
みなさん初めまして。
TDAI Labでデータサイエンティストをやっている野田です。
今回は弊社で新しく公開したモジュールWise-Coop🤝について解説していこうと思います。(GitHubはこちら)
背景と目的
AIモデルの性能面での成長は著しい一方、社会実装という観点ではまだまだと言えます。理由として、『AIの精度90%では実用に耐えきれない、99.9%でやっと』といった業務上の問題が挙げられます。
しかし、AIモデルが『この予測はきっと正しいから信じてもらっていいよ、だけどこれは僕にも自信がないから人間さんに判断して欲しい』と言えたら、AIと人間の協業により精度99.9%も夢ではないかもしれません。
そこでAI予測の不完全さを人間が補うことを念頭におき、その協力割合を最適化するフレームワークをこの度Wise-Coopという名前で公開しました。
イメージとしては以下のようなイメージです。人とAIが協力することにより、全て人がやる場合よりも少ない人的稼働で、全てAIがやる場合よりも高い精度を出すことができます
(分類フェーズにおける人的稼働を考えており、分類結果に対して除去/修正などをするフェーズは別物として考えています)
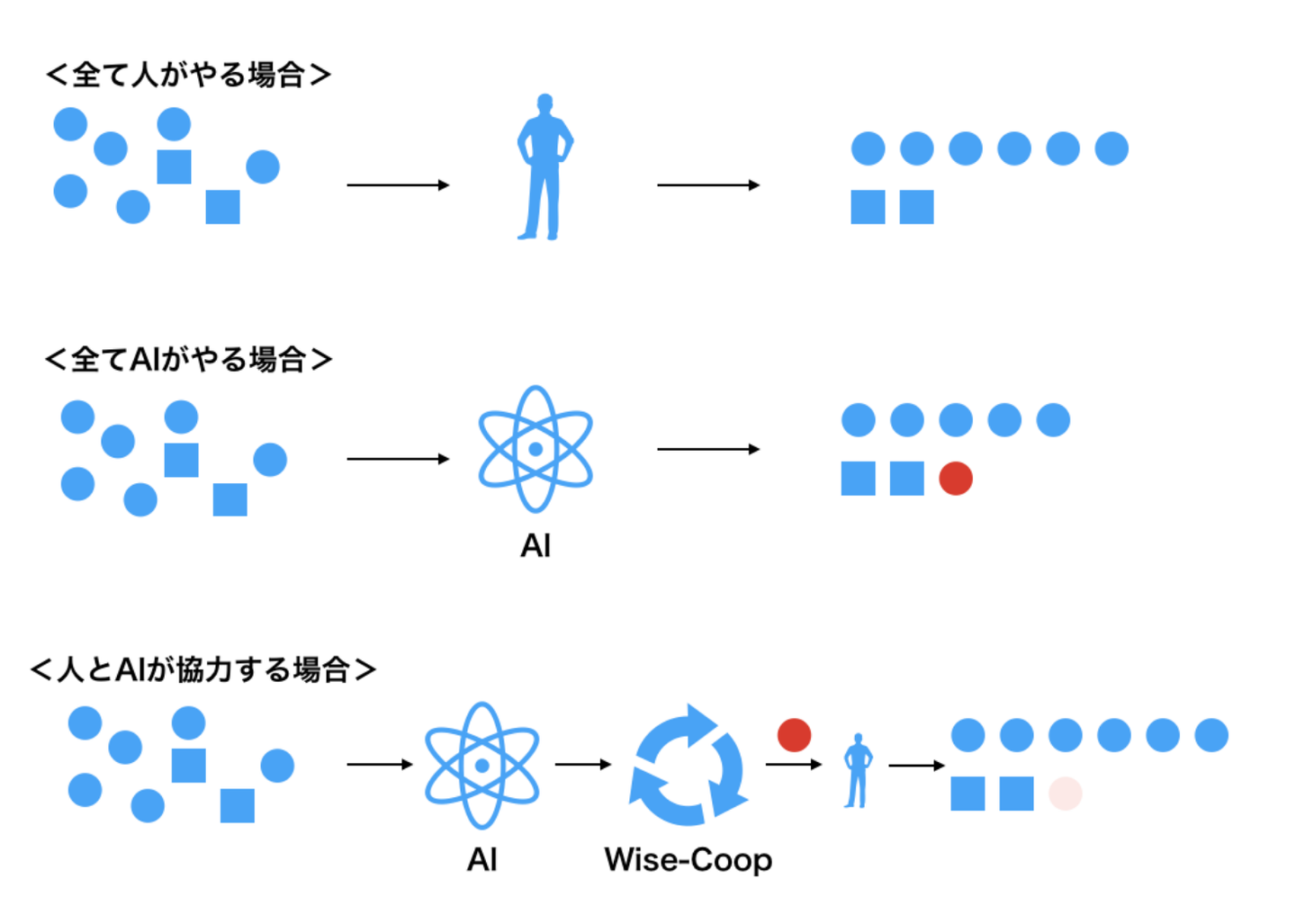
予測データの一部を人がチェックして修正するケース
まずはシンプルな二値分類タスクについて考えます。既に予測モデルによって、全テストデータについて値域が[0,1]のクラスへの寄与確率が得られているものとします。
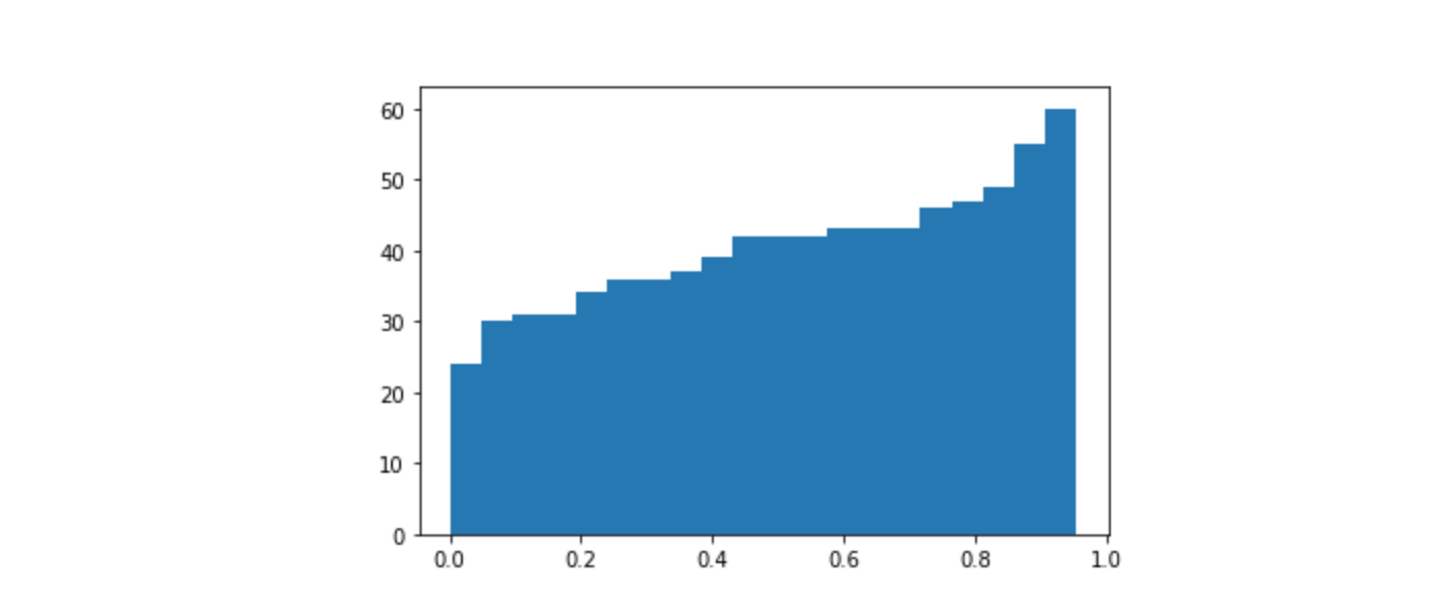
通常は0.5といった閾値で分けて予測ラベルが求められるわけですが、全データの20%だけは人がチェックして正解が判別できるならばどうでしょうか。寄与確率が0.9や0.2であるようなデータは予測の外れる可能性が低いのに対し、0.4のような微妙なデータはどちらの予測ラベルを立てても間違える危険が大きいです。上の累積分布関数でいうと、[0.4, 0.7]といった区間を人に任せるのが賢明そうです。
しかし、どの部分を人がチェックすべきかは問題設定によって変化します。
例えば弊社はこれまで、以下のようなリクエストをいただいたことがあります。
- 異常検知で、多少過検出は多くても良いから、絶対に異常を見逃して欲しくない。
- ツイート分類で、ちょっとでもネガティブな可能性がある内容ならばアラートを鳴らして欲しい
すると「偽陽性は多少あっても構わないが偽陰性を減らしたい」という場合、つまり間違えたときのペナルティーが均一ではないとき、人がチェックをする区間は左側、予測確率の小さい方向にシフトします。「0.3と予測されているが本当は1かもしれない」といったデータを見つけたいからです。
期待ペナルティの定式化
また、二値分類ではなくマルチクラス分類を考えると、上のような単純なグラフでは表しにくくなります。上記を踏まえて人にチェックしてもらう優先度を考えると、以下のように定式化できます。
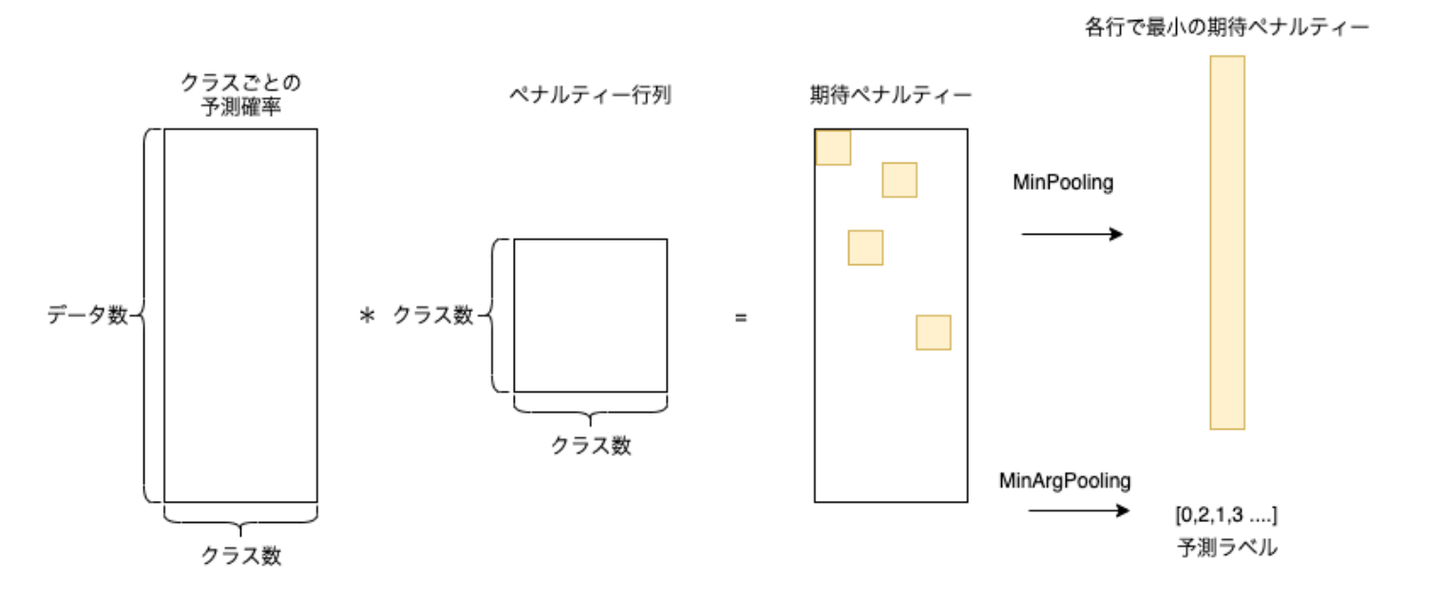
入力
- クラスごとの予測確率:これは分類タスク(nクラス分類とする)の機械学習をした時に出力される(データ数, クラス数n)の行列です。2値分類の際は一次元配列となるかもしれませんが、そのまま入力して問題ありません(内部でクラス0の列が生成されます)。
- ペナルティー行列:ここがわかりにくいかなと思います。これは(クラス数n, クラス数n)の行列で、ペナルティー行列[i, j]の値は真のクラスがiのものをクラスjと予測した際に課す重みを意味します。基本は対角成分を0に、他を1とした行列を与えれば大丈夫です。これに手を加えるのは、例えば真のクラスがiのものをクラスjと予測するミスは避けたい場合などです。この場合はその部分のペナルティーを高くします。逆に予測ミスがあっても良い場合はペナルティーを下げることもできます。
出力
- 予測ラベル:予測確率行列とペナルティー行列の積をとることで予測クラスごとの**期待ペナルティー(そのクラスを選んだときに生じるペナルティーの期待値)**が計算されるので、その中でペナルティーが最小となるようなクラスを予測結果として出力します。
- 期待ペナルティー:予測ラベルを出した時のペナルティーの期待値(各行の最小値)が出力されます。期待ペナルティが大きいことは、人のチェックをうける優先度が高いことを意味します。つまりこの値の大きい順に人がチェックしていけば全体のペナルティーが最も効率よく最小化される、つまり人の稼働を抑えつつ精度を上げていくことができます。
例えばペナルティー行列、予測確率行列をそれぞれ
penalty = np.array([[0,1,1],
[1,0,1],
[1,1,0]])
probability = np.array([[0.05,0.15,0.8],
[0.3,0.33,0.37],
[0.09,0.8,0.11]])
とします。
この時期待ペナルティーは
[[0.95 0.85 0.2 ]
[0.7 0.67 0.63]
[0.91 0.2 0.89]]
となります。予測クラスは各行(サンプル)で最小のペナルティーとなる列(クラス)となるので
[2 2 1]
となり、その時の期待ペナルティーは
[0.2 0.63 0.2]
となります。
つまり期待ペナルティーの高い、2つ目のサンプルを優先して見れば良いということになります。実際、予測確率行列を見ると2つ目のサンプルでは確率が均衡しているので、予測精度が悪いものだとわかります。
Wise-Coopを動かしてみる
では今度はモジュールを動かしながら、使い方を細かくみていきましょう。
まず、pipからモジュールをインストールします。
pip install wisecoop
ここではscikit-learnのデータセットからirisのデータセットを読み込み、ロジスティック回帰で分類タスクを行った予測結果を用いることにします。ここでは3値分類タスクを行っています。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
iris = datasets.load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.4, random_state=21)
model = LogisticRegression()
model.fit(X_train, y_train)
# make prediction (None, n_classes)
y_pred_proba = model.predict_proba(X_test)
そしてCooperanteクラスをインポートし、クラスオブジェクトを作ります。
引数にはペナルティー行列を入れます。まずは一番平坦なペナルティー行列(対角成分が0、他は全て1)を与えた場合で考えてみましょう。
from wisecoop import Cooperante
# prepare penalty array
penalty_array = np.array([[0, 1, 1],
[1, 0, 1],
[1, 1, 0]])
# Instantiation
coop = Cooperante(penalty_array)
次に予測確率行列をフィッティングします。
# Fitting
penalty_min, pred = coop.fit(y_pred_proba)
以上でフィッティングは終了です。しかしここで終わりではなく、実際にペナルティーが高い順に人がチェックしてどのように精度が上がっていくのかを視覚化する機能もあります。
plot_evalメソッドに正解クラスを引数として与えることで評価スコアを縦軸、人の稼働度合いを横軸としてプロットできます。ここではリコールを評価指標としてみます。またスコアはクラスごとに計算される(accuracyを除く)ため参照したいクラスをclass_refで指定します。sampling_rateは人の稼働を何%刻みで計算させるかを指定しています。これはデフォルトで0.01(=1%刻み)となっているため基本は設定しなくても大丈夫です。
# Visualization
fig, ax = coop.plot_eval(y_test, metrics='recall_score', class_ref = 1, sampling_rate=0.01)
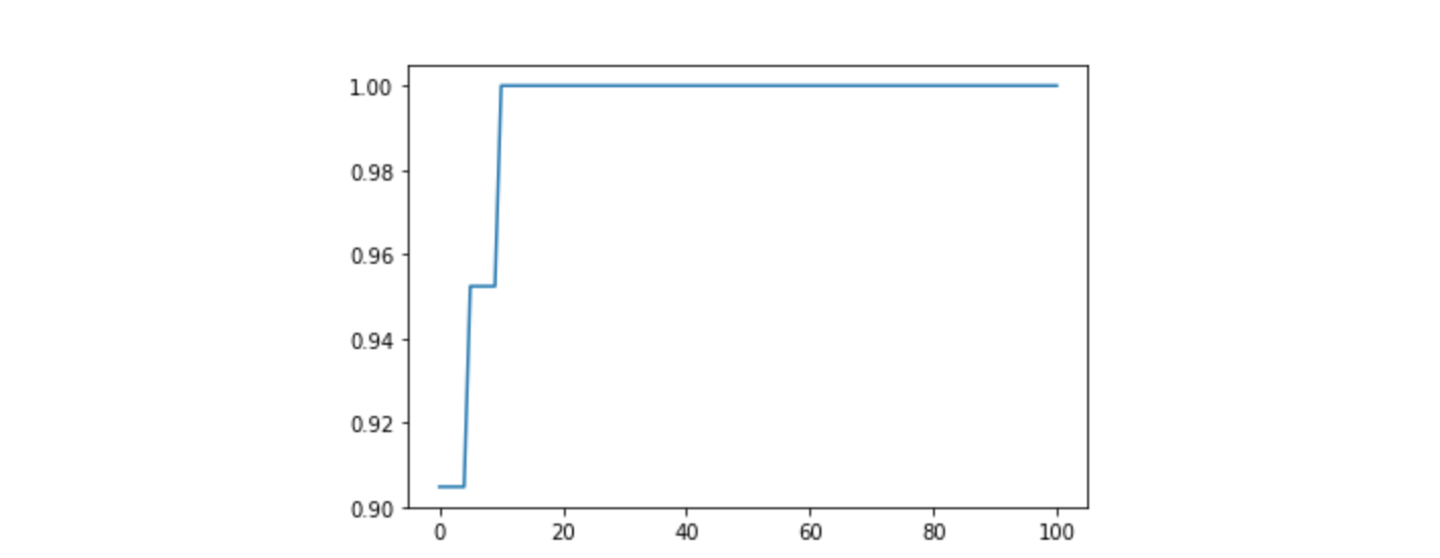
人がチェックしない場合クラス1のリコールは0.9程度であり、その値は人がチェックしていくほど高くなり、人が10%程度見たところで1に到達するようだ、ということが見て取れます。
最後に、リコール99%以上という数値目標を達成するためには何%チェックすればいいかを調べてみましょう。これはscore_to_check_rateメソッドを使って調べることができます。逆にcheck_rate_to_scoreメソッドを使えば人の稼働に対するスコアの値を調べられます。
# Percentage of human cooperatoin to achieve your KPI (e.g. recall score >= 0.99)
coop.score_to_check_rate(class_ref = 1, metric = "recall_score", threshold = 0.99)
10がリターンとして返ってくるので、クラス1のリコールを99%以上にするには、10%だけ人がチェックすれば良いということがわかりました。
さて、一通りメソッドの説明は終えたのですがせっかくなので、もしペナルティーの成分を変えたらどう変化するのか、についても見ていきましょう。
試しに1行目の2つの成分を1.6にしてみます。これはつまり真のクラスが1であるものをクラス0か2だと予測した場合により多くのペナルティーが課すことを意味します。これによってクラス1の可能性がある(例えばその確率が0.4ある)ものはクラス0や2と予測されにくくなります。一方で、クラス0,2の精度は落ちることとなります。なので、ある部分の精度劣化を許してでも特定のミスを減らしたい場合にペナルティーの調整が有効となります。
import numpy as np
# prepare penalty array
penalty_array_1 = np.array([[0, 1, 1],
[1.6, 0, 1.6],
[1, 1, 0]])
その他は上と同様にfit, plot_evalメソッドを使っていきます。
# Instantiation
coop_1 = Cooperante(penalty_array_1)
# Fitting
penalty_min, pred = coop_1.fit(y_pred_proba)
# Visualization
fig, ax = coop_1.plot_eval(y_test, metrics='recall_score', class_ref = 1, sampling_rate=0.01)
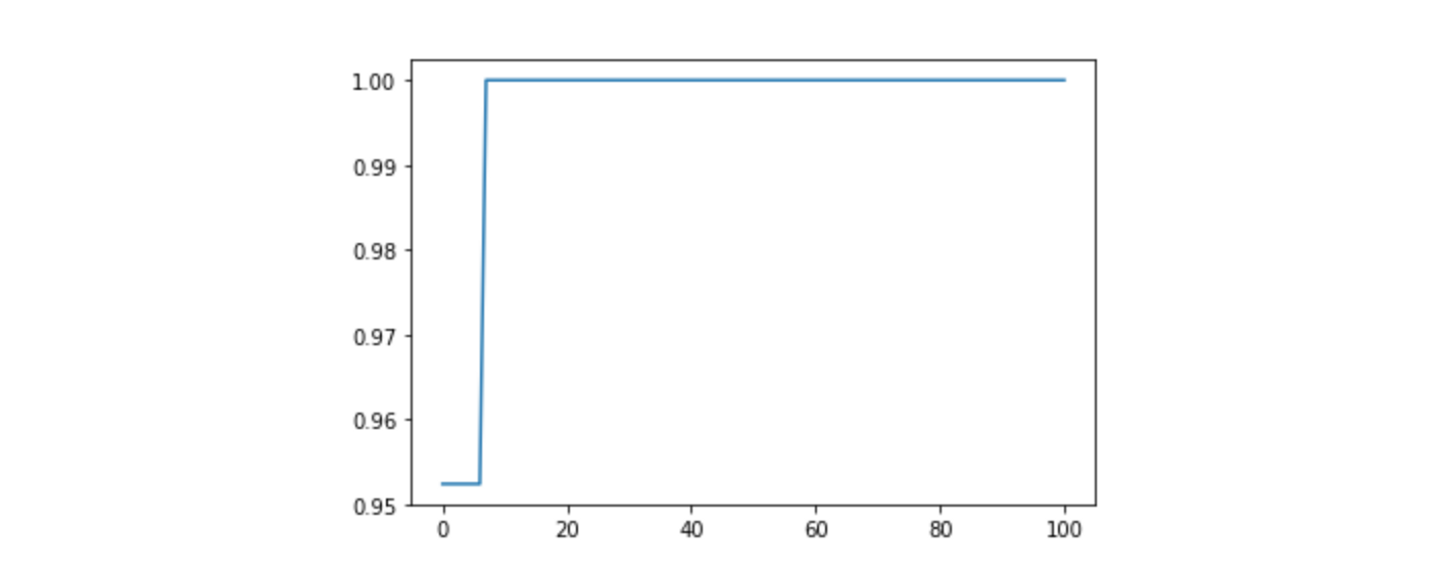
クラス1のリコールは人がチェックをしない場合でも0.95以上となり、ペナルティーを調整する前(約0.90)と比べて向上したことがわかります。
おまけ
上の例では使いませんでしたが、Cooperanteクラスを作る際、オプション引数でclass_to_check(必ず人が目を通さなければならない分類群=人が目を通していないものはその分類群にならない)を指定できます。この引数を入れた場合、例えばclass_to_check=1とすると、クラスごとのペナルティーが[0.9 0.1 0.3]と計算されたサンプルに関して、クラス1以外で最もペナルティーの低い予測クラス、つまりクラス2を予測として返すようになります。なので予測ラベルにクラス1が出てこないことになります。本来クラス1だと予測すべきサンプルで別のクラスを選んだ場合はペナルティーが大きくなるため、予測を外す場合はその代わりに優先度を高める結果を返している、と解釈できます。
これを使うのは、特定のクラスと判定されたものは必ず人がチェックしなければならないケース、つまり人的稼働の最小化ができないケースです。
# Instantiation
coop = Cooperante(penalty_array, class_to_check=1)
おまけ2
因果推論などをやられている方はよくご存知かもしれませんが、分類器としての性能と、確率を正しく推定できるかは分けて考えるべきです。機械学習で確率を推定したいなら,多くの場合calibration的な操作を行うと良いでしょう。それらの処理を行なった後にWise-Coopを使うことをお勧めします。
(参考リンク)
/assets/images/5096925/original/75e73a6d-ca21-474b-8703-927cd4712994?1591158251)

/assets/images/5096925/original/75e73a6d-ca21-474b-8703-927cd4712994?1591158251)

