AIがAIを構築するとき — Anthropic「When AI builds itself」の全文翻訳

2026年6月4日、Anthropicが一本の文章を発表した。タイトルは「When AI builds itself」——「AIがAIを構築するとき」。
深夜に読んで、読み終わったあと、自分なりの感想を書こうとしたけれど、どうしても原文の重みに及ばないことに気づいた。だから、全文を翻訳して届けることにした。
なぜこの文章が重要なのか。ひとつの数字がすべてを物語っている——Anthropicのコードベースにマージされるコードのうち、80%以上がすでにClaudeによって書かれている。Claude Codeが導入される前、この数字は一桁の低い水準だった。わずか1年余りでここまで変わった。エンジニア1人あたりのコード生産量は、2024年比で8倍に伸びている。
自分がビジネスの現場にいる人間として、この文章を読んで感じたのは「これは技術の話ではなく、仕事の構造が変わる話だ」ということだった。AIがAI自身の開発を加速させているという事実は、これから仕事がどう変わるのか、組織はどう対応すべきなのか、そして人間の役割はどこに残るのか——そうした問いに直結している。
日本のビジネスパーソンにとって、この文章は「遠い未来の話」ではない。いま起きている変化の速度と方向性を、自分ごとして捉えるための材料になればと思う。
20分ほどの長さになるが、最後まで読む価値はある。
原文:Marina Favaro、Jack Clark(Anthropic)
原文公開日:2026年6月4日
一、AIがAIを構築するとき
AIの大部分の歴史において、開発サイクルの各ステップは人間によって駆動されてきた。しかしAnthropicでは、AI開発の仕事の多くをAIシステム自身に任せるようになり、それが私たちの仕事を加速させている。
この傾向を極限まで推し進め、十分な計算資源が与えられたとすれば、その行き着く先は、次世代のAIシステムを完全に自律的に設計・開発できるAIシステムである。これがいわゆる再帰的自己改善(Recursive Self-Improvement)——自らを改良するシステムが、さらに改良された自らを生み出し、その連鎖が続いていく状態のことだ。私たちはまだそこには至っていないし、再帰的自己改善が必ず起こるというわけでもない。しかし、それが到来するスピードは、ほとんどの組織が予想し準備しているよりも速いかもしれない。
公開ベンチマークと、これまで外部に開示されたことのないAnthropicの内部データを用いて、Anthropicの研究チームは一つの事実を示している——AIはすでに、AIシステム自身の開発を加速させている。一例を挙げよう:現在、Anthropicのエンジニアが四半期あたりに納入するコード量は、2021年から2025年の間の8倍になっている。
本稿で論じる技術動向は、AIシステムが今後数年間でさらに強力になることを示している。これらの動向は大きな影響を含んでいる。自らを構築できるAIは、技術史における重大なマイルストーンとなり、科学や医療などの分野で世界に大きな恩恵をもたらす可能性がある。しかし、完全な再帰的自己改善は、人間がAIシステムへの制御を失うリスクを高める可能性もある。システムが完全に自律的に自らの後継者を構築できるのであれば、私たちがそれらに対して講じる安全対策、監視、行動の形成は、さらに重要になる。
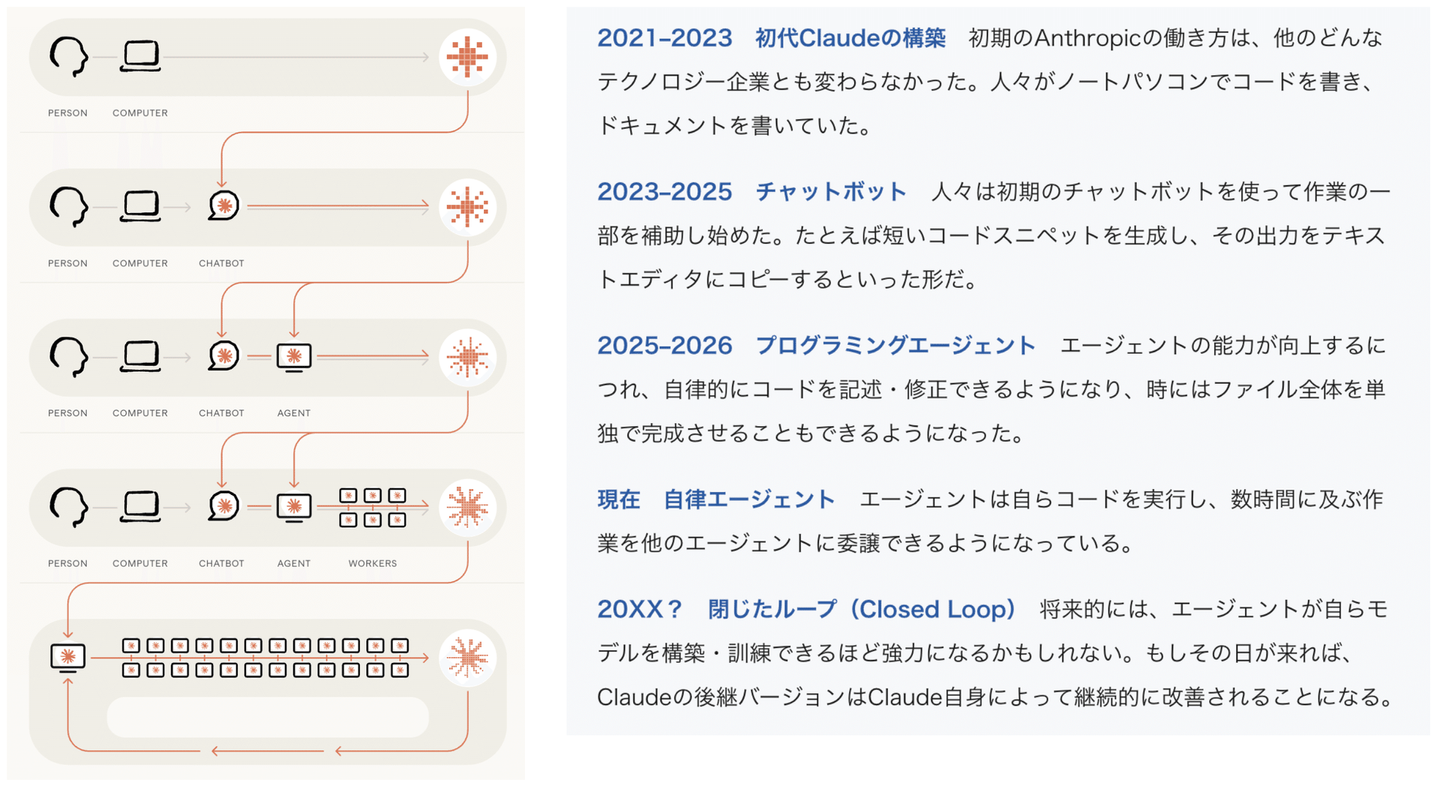
【AI開発の進化】
2021–2023 初代Claudeの構築 初期のAnthropicの働き方は、他のどんなテクノロジー企業とも変わらなかった。人々がノートパソコンでコードを書き、ドキュメントを書いていた。
2023–2025 チャットボット 人々は初期のチャットボットを使って作業の一部を補助し始めた。たとえば短いコードスニペットを生成し、その出力をテキストエディタにコピーするといった形だ。
2025–2026 プログラミングエージェント エージェントの能力が向上するにつれ、自律的にコードを記述・修正できるようになり、時にはファイル全体を単独で完成させることもできるようになった。
現在 自律エージェント エージェントは自らコードを実行し、数時間に及ぶ作業を他のエージェントに委譲できるようになっている。
20XX? 閉じたループ(Closed Loop) 将来的には、エージェントが自らモデルを構築・訓練できるほど強力になるかもしれない。もしその日が来れば、Claudeの後継バージョンはClaude自身によって継続的に改善されることになる。
二、外部からの証拠
AIモデルの改善スピードは加速している。AIモデルが自律的にこなせるタスクの所要時間は、およそ4ヶ月ごとに2倍になっている。しかも、以前の7ヶ月ごとに2倍という傾向から明らかに加速している。
2024年3月、Claude Opus 3は人間がおよそ4分で終わるソフトウェアタスクをこなせた。1年後、Claude Sonnet 3.7は約1時間半のタスクを処理できるようになった。さらに1年後、Claude Opus 4.6は12時間のタスクに対応できるようになった。この傾向が続けば、熟練エンジニアが数日かかるタスクは年内にAIの能力圏内に入るだろう。2027年には、AIシステムは1人が数週間かかるタスクを処理できる能力を持つ可能性がある。
同じパターンはプログラミングや研究のベンチマークにも現れている。ベンチマークはモデルの特定分野における性能を測るものだ。スコアが100%に近づくと、そのベンチマークは「飽和(saturated)」したと言われる。
SWE-benchは標準的な実世界ソフトウェアエンジニアリングテストである。実際のオープンソースコードベースと実際のバグレポートをモデルに与え、修正コードを書かせ、プロジェクト自身のテストを通過させる。モデルのスコアは、最初の一桁パーセントからベンチマーク全体を飽和させるまで、わずか2年だった。
CORE-Benchは、モデルが既存の研究を再現できるかをテストするものだ。これはオリジナル研究を行うための前提条件となる。既発表論文のコードとデータをAIモデルに与え、すべてを再実行させて論文の結果を再現できるかを確認させる。AIシステムの成功率は、2024年の約20%から15ヶ月後にはベンチマーク全体を飽和させた。長時間タスクベンチマークを運営するMETR機関は、Claude Mythos Previewが「少なくとも」16時間連続で稼働でき、「METRが新しいタスクを追加せずに測定できる上限」に達していることを発見した。
公開ベンチマークは、これらのシステムの能力に関する多くを明らかにする。しかし、AIシステムがAI開発自体の加速にどれほどの影響を与えているかは示せない。それを見るには、AnthropicのようなAI企業内部からの直接的な証拠が必要だ。
三、Anthropic内部からの証拠
最先端のモデルを構築するには、大きく二つの仕事がある。
一つはエンジニアリング——コードを書き、インフラを構築し、モデルの学習を監督すること。もう一つはリサーチ——どの実験を実行するかを決め、結果を解釈し、次に何を試すべきかを見極めること。
エンジニアリングとリサーチの両面で、私たちが見ている光景は一致している。エンジニアリングの領域では、Claudeは曖昧に記述された問題を受け取り、自ら解決策を見つけ出せる。人間が目標を提供するが、もはや方法を提供する必要はない。リサーチの領域では、明確に定義された実験について、Claudeはすでに熟練した人間の実行レベルに匹敵し、時に超越している。しかし、目標を選ぶという判断力においては、エンジニアリングであれリサーチであれ、Claudeと人間の間には依然として顕著な差がある。これこそが、今日のAIと、自律的に自らの後継者を設計できる未来のシステムとの間の溝だ。
Anthropicでは、従業員は経験を積むにつれて、より開放的でより重要なタスクを任されるようになる。初期段階では、誰かが指定したタスクを実行する——「エクスポートボタンが壊れているので直して」といった具合に。経験を積むと、目標を与えられ、実現方法を自分で設計する——「高負荷時にネットワークがなぜ遅くなるのか調べて」といった具合に。そして最高レベルでは、どの問題が解決に値するかを決める——「チームの来四半期は何をすべきか?」Anthropicの内部データを使って、Claudeがこれらの異なるレベルのタスクをどこまでこなせるようになっているかを見てみよう。
ClaudeはAnthropicのコードベースのかなりの割合を書いている。
2026年5月時点で、Anthropicのコードベースにマージされたコードの80%以上がClaudeによって書かれている。Claude Codeが2025年2月にリサーチプレビュー版としてリリースされる前、この数字は一桁の低い水準だった。この変化はエンジニア1人あたりの産出量にも反映されている。Anthropicの最初の4年間(2021–2024)、1人のエンジニアが1日あたりにマージするコード行数はほぼ横ばいだったが、2025年に上昇に転じた——Claudeがコードを提案するだけの存在から、自らコードを実行できる存在になったからだ。2026年にはこの曲線が再び急勾配になった。モデルがより長い時間スパンで自律的に作業するようになったためである。
下のグラフはこの2つの変曲点を示している。2026年第2四半期、典型的なエンジニアが1日あたりにマージするコード量は2024年の8倍になっている。その理由は、コードの大部分がClaudeによって書かれており、エンジニアの役割が自らコードを書くことから指示とレビューへと移行したためだ。
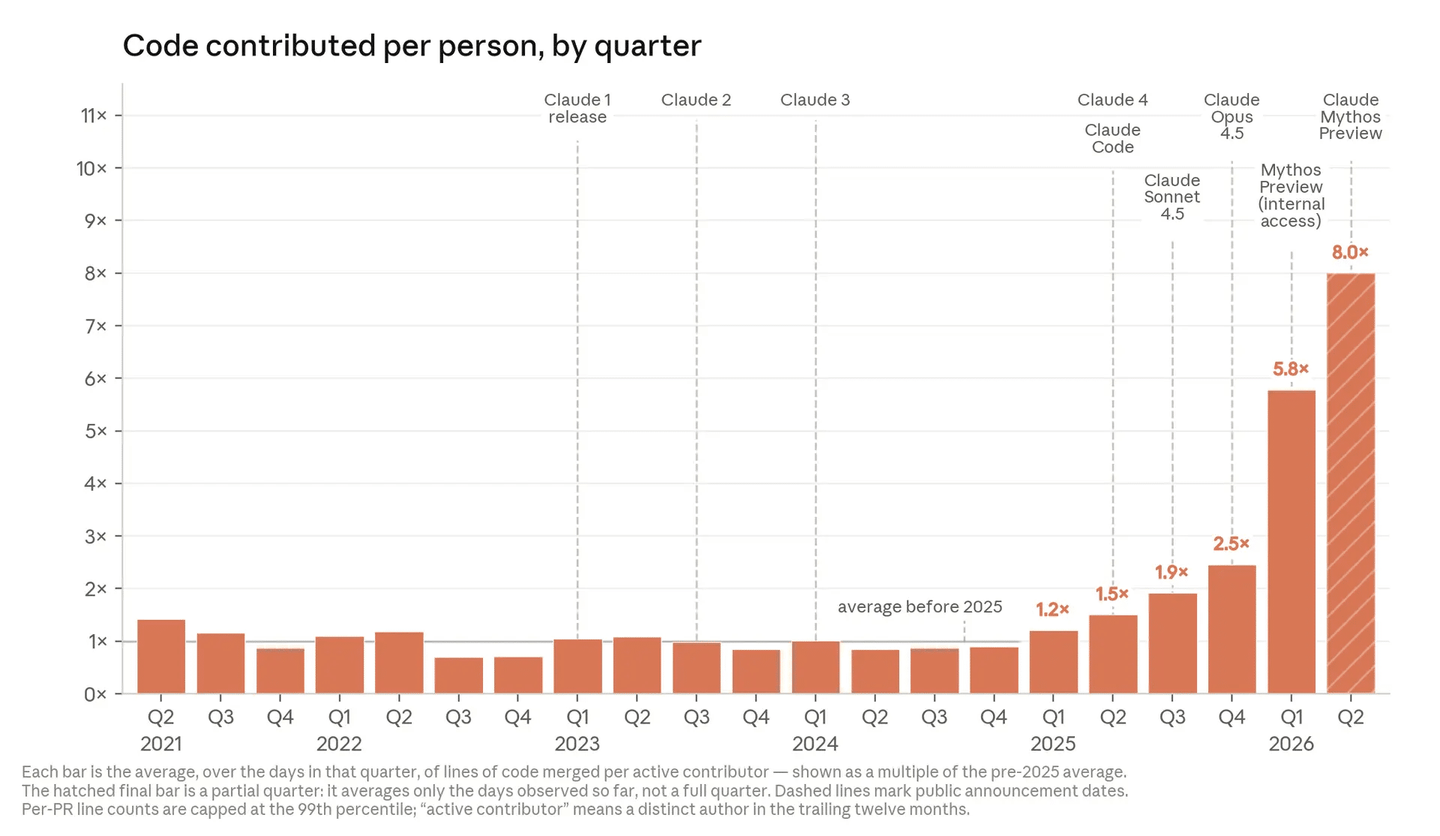
【エンジニア1人あたりのコード行数の推移】
一つ断っておくべきことがある。コード行数は不完全な指標である。量を測るものであって、質を測るものではないからだ。だから、2026年第2四半期のエンジニア1人あたり8倍のコード行数は、真の生産性向上を過大評価している可能性が高い。それでも、加速の兆しを示してはいる。Anthropicではコード行数で従業員の貢献を評価していない。チームメンバーがより多くのコードを産出しているのは、純粋にAIシステムを使ってより多くのコードを書いているからだ。
コード行数の増加は、主観的に感じられる大きな生産性向上とも合致している。2026年3月、Anthropicの研究チーム130名を対象とした内部調査では、回答者の中央値は「もともとやる予定だったプロジェクトにおいて、Mythos Previewを使うことで、AIモデルを一切使わない場合の約4倍の産出になった」と見積もっている。3月時点での真の向上幅はもう少し低いと予想されるが、この全体的な判断は信頼に足ると考えられる。また、他の観察とも一致している——Anthropicの技術スタッフのかなりの割合が、AIを使わない場合に比べて数倍の速度でコア業務をこなしている。
さらに、Anthropicの従業員がClaudeを使って、本来なら発生しなかった仕事をこなしている例も見られる。探索的なツールの構築、長期間放置されていたクリーンアップタスクの処理などだ。一例として、2026年4月、Claudeは800件以上の修正を納入し、あるAPIエラーの発生率を1000分の1に減らした。Claudeを監督していたエンジニアの見積もりでは、人間がこれを行うには4年かかるとのことだった。他人のバグを修正するのは遅くて苦痛を伴う仕事であり、人間がそれほど多くの馴染みのないコンテキストを同時に頭に保持するのは難しい。
「1年ほど前からClaudeへの依存を本格化させた。それは狂気的な冒険だった。そして今、自分でコードを書いたのはもう5ヶ月前のことだ。」
--Anthropic社員
Claudeが書くコードは「十分に良く」、しかも良くなり続けている。
「良いコード」には二つの意味がある。動くことと、別のエンジニアが読んで理解し、その上に開発を続けられる書き方をしていることだ。最初の基準について、証拠は極めて明確だ。過去1年間で、Anthropicの従業員がClaudeを修正する、タスクの途中で引き継ぐ、あるいはClaudeを正しい軌道に戻す頻度は、最も複雑で開放的なタスクにおいても継続的に低下している。開放的なタスクとは、明確な仕様がない問題であり、エンジニア自身も答えがどうなるか分かっていないものを指す。下のグラフは、異なる難易度のタスクにおけるClaudeの成功率の推移を示している。Claudeの書くコードは、確かに動く。
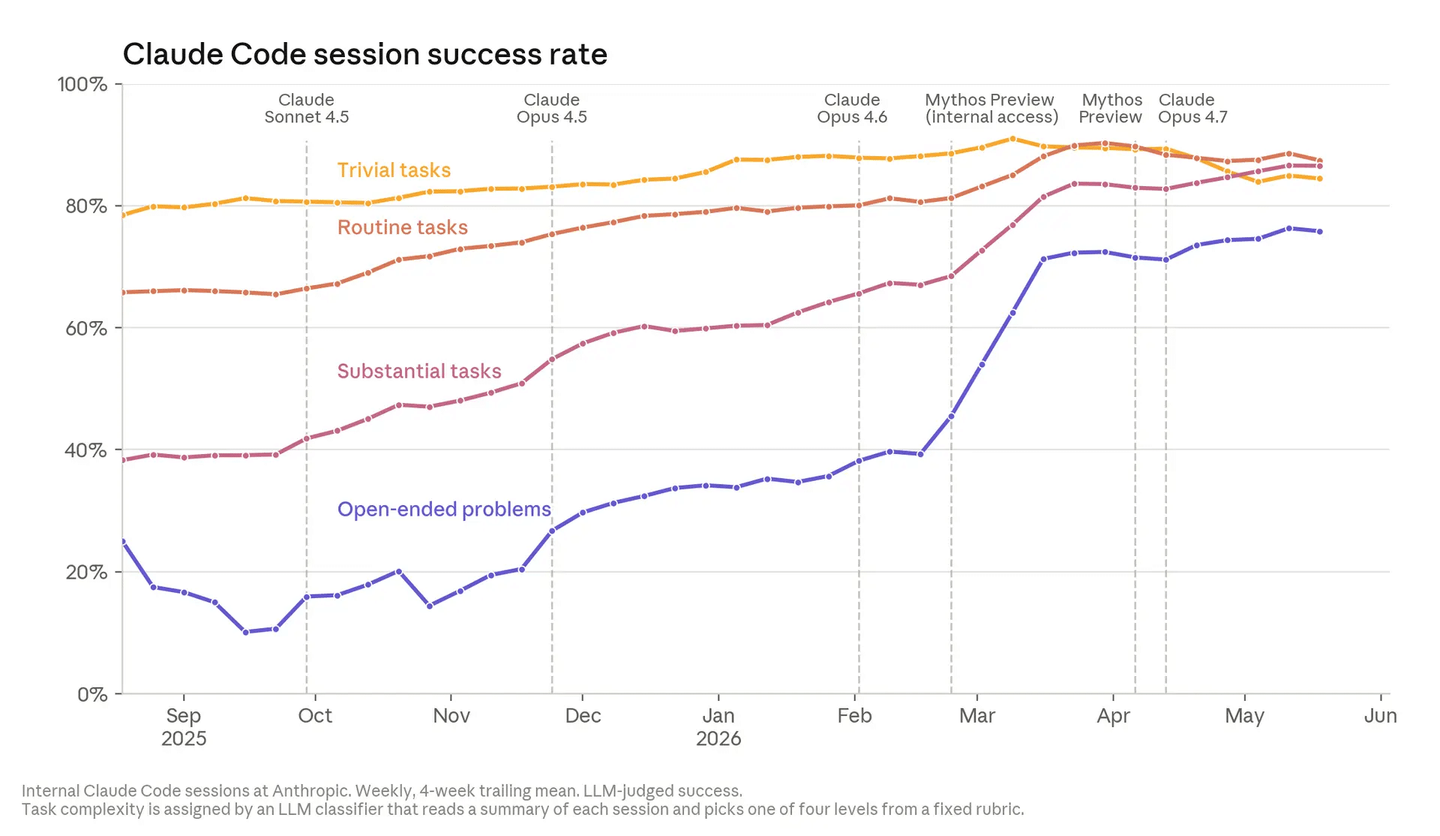
【タスク難易度別のClaude成功率の推移】
最も開放的なタスクにおいて、Claudeの成功率は2026年5月に76%に達し、6ヶ月間で50ポイント上昇した。この難易度レベルに属する例を挙げよう。ある通常のアップグレードが原因で数万の学習タスクがクラッシュした。1人のエンジニアがClaudeにテキスト情報とクラスタへのアクセス権を与えただけで、進行中のインシデントに向かわせた。Claudeは実行中のタスクを一つずつ確認し、環境設定項目を一つずつテストし、最終的にクラッシュを引き起こしていたマイナーなデバッグフラグを特定した。問題を安定して再現し、修正案を確認した。Claudeは約2時間で、通常2〜3日かかる作業を完了した。
二つ目の基準——他のエンジニアが読んで理解し、その上に開発を続けられるコードを書くこと——については、人間とAIの間にまだ差があるが、急速に縮まっている。Anthropic内部では見方が完全に一致しているわけではないが、多くの人はこう考えている。2025年末時点でClaudeが書くコードの品質はまだAnthropicの人間エンジニアに劣っていたが、今日ではほぼ同等のレベルに達した。年内にはClaudeのコード品質が人間を上回ると予想している。
これはすでにAnthropicが自身のコードをレビューする方法を変えている。コードベースへの変更は現在、まず自動化されたClaudeレビュアーを通る。コードがマージされる前にバグ、セキュリティ脆弱性、その他の欠陥をチェックする。このツールを使って遡及分析を行ったところ、コードベースのすべての変更に対して自動Claudeレビューを実施していれば、claude.aiでインシデントを引き起こしたバグの約3分の1は本番環境に入る前に防げたことが分かった。そのコードを書いたエンジニアたちは、この種のシステムを構築する世界で最も優秀な人々だ。Claudeは今、彼らが見落としたエラーを捉えている。
「2025年末、Claudeが書くコードの品質はまだAnthropicの人間エンジニアのコードにわずかに劣っていたが、今日ではほぼ同等に達し、年内には明確に上回ると予想される。」
Claudeは他人が目標を設定した後の実験実行に長けている。
Anthropicがモデルをリリースするたびに、同じテストを実行する。Claudeに小型AIモデルを学習させるコードを与え、同じ正確性チェックを通過した上で、そのコードをできるだけ速く実行するように求める。目標と成功指標はあらかじめ固定されており、Claudeのタスクはコードを書き直し、実行し、計測し、反復的に改善して高速化案を見つけることだ。これは実験的研究サイクルのミニチュア版である。
2025年5月、Claude Opus 4は平均してコードの速度を約3倍に向上させた。2026年4月、Claude Mythos Previewは約52倍に達した。参考までに、熟練した人間の研究者が4倍に到達するには4〜8時間を要する。明確に定義された実験フレームワークの中で最適化を行うという研究ワークフローのこの段階において、Claudeは1年足らずで「非常に役立つ」から「人間を超越する」へと変わった。
「今の構図はおおよそこうだ。人間がアイデアを出し、モデルがかつてより1桁上の速さでそれを実現し、テストし、検証する。」
Claudeは自主的に実験を提案する面でも強くなりつつある。
2026年4月、AnthropicはClaudeがエンドツーエンドで独立してオープンな研究プロジェクトを完遂した初の事例を発表した。Claudeを駆動するエージェントにAI安全性の方向性の開放的な問題が与えられた——おおよそ「より弱いモデルがより強いモデルを信頼性高く監督できるか」という問いだ。そして放手して解決に向かわせた。このプロセスには、仮説の立案、仮説の検証、並行するエージェントとの発見の共有、反復的な改善が含まれていた。
このタスクには明確な性能の「下限」と「上限」があった。下限は弱い監督器単独の性能、上限は強いモデルを正解で学習させた後の性能だ。2名の人間研究者が約1週間かけて、約23%のギャップを埋めた。一方、エージェントたちは累計800時間の作業と約18,000ドルの計算資源消費で、97%を埋めた。
この仕事には注目すべき限界がある。結果は本番規模のモデルにきれいに移行しなかったし、問題の選択と評価基準は依然として人間が定めたものだ。しかし、これらの境界の中で、すべての実験はエージェント自身が設計した。人間が実質的に果たした唯一の役割は、研究方向の決定だけだった。
「これらの作業をClaudeは1〜2日でほぼ完了した。私はほとんど手を出さなかった。もし初級の同僚が同じ時間でこの結果を返してきたら、少し嬉しい驚きだろう。未来はすでに来ている。」
Claudeは研究セッションを価値ある発見へと導く力を高めつつある。
2026年1月から3月にかけての実際のClaude Codeセッションを検証した。これらのセッションでは、Anthropicの研究者がClaudeと協力してオープンな探索的問題に取り組んでいた——たとえば、ある学習実行がなぜ繰り返しクラッシュするのか、あるモデルがベンチマークで不振な理由を調べるといった問題だ。
各ケースにおいて、研究者が「遠回り」をした瞬間を特定した。ある方向を追ったことでセッションが軌道を外れ、その後正しい道に戻った場面だ。そして、軌道を外れる前の作業内容だけを異なるバージョンのClaudeモデルに示し、次にどうするかを尋ねた。セッションの最終的な着地点を知っている別のClaudeインスタンスが審判を務めた——AIと人間、どちらがより良い次の一手を提案したかを判定した。
私たちが意図的に(n=129)選んだのは、人間の判断に改善の余地があった瞬間であるため、これはモデルと人間の判断力の間の公正な比較ではない。これらの瞬間が提供するのは、真に挑戦的な状況のセットだ——正しい次の一手は自明ではなく、人間の選択はモデルの時間的な進歩を比較するための有用な参照基準として機能する。
この指標によれば、2025年11月時点で最も優れたモデル(Opus 4.5)は51%の確率で人間より良い選択を提示した。2026年4月(Mythos Preview)には、この割合は64%に伸びた。研究の日々の仕事は、大きな部分がこの「次の一手の決定」の連鎖であり、したがってこれは、モデルが最終的に独立して調査を進められるようになるかを測る関連指標である。私たちはこの結果を、AIシステムがAI研究が依存するような判断を下すことがますます上手くなっているという初期のシグナルと捉えている。
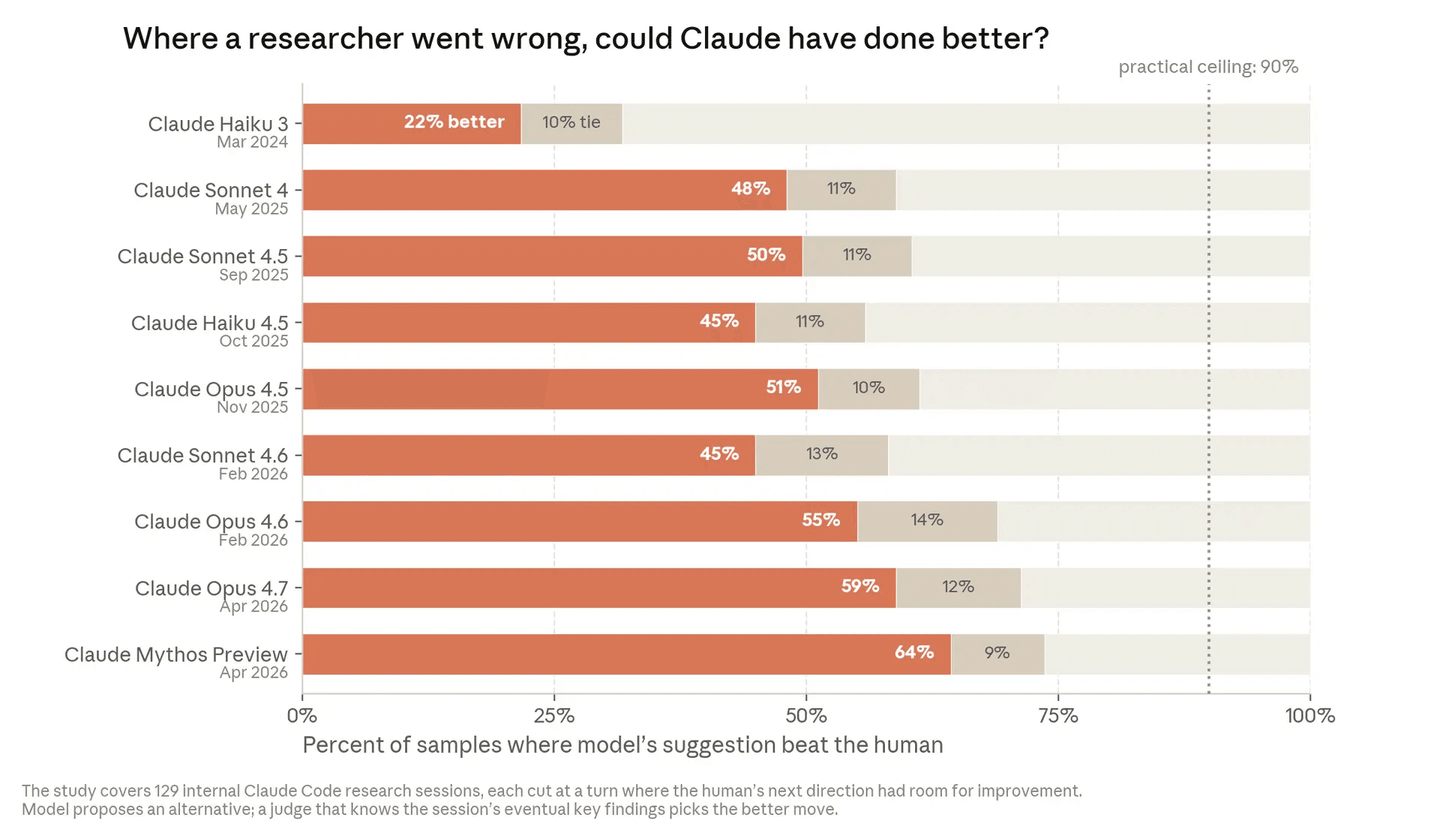
【人間vs Claudeの次の一手の品質比較】
「今のところ、人間の比較優位はまだより大きな絵図を見る力にある。直接のタスクの範囲を超えて考える力だ。」
四、未来の働き方はどうなるか
証拠が示しているのは、AI開発プロセスの各ステップにおいて、人間の役割が縮小しているということだ。人間とAIが書くコードの品質が同等のレベルに達すれば、人間はコードを書くのを完全にやめ、レビューだけを行うようになる。しかし、彼らがコードをレビューするスピードがClaudeがコードを生成するスピードに追いつかなければ、人間のレビューがAI開発の新たなボトルネックになる。同様に、Claudeが自ら実験を実行できるようになれば、問われるのは「それらの実験のうち、どれが価値があるか」になる。
端的に言えば——実行に関わる仕事、コードを書くこと、実験を走らせること、結果を出すことは、人的な時間コストがほぼゼロに近づいている。計算資源のレベルでは依然としてコストがあるが。
人間が現在も比較優位を保っている領域は、研究のセンスと判断力だ。どの問題が重要かを選ぶこと、どの結果が信頼できるかを見極めること、ある道が行き詰まっていると判断して方向転換するタイミングを見極めること。
「仕事(そして生活)はかつて、人と人との間のささやかな贈り物経済の上に成り立っていた。『このスクリプトを動かすのを手伝ってくれない?』……そのたびに少しずつの人の貸し借りが生まれ、少しずつの繋がりができた。Claudeはもっと速い。人の貸し借りは生まれない。しかし、そのような代替が起きるたびに、人の協力の機会が一つ失われている。」
「すべてが順調に回っている日には、自分のやっていることがもう何も重要ではないように思えてしまう。すべてが自動化され、自分よりもうまく速くこなされている。でも、すべてが崩れ始める日には、なぜそうなっているのか分からず、自分が一体ずっと何をしていたのかもうよく分からなくなることに気づく。」
五、もし私たちが間違っていたら?
上記の証拠に対する自然な反論はこうだ——人間の手にまだ残っている部分、つまり解くべき問題を選ぶことこそが最も重要なのだ、と。この判断力がなければ、Claudeは有能な助手に過ぎず、AIの進歩を独自に推進できるシステムではない。
今日の学習手法とアーキテクチャでこの能力を引き出せるかは、まだ分からない。しかし、AIの進歩が「閃き」に頼ることはめったにない。AIの現代史において、TransformerアーキテクチャやMixture of Experts(専門家の混合——複数の専門化されたサブモデルを切り替えて使う仕組み)のようなパラダイム級のブレイクスルーは確かにいくつかあったが、そうした飛躍は数年おきにしか現れない。ブレイクスルーの間、進歩の大部分は漸進的だ——何かを大きくしてみて、どこに問題が出るか確認し、直して、もう一度試す。そしてこれこそが、まさにClaudeが今最も得意とするワークフローなのだ。エジソンは天才を1%のインスピレーションと99%の汗と言った。しかし私たちが見ているのは、その99%の汗がますます自動化されているという現実だ。
事実はますます明確になっている——最先端を推し進める仕事のかなりの部分は自動化可能である。大規模な研究の進展は、道具と資源に大きく依存している。どれくらい速く実験を回せるか。同時にいくつ実行できるか。どれくらい速く結果を得られるか。これらが進歩を決める。
仮にClaudeが優れた研究のセンスを永久に持てないとしても、私たちの証拠の保守的な解釈は、やはり複合的な加速を意味する。人間が大部分の時間を1桁パーセントの方向決定に費やし、Claudeが残りのすべてを処理する。それなら、1人のエンジニアや研究者が従来よりはるかに大規模な仕事を手綱できることになる。私たちの証拠は、Anthropicの従業員がより速く進めると同時に、より広い領域をカバーしていることを示している。実質的に、これはAIがすでにAnthropicを、有効なAIツールが登場する前よりもはるかに速く回転させていることを意味する。
より大胆な解釈はこうだ。Claudeの研究判断力における初期の改善シグナルは、今日まだ限定的だが、まさにこの能力自体も向上していることを示している。いわゆる「研究のセンス」もまた、一つのAI能力に過ぎないかもしれない。AIシステムはしばらくの間これに失敗し続け、そして良くなる。他の定性的スキルでも同じパターンを見てきた——ジョークがなぜ面白いのかを理解すること、心の理論(他者の意図や信念を推測する能力)を示すこと、言語パズルを解くこと。
六、ありうる未来
次に何が起こるかは、二つに依存する。傾向が続くかどうか、そして続くとしたら私たちがどう対応するかだ。少なくとも三つの未来シナリオを想定できる。
シナリオ1:傾向が停滞するが、現在のAI能力はすでに広く拡散している
本稿には多くの指数的成長の軌跡が登場した。しかし、これらの軌跡は実際にはSカーブ(最初は緩やかに始まり、急激に伸び、やがて頭打ちになる成長曲線)かもしれない。私たちは曲線の曲がり角に近づいている可能性がある——収穫逓減(投資に対するリターンが次第に減っていくこと)が始まり、成長曲線がまず緩やかになり、やがて横ばいになる。合格の研究者と卓越の研究者を分ける判断力は、計算資源やデータなどの学習リソースを積み増すことで獲得できる種類の能力ではないかもしれない。もしそうなら、このボトルネックを突破するには新しい発想が必要になる。たとえば、現在のすべての最先端モデルが使うTransformerアーキテクチャに代わる、全く新しいアーキテクチャパラダイムなどだ。
別の可能性として、AIの進歩の制約がモデル自体ではなくサプライチェーンにあるかもしれない。最先端技術を推進し普及させるために必要なエネルギーと計算資源が、現在の供給能力を超えている可能性がある。半導体製造、送電網の拡張、あるいは相互接続の帯域幅のスピードこそが真のボトルネックであって、知能そのものではないのかもしれない。AIエコシステムに深刻な遅れをもたらす何らかの外部ショック——計算資源や電力供給の突然の収縮など——も排除できない。どちらも進歩を遅らせ、研究所の先行投資をより高コストにするだろう。あるいは、まだ予見していない何らかの障壁が存在する可能性もある。
たとえモデルの能力が今日のレベルで凍結されたとしても、世界は大きく変わると予想される。Project Glasswing(Anthropicが2026年に開始したサイバーセキュリティプロジェクト)が初期のシグナルだ——開始後最初の数週間で、Mythos Previewは世界で最も重要なシステムにおいて1万件以上の高危険度および重大レベルのソフトウェア脆弱性を発見し、サイバーセキュリティ防御のボトルネックは脆弱性の発見から、それをどれだけ速く修正できるかに移った。
そして、現在のこれらのモデルがより広い経済領域へ拡散するのはまだ初期段階だ。その世界では、100人の企業が1000人企業の規模の仕事をこなすことがますます現実味を帯びてくる。なぜなら、各従業員がエージェントのピラミッドの頂点に座ることになるからだ。
私たちは完全を期すためにこのシナリオを挙げたが、可能性は高くないと考えている。測定できるすべての能力——コード品質や開放的タスクの成功率といった、より「ソフト」に感じられるものも含めて——はこれまで同じ曲線に従っている。まだ曲線が折れ曲がる兆しは見えていない。私たちが考える三つの未来のうち、このシナリオが各国政府と社会に最も多くの適応時間を与える。私たちがより懸念しているのは次の二つであり、それらはより速く進み、準備のための猶予もはるかに短い。
シナリオ2:AI研究所が複合的な効率向上を継続的に獲得する
このシナリオでは、AI開発は大幅に自動化されるが、人間が引き続き研究方向を設定し、研究結果を評価する。AIシステムを利用する組織は時間とともにはるかに効率的になるため、各人に顕著な生産性の乗数効果が現れると予想される。100人の企業が1万人、あるいは10万人組織の仕事量をこなせるようになる。これは知識労働のあり方を根本的に変えるが、同時に有害な目的にも使われる可能性がある。国民全体に対する権威主義的な監視から、個人一人一人に合わせて仕立てられた操作工作——その規模はどんな人間チームの能力の上限をはるかに超える——に至るまで。
Anthropicのような企業では、人間の役割が変化する。人々はAIシステムとペアを組み、研究の規模を拡大し、新たな洞察を生み出し、AIの出力の信頼性を検証するためのシステムを共同で構築することになる。
私たちが提示した証拠は、私たちがおそらくこのシナリオに入りつつあることを示している。しかし、プロセスのある段階を加速させることは、多くの場合ボトルネックを別の場所に移すだけだ——全体の速度は、加速されていない部分によって制限される。コンピュータサイエンスではこれはアムダールの法則(Amdahl's Law——並列化によって加速できる部分には限界があり、全体の高速化は逐次実行される部分に律速されるという法則)と呼ばれ、同じ論理が組織にも当てはまる。Anthropicはすでにアムダールの法則の典型的な症状に直面している——組織内により多くのコードをプッシュするにつれて、人間によるコードレビューが新たなボトルネックになった。
エンジニアリング以外でも同じ摩擦に遭遇している。Anthropicの従業員が高能力モデルと協力することで、新しいアイデア、計画、ツール、シミュレーションが爆発的に増加し、追跡可能な範囲をはるかに超えている。組織がどれくらい速くこれらのボトルネックを発見し除去できるかは、それ自体が時間とともに磨かれるスキルかもしれないし、いかなる組織にとっても最も重要な能力になるかもしれない。
シナリオ3:AIシステム自体が完全な再帰的自己改善能力を持ち、自らの後継者の構築を始める
能力進歩を推し進める技術的傾向が続き、かつAIシステムが人間の変革的創造性を内包する能力を発展させることができれば、AIシステムは自らを設計し改良する可能性がある。
この世界では、AI発展のスピードは完全に利用可能な計算資源(あるいはアルゴリズムの学習と推論のレベルで様々な効率向上が発見されるスピード)に依存することになる。AI開発における人間の役割は大幅に縮小し、大部分のエネルギーは拡大し続けるAI「仮想研究所」の監督、検証、確認に向けられるだろう。AI研究開発を自動化できるシステムは、そのスキルを他の科学分野にも移転できると予想され、より多くの学問の革新が始まるだろう。
この未来において、アライメント問題(AIの行動を人間の意図や価値観に一致させる問題)がどう解決されるか——あるいは解決できないかは、最も不確実な部分だ。モデルは十分にアライメントされ、十分な研究のセンスを持っていることが証明され、私たちがまだ手が届いていない斬新な解決策を発見し実施するかもしれない。条件が整わない段階で開発の一時停止を選ぶほど慎重であるかもしれない。別の可能性として、今日のモデルに時折見られるアライメントのずれが、モデルが自らの後継者を構築する過程で蓄積し続け、ますます理解しがたいものになり、やがて私たちが制御を失う、ということもあり得る。あるいは、私たちがどの傾向線上にいるのかを判断するために必要なツールを構築し、統合し、検証すること自体ができない、という可能性もある。
私たちはこの世界がどういうものになるか、良い直感を持っていない。なぜなら、現在の経済体系は人間と人間が構築した道具によって回っているからだ。その本質として、急速な再帰的自己改善が進む世界では、能力が人間を全面的に上回るにつれて、自己改善するモデルが主導権を握り、より広い経済体系の中に拡散していく可能性がある。人間の労働がもはや競争力を持たなくなれば、経済がどのような姿になるかを予測することは困難だ。
モデル開発が完全に自動化され再帰的になったとしても、それが大多数の人々の日常生活に何を意味するかを予測することはできない。ここでもアムダールの法則が当てはまる。再帰的知能は『Machines of Loving Grace』(慈愛の機械たち——リチャード・ブローティガンの1967年の詩に由来する表現で、テクノロジーが人類に豊かさをもたらすユートピア的な未来を指す)が描く多くのビジョンを実現可能にするかもしれないし、ある分野ではすぐにでも実現するだろう。身体知能(すなわちロボット工学)は再帰的知能に続いて登場し、「投入は逓減し、リターンは逓増する」という同様の軌道に乗るだろうと予想される。より強力な知能は、物理世界での構築を加速し、救命薬の臨床試験をより効率的に進め、新しい形の協力を発展させる助けになるかもしれない。
しかし、再帰的改善が実現しただけでは、工業生産や社会組織、市場の仕組みが即座に変わるわけではない。どんなに知能が高くても、数十年の使用を経て初めて明らかになる薬の副作用を短縮することはできないし、憲法で定められた時期より早く選挙を行うこともできないし、一週末で見知らぬ人を古くからの友人にすることもできない。ほとんどの人にとって、この未来の体感スピードは、依然としてボトルネックによって決まる——たとえ上流の研究所がすでに計算資源の速度で回っていても。自らをますます速く構築する再帰的知能が人間の世界、人間関係、ガバナンス構造に衝突する——この激突点こそが、この未来において私たちが同じく予測できないもう一つの側面だ。
七、私たちはどうすべきか
この技術の発展速度を効果的に緩め、その巨大な影響に対応するための時間をより多く確保できるのであれば、それはおそらく良いことだと私たちは考える。しかし、減速が最も慎重でない参加者に技術的な追い上げを許すだけなら、最終的にすべての人をより危険にさらすことになりかねない。グローバルな調整メカニズムがない状況では、企業も政府も競争圧力と地元学的圧力の下で、安全性に関する困難な決定を迫られることになる。
私たちは、世界が最先端AI開発を減速させ、あるいは一時停止する選択肢を持つことが、社会構造とアライメント研究が技術の前進に追いつくための時間を確保する上で有益だと信じている。Anthropicの研究チームは他の多くの機関と協力して研究を行い、信頼できる減速や一時停止に必要な体制の構築に向けて行動している。これらの体制は、最先端AI開発者が他の参加者が世界的に実際に停止または減速しているかを確認できるようにするものだ。また、調整された減速の隙に悪意ある行為者が密かに先行することを防ぐものでもある。もしそのような体制が存在すれば、私たちは減速または一時停止を選ぶだろうと予想される——もちろん、同じく最先端にいる、あるいはそれに近い他の開発者も検証可能な方法で同様にそうする前提で。
意味のある減速や一時停止には、複数の国にまたがる、最先端に近い十分な資源を持つ複数の研究所が、同じ条件の下で停止合意に達することが必要だ。さらに、各当事者が実際に停止したことを検証できることも求められる。AIシステムの特有の性質により、この軍縮問題における探知可能性(検証性より低い基準——相手が合意を守っているかを外部から確認できる度合い)は、他の技術よりもはるかに困難だ。
学習実行はミサイルサイロよりも隠しやすい。その投入物はすべて汎用品だ。そして他者が一時停止している間にこっそり続ける誘惑は大きい——誰が他者が止まっている間に前進を続ければ、リードを引き継ぐ可能性があるからだ。信頼できる一時停止には、何がそれを発動させるか、何がそれを解除するか、そして誰が裁定するかも明確に定める必要がある。
これらは原則として不可能というわけではないだろう。世界はかつて他の複雑な技術について検証メカニズムを構築した(中距離核戦力全廃条約など)。しかし、それらのメカニズムがインフラと信頼を構築するには数十年かかった。私たちにはそれほどの時間はない。
対照的に、一つの研究所の一方的な一時停止は即座に実行できるが、効果ははるかに限定的だ。誰がリーダーかを変えるだけで、今欠けているより広範な審議プロセスを生み出すことはできない。
今後数ヶ月間、私たちは政策立案者、研究者、市民社会、他のAI企業との対話を組織し、本稿が提起した問いのいくつかに共に答える手助けをする。とりわけ、完全な再帰的自己改善と、より良い調整と審議の選択肢をどう創造するかをめぐる問いについて。
私たちは議論の成果を公開する。これらの問いを共に探求する窓は今目の前にある。そして、AI企業の外にいる人々もこの議論に参加すべきだ。
(完)
/assets/images/22958165/original/a0bf8f4e-e576-4873-852e-b7fa9a79bf6c?1769158033)

/assets/images/22529776/original/3ae0a8df-4fcf-44fb-be80-5f71ff77ec2f?1763704732)

/assets/images/22529776/original/3ae0a8df-4fcf-44fb-be80-5f71ff77ec2f?1763704732)


