{
Name: name,
Scope: "GlobalScope",
Index: s.numDefinitions
}
s.store[name] = symbol
s.numDefinitions++
return symbol
}
/*
Resolve a given variable name and returns the corresponding Symbol struct.
*/
func (s *SymbolTable) Resolve(name string) Symbol {
sym, ok := s.store[name]
if !ok {
panic(fmt.Sprintf("variable %s is not defined", name))
}
return sym
}With this symbol table, the compiler compiles a LetStatement/Identifier node, where the global bindings are defined/resolved in this way.
func (c *Compiler) Compile(node ast.Node) {
switch node := node.(type) {
case *ast.LetStatement:
symbol := c.symbolTable.Define(node.Name.Value)
c.Compile(node.Value)
c.emit(code.OpSetGlobal, symbol.Index)
case *ast.Identifier:
symbol, ok := c.symbolTable.Resolve(node.Value)
if !ok {
panic(fmt.Sprintf("undefined variable %s", node.Value))
}
c.emit(code.OpGetGlobal, symbol.Index)
// Omitted: cases of other types of nodes here
}
}The complete version of the Compile method is below. The logic to compile ExpressionStatement nodes, IntegerLiteral nodes, and InfixExpression nodes are added.
func (c *Compiler) Compile(node ast.Node) {
switch node := node.(type) {
case *ast.Program:
for _, s := range node.Statements {
c.Compile(s)
}
case *ast.LetStatement:
symbol := c.symbolTable.Define(node.Name.Value)
c.Compile(node.Value)
c.emit(code.OpSetGlobal, symbol.Index)
case *ast.Identifier:
symbol, ok := c.symbolTable.Resolve(node.Value)
if !ok {
panic(fmt.Sprintf("undefined variable %s", node.Value))
}
c.emit(code.OpGetGlobal, symbol.Index)
case *ast.ExpressionStatement:
c.Compile(node.Expression)
c.emit(code.OpPop)
case *ast.IntegerLiteral:
integer := &object.Integer{Value: node.Value}
c.emit(code.OpConstant, c.addConstant(integer))
case *ast.InfixExpression:
c.Compile(node.Left)
c.Compile(node.Right)
switch node.Operator {
case "+":
c.emit(code.OpAdd)
// Omitted here: cases of other infix operators
default:
panic(fmt.Sprintf("unknown operator %s", node.Operator))
}
}
}Implementation 2. Enable the VM to execute bytecode
I will show how the VM executes an OpSetGlobal/OpGetGlobal instruction. The position (index) in the globals store is specified by the operand.
func (vm *VM) Run() {
ip := 0
for ip < len(vm.instructions)-1 {
ip += 1
op := code.Opcode(ins[ip])
switch op {
case code.OpSetGlobal:
globalIndex := code.ReadUint16(ins[ip+1:])
ip += 2
vm.globals[globalIndex] = vm.pop()
case code.OpGetGlobal:
globalIndex := code.ReadUint16(ins[ip+1:])
ip += 2
vm.push(vm.globals[globalIndex])
}
}
}The complete version of the Run method is below. The logic to handle OpConstant, OpAdd, and OpPop instructions is added.
func (vm *VM) Run() {
ip := 0
for ip < len(vm.instructions)-1 {
ip += 1
op := code.Opcode(ins[ip])
switch op {
case code.OpSetGlobal:
globalIndex := code.ReadUint16(ins[ip+1:])
ip += 2
vm.globals[globalIndex] = vm.pop()
case code.OpGetGlobal:
globalIndex := code.ReadUint16(ins[ip+1:])
ip += 2
vm.push(vm.globals[globalIndex])
}
case code.OpConstant:
constIndex := code.ReadUint16(ins[ip+1:])
ip += 2
vm.push(vm.constants[constIndex])
case code.OpAdd:
vm.executeBinaryOperation(op)
case code.OpPop:
vm.pop()
}
}
/*
helper method used to execute an OpAdd instruction.
*/
func (vm *VM) executeBinaryIntegerOperation(op code.Opcode) {
right := vm.pop()
left := vm.pop()
if right.Type() == object.INTEGER_OBJ && left.Type() == object.INTEGER_OBJ{
leftVal := left.(*object.Integer).Value
rightVal := right.(*object.Integer).Value
var result int64
switch op {
case code.OpAdd:
result := leftVal + rightVal
return vm.push(&object.Integer{Value: result})
// Omitted here: cases of other operators
default:
panic(fmt.Sprintf("unknown integer operator: %d", op))
}
return vm.push(&object.Integer{Value: result})
}
panic(fmt.Sprintf("unsupported types for binary operation: %s %s", leftType, rightType))
}§4. Summary
In this post, I explained how the compiler and the VM execute global bindings. When compiling, the compiler uses a hashmap named symbol table for indexing the global variable names in the source code. OpSetGlobal/OpGetGlobal instructions in the bytecode tell the VM to put/copy objects in the globals store. The position (index) in the store is specified by the operands.



