■AI×医学情報、正確性とパーソナライズの両立に挑む
こんにちは!株式会社ケアネット採用担当です。 唐突ですが、皆さんは1日にどれくらいの医学論文が発表されると思いますか?
実は、世界中で1日に5,000本以上もの論文が出ていると言われています。ただでさえ多忙な医師が、この膨大な情報の中から最新の知見を継続的にキャッチアップすることは、極めて困難です。
今回当社がリリースした『CareNet Academia(ケアネット・アカデミア)』は、AI技術を用いて、医師一人ひとりの専門性に合わせて、膨大な論文の中から「今、読むべき情報」を選定・要約し、プッシュ型で届けるサービスで、すでに多くの医師から好評いただいています。
しかし、その裏側ではどのようにして”医学情報の正確性を担保するのか”や”適切にパーソナライズさせるのか”など、泥臭くも緻密なエンジニアリングが求められました。なぜ開発に1年以上を費やしたのか。そして、その技術的挑戦の全貌や今後の更なる拡大のために、一緒に働いてくださる方がどのような環境でどのような経験ができるのか、をインタビューしました!
目次
■AI×医学情報、正確性とパーソナライズの両立に挑む
■プロフィール紹介
■新サービス「CareNet Academia(ケアネット・アカデミア)」の概要
■開発背景 「より専門的」へ。求められる情報の変化
■開発まで 高い品質を満たすための試行錯誤
■組織と展望 求めるのは「現状を打破する意思」
■採用担当より
■プロフィール紹介
・氏名:榊原 海
・役職:執行役員CTO(Chief Technology Officer)兼 AI技術開発室長
・入社:2019年4月入社
・経歴:2006年慶應義塾大学大学院にてAIの研究に携わりながら、位置情報スタートアップの創業に参画。取締役CTO、取締役副社長を歴任し、同社をNTTドコモに売却。
2019年より株式会社ケアネット入社。新規事業会社立ち上げ、新規サービス立ち上げ等に従事し、現在は執行役員CTOおよび子会社取締役として、グループ全体でAI技術の活用に取り組む。
※本取材は2025年12月に行いました。インタビュー内容は取材時のものです。
■新サービス「CareNet Academia(ケアネット・アカデミア)」の概要
── 今回リリースされた「CareNet Academia(ケアネット・アカデミア)」について、まずはサービスの概要を教えてください。
一言で言うと、医師一人ひとりの専門性に特化した最新の医学情報を、プッシュ型で届けるサービスです。
医学論文は毎日5,000本以上も出るとされていますが、医師が診療の合間に自分の専門領域に合った論文をすべてチェックするのは不可能です。PubMed※などのデータベースで複雑な検索式を組んでアラート設定している先生も一部いらっしゃいますが、大半の先生はその時間を確保できません。
※PubMed:世界中の多数の学術誌の文献情報が掲載されている文献検索サービス
── 物理的に読み切れる量ではないですね。
そうです。だからこそ、テクノロジーによる「情報のフィルタリング」と「適切な要約」が必要でした。 このサービスでは、2種類のAIが動いています。一つは、論文の要旨(アブストラクト)を日本語の読みやすい記事にする「ライターAI(生成AI)」、もう一つは、医師の行動ログや専門情報をもとに最適な記事を選ぶ「レコメンドAI(独自モデル)」です。
あえて「AI」と総称しているのは、流行りの生成AI一辺倒になるのではなく、適材適所の技術を組み合わせることにこだわったからです。
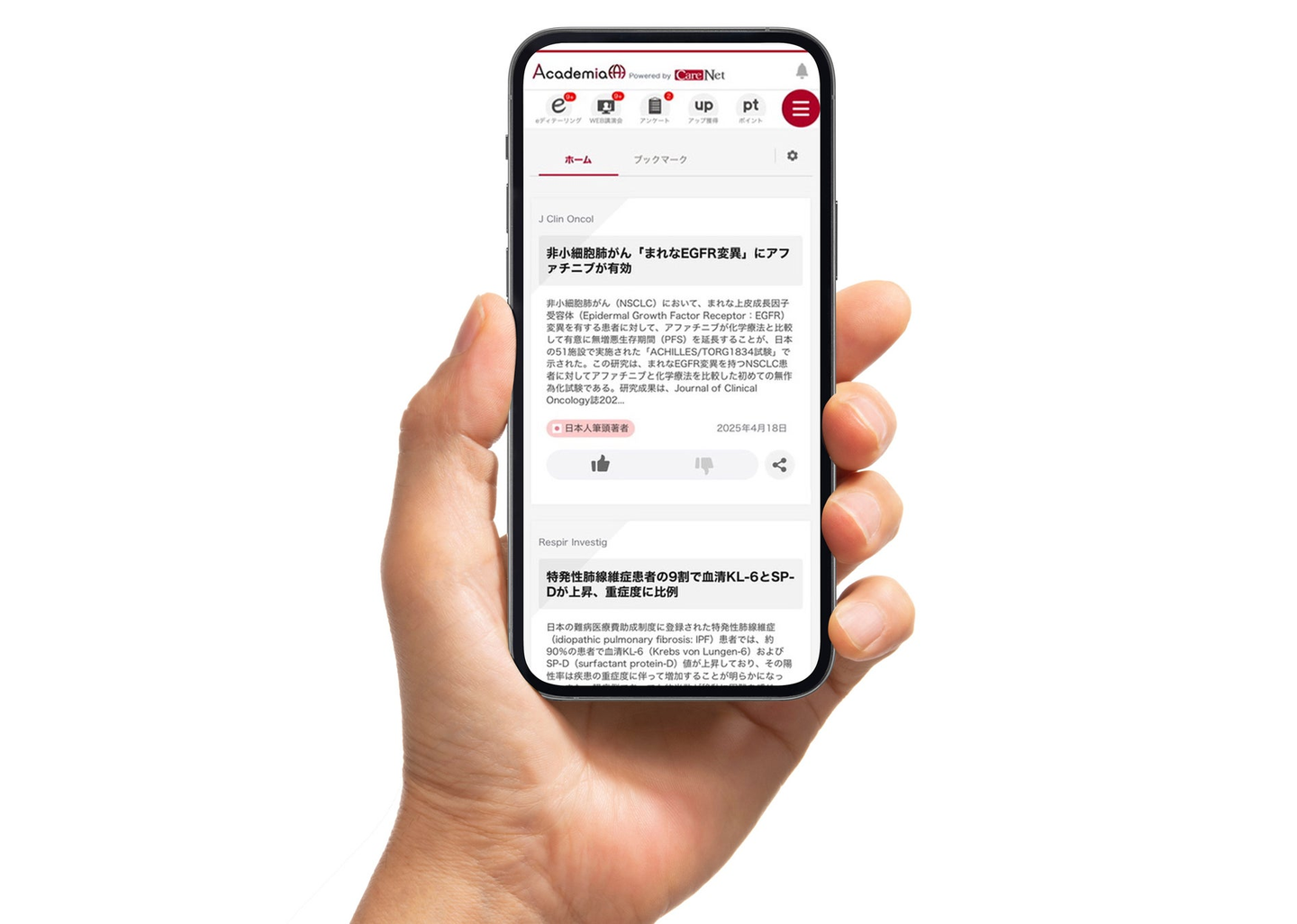
👆CareNet Academiaイメージ
■開発背景 「より専門的」へ。求められる情報の変化
── まず、「CareNet Academia」の開発背景について教えてください。既存の「CareNet.com」とは何が違うのでしょうか?
背景には、医療・製薬業界における大きな構造変化があります。 これまでケアネットは、プライマリ・ケア(総合診療)を中心とした多くの医師に対し、広く情報を届ける「マス向けのアプローチ」で成長してきました。
しかし現在、医療技術、創薬のトレンドは、より高度で専門性の高い「スペシャリティ領域」へとシフトしています。専門性の高い医師たちは、一般的な医療ニュースはすでに知っていることが多く、満足されません。そんな医師が望んでいるのは、自分の研究や臨床に直結する「最先端のアカデミックな情報」です。それを満たすために「速報性」と「アカデミック性」を重視した論文紹介サービスに行き着きました。
■開発まで 高い品質を満たすための試行錯誤
――「CareNet Academia」で使われているAI技術について教えてください。
大きく2つのAIを組み合わせています。一つは「ライターAI」です。これは生成AI(LLM)を使用し、英語の論文アブストラクト(要旨)を読みやすい日本語記事に変換します。もう一つは「レコメンドAI」です。こちらは生成AIではなく、我々が独自開発したレコメンドエンジンです。医師の閲覧ログや登録された専門情報、興味関心をベースに、最適な論文をマッチングします。
――AIを医療情報に使う際、ハルシネーション(事実に基づかない生成)や品質の担保が課題になると思います。開発はどのように進めましたか?
おっしゃる通り、生成AIは出力が安定しないため、3段階のPoC(概念実証)を経て慎重に進めました。
• フェーズ1:AIが書いた記事が、正確性も表現も人間が書いた記事に対して「非劣性(劣っていないこと)」であるかを検証しました。ケアネットが蓄積した膨大な記事を参考にプロンプト(指示文)を徹底的に改善し、数百の記事を評価しました。
• フェーズ2: ルールベースのシンプルなロジックでレコメンドを行い、医師の興味関心に合致し、「使いたいサービスである」と感じて頂けるかを小規模グループで検証しました。
• フェーズ3: 本格的なレコメンドアルゴリズムを実装し、クリック率やフィードバックがフェーズ2に比べてさらに向上することを確認しました。
――構想からリリースまで1年以上かかったと伺いました。スピード感が重視されるWeb業界ではかなり長い期間ですが、何にそこまで時間がかかったのでしょうか?
正直に言うと、その半分以上の期間は「製品になるかどうかも分からない」という研究開発(R&D)フェーズでした。
AI、特に生成AIを使ったプロジェクトは、世の中に巨万とありますが、その大半は「PoC(概念実証)」で終わってしまいます。「すごいのができたね」「面白いね」でおもちゃになって終わり。 我々が一番恐れていたのはそこです。
医療情報という、正確性が重視される領域で、確率的に動作する「不安定なAI」をどう扱うか。ここが重要だったと思います。
── 具体的に、どのような試行錯誤があったのですか?
「魔法」のような技術はありません。やったことは極めて泥臭い検証の繰り返しです。
最初のフェーズ(Phase 1)では、人間が書いた記事とAIが書いた記事を並べ、数百本単位で評価を行いました。 「この要約は医師にとってノイズが多い」「この表現は医学的に不正確だ」。 一つひとつの出力結果を見ながら、プロンプトを数文字単位で修正し、また数百件回して評価する。
「人間が書く記事に対して非劣性(劣っていないこと)」を証明できるまで、この地味なチューニングをひたすら繰り返しました。この「正解のないチューニング」の期間が、エンジニアとしては一番精神力が試される時期だったかもしれません。
── 医療情報のため、ハルシネーションは大きなリスクですが、どう折り合いをつけたのですか?
そこは本当に議論を重ねたポイントです。 技術的な結論として、「現時点のLLMで精度100%は原理的に不可能」です。どんなにチューニングしても、嘘をつくリスクはゼロにならない。
だからこそ、我々は「技術で解決する部分」と「プロダクト設計でカバーする部分」を明確に線引きする決断をしました。
具体的には、
- 診断や処方には使用せず、あくまで「情報の入り口(メディア)」として定義する
- AI生成であることを明記し、必ず「元論文へのリンク」を踏ませる導線を作る
といった形です。「AIは間違えるものである」という前提に立ち、ユーザー(医師)が最終確認するための動線をUI/UXとして組み込む。技術だけで押し切ろうとせず、この「割り切り」ができたことが、リリースまで辿り着けた最大の要因だと思います。
── 運用フェーズに入った今、その品質はどう維持しているのですか?
そこは自動化しました。人間がチェックし続ける運用は、エンジニアとして美しくないですから(笑)。
導入したのは「LLM-as-a-Judge」という手法です。 AIが出した回答を、別の「審査員AI」に評価させる仕組みです。これも一朝一夕でできたわけではありません。
例えば「Triple-negative breast cancer」という言葉があります。一般的に日本で使用される医療用語は「トリプルネガティブ乳がん」ですが、生成AIによっては「三重陰性乳がん」という表現を出力します。こうした医療特有の用語を審査員AIに正しく判定させるためにも、また膨大な試行錯誤と検証が必要でした。
現在では、モデルのバージョンアップ時に「新モデルの勝率」が自動算出されるパイプラインが動いています。
■組織と展望 求めるのは「現状を打破する意思」
── 今後、どのようなエンジニアに入社してほしいですか?
今後、開発ではAIとの協働が必須になってきます。エンジニアの仕事はコーディングから、AIをどう使いこなすか、そして価値のあるサービスをどう作っていくかという、より上流のレイヤーにシフトしていくでしょう。そういった自己改革に、一緒に取り組んでいける方と仕事がしたいと思っています。
現在、開発チーム内では、明確な役割分担は設けていません。「誰でもどの業務でもできるようにする」のが理想であり、フルスタックな動きを推奨しています。 実際、現在試験導入しているLINE連携機能は、チームメンバーからの「やりませんか」という提案で実装されたものです。
だからこそ、サービスの提供価値そのものに注目し、仕事の内容も方向性もより高みを目指したいと考えている方に来ていただきたいと思っています。
── 最後に、今後の展望をお願いします。
機能面では、新機能の実装や、スマートフォンアプリ化(来年予定)などを考えています。

■採用担当より
今回のインタビューから、技術だけでは解ききれない課題に向き合い続ける現場のリアルが伝わっていれば嬉しいです。
不確実性の高いAIを扱いながら、プロダクトとして成立させる。
このような挑戦に面白さを感じ、価値を届けることにこだわりたいエンジニアの方をお待ちしています。
最後まで読んでいただきありがとうございました!
弊社にご応募いただく方や興味を持っていただいている方の参考となれば幸いです。
▼ケアネットのテックブログはこちら▼
▼「CareNet Academia」の事例がAWS様のサイトで取り上げられました▼
株式会社ケアネット様の AWS 生成 AI 事例「医師向け情報サービスにおける大規模 AI ライティングシステムの実装」のご紹介
▼ケアネットについて興味を持った方はこちら▼
/assets/images/22678856/original/51c52971-82a1-4e96-93af-4ba6a4303bbc?1765424158)

/assets/images/22678856/original/51c52971-82a1-4e96-93af-4ba6a4303bbc?1765424158)

