こんにちは。エンジニアの佐々木です。
先日開催したミートアップにて、カヤックの藤原さんを交えてクラシコムのSREについてお話をさせていただき、1つ目のトークテーマ「インフラ強化に向けた具体的な取り組み」について記事を書かせていただきました。
この記事では、2つ目のトークテーマである「一人に頼らないチーム体制づくりを目指して」について紹介します。
目次
- SREの必要性
- 体制
- 仕組み・文化
- 大怪我しにくい仕組み・環境
- IaC前提での開発
- 変更・オペレーションは必ずペア
- 定例MTGでやっていること
- まとめ
SREの必要性
SREチームの話をする前に、この後の話がイメージしやすくなるよう、開発組織としては規模が小さいクラシコムにおけるSREの必要性について述べたいと思います(前回のブログに引き続きいきなりイベント当日にお話したことではなくすみません…)
まずSREとは何かというのを改めて確認しておくと、SREとはサイト信頼性エンジニアリングの略で、信頼性の高い本番環境システムを実行するための職務、マインドセット、エンジニアリング手法のセットであると発祥元であるGoogleのGCPに記載があります。
企業・サービスのフェーズによるかとも思いますが、SREはある程度の規模の開発組織にチーム・部署が存在していることが多いのではと思います。
例えばスタートアップの場合は、「MVP(Minimum Viable Product)で開発サイクルをたくさん回す必要がある。多少の運用効率化や安定化は後回しにしよう。今は手作業でなんとかなるし、何か起きてもリスクは低い」といったことも多々あることと思います。そのため、SREはある程度の規模の組織によく見られる印象があります。
私自身、複数開発の経験をしてきてこれは当然あることだと思いますし、多くのケースで妥当な判断だと思います。
しかしクラシコムは2022年に東京証券取引所グロース市場への上場を果たし、「北欧、暮らしの道具店」というサイトの売上が会社の売上の多くを占めます。
「北欧、暮らしの道具店」は過去にASPなどを使っており、サービスとしては15年ほどの歴史があります。現在では物販やテキストコンテンツに留まらず、映像や音声コンテンツを制作するなど、今なお成長を続けており、システムの信頼性の重要度は日を追うごとに高まっています。
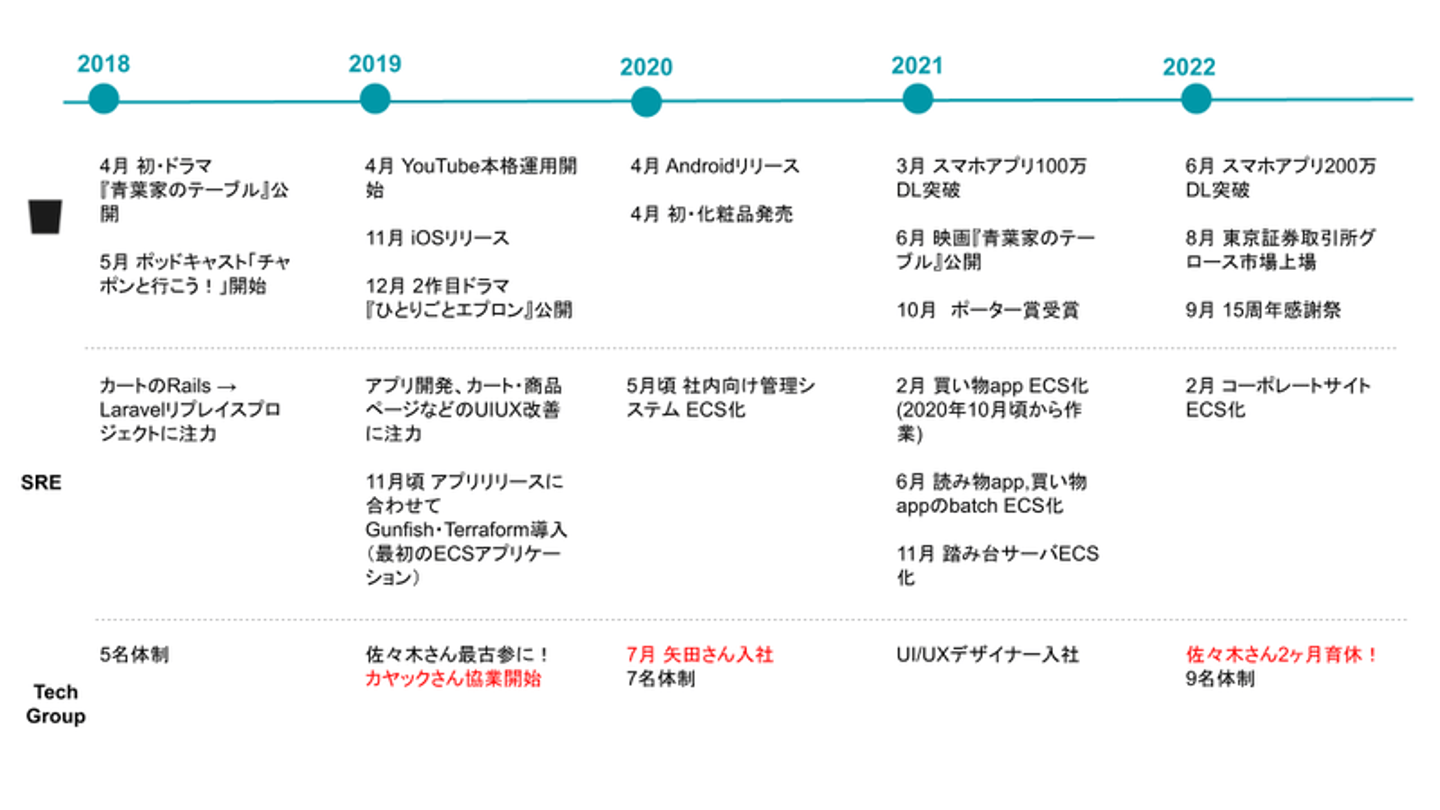
一方、システムを内製し始めてからの歴史は7年程で、社内のエンジニアは現在7名です。(他にUIUXデザイナー2名がグループにいるためイベントでも公開した以下の年表では9名体制)
![]()
ミートアップで公開した組織年表
ビジネスとして一定の成果を上げているサービスに対し、小さく未成熟な開発組織であったからこそ、システムの信頼性を保ちつつ開発パフォーマンスもどうにか上げていきたい。そこでSREのアプローチ・考え方を取り入れるのはどうだろうかと考え、社内で何度か提起し活動を始めました。
体制
SREチームと銘打っていますが、クラシコムの組織図上にはSREチームはありません。
上述したとおり、社内にエンジニアが少なく現状7名。元々フルスタックで開発したいというエンジニアが多いこともあり、開発領域で専門チームを作ることに今のところ合理性はないと判断し分けていません。
将来的には分けるかもしれませんが、現在はフロントエンドからインフラまで、プロジェクト・タスクに応じて対応可能なメンバーがアサインされる体制をとり開発を行っています。
上記のような状態でSREチームを構成するのは以下のようなメンバーです。
- インフラやDevOpsなどの領域に課題を感じている
- 単純に興味があるので触れてみたい
メンバーにはSRE定例というミーティングをGoogle Meetで1〜2週に1度行っており、任意で参加してもらっています。
3年前の活動開始当初は私とカヤックのエンジニアさん数名に参加していただいていたのですが、現在ではクラシコムのエンジニア4名とカヤックの藤原さんの合計5名で運用するようになっています。
なお、クラシコムのエンジニアもいくらか知識・経験はついてきましたが、スペシャリストはおらず、藤原さんは実際には手を動かすことはないアドバイザーのポジションについて頂いています。
SREの組織基盤がある場合、さらにEmbedded SREやEnabling SREなど役割を分けているところもあると思いますが、クラシコムではカヤックの藤原さんにEnabling SREを担っていただいている体制とも呼べると思います。Enabling SREはマネーフォワードさんの記事が参考になります。
仕組み・文化
イベント中に「佐々木が育休取れるぞ!と思えるぐらいまで変化したのはどうしてか?」という質問があり答えた内容でもありますが、SREチームに次のような仕組み・文化が根付いています。
- 大怪我しにくい仕組みや環境を作る
- Infrastructure as Code(以下IaC)前提で開発。Terraformを使用するなど
- 本番のインフラの変更・オペレーションは必ずペアで行う
大怪我しにくい仕組み・環境
安心して開発を進められるよう、以下のように大怪我しにくい仕組みを整備しています。
- DBや画像類のバックアップをクロスアカウント・クロスリージョンでとっている
- 運用・テスト・技術検証がしやすくなるようAWSをマルチアカウントで運用
- AWS・GitHub Organizationなどの権限は移譲・廃止すべきものがないか定期的に確認
- メンテ作業などオペレーションが発生するものに関しては事前にプルリクエストの説明欄やNotionで作業手順をドキュメントとしてまとめ、他者にレビューしてもらうフローをとっている
SaaS・ツール・フレームワークに頼るのはもちろん、Notionにできるだけドキュメントを残したりテンプレートを継続的に改善することで知見を蓄積したり、最小権限の法則を破らないよう気をつけています。
これらは売上や利益に直結するような活動ではありませんが、信頼性の向上ひいてはアジリティにもじわじわ効いてくる活動だと思います。
また、仮に障害などが発生してしまってもチームとして迅速に対応できるよう、定期的に訓練を実施することで万が一にも備えるようにしています。
IaC前提での開発
今どきの開発フローではリリース前にコードレビューをすることは当然のこととなっているかと思いますが、インフラもコードにすることで他者からのレビューが非同期で容易に可能になり、品質の向上に寄与します。
また、Gitで変更履歴とともに変更理由を残せるようになるため、新規メンバーや将来の自分が仕様や変更理由を後から把握するのにも役立っています。同様に履歴があるため完全に破壊的な変更でなければロールバックも比較的容易です。
Terraform導入当初、すでにある環境をTerraformなどで変更していくことに一定の怖さがありましたが、今となってはこれがない開発は考えられないくらいになっています。
クラシコムではAWSだけでなくMackerelやSentryの設定もTerraformで管理するようにしています。
最近ではtfstateというTerraformの状態管理をしているファイルが一部肥大化し反映に少し時間がかかってしまうなどの課題があるので、解消できればと考えています。
変更・オペレーションは必ずペア
インフラ変更のオペレーションを必ずペアで行っているのは、以下のようなメリットがあると考えているからです。
- 反映待ち中に技術的な雑談や相談、質問を行うなどスキルトランスファーにつながることがある
- Terraformの変更は必ず成功するわけではないので、その場合のトラブルシューティングを迅速に行える
- 万が一変更・オペレーションによって障害になってしまった場合、初動が早くなる可能性がある
経験の少ないメンバーだとトラブルシューティングを行うことがまず難しかったりするので、時間はかかりますが中長期で見ると確実にチームのスキルの底上げに繋がります。
なお、terraform applyをCI/CDパイプライン上で行うことは長期に渡って検討したのですが、上記メリットとセキュリティや変更失敗時の考慮事項が少なからずあったため、実施せず今のところterraform planを行うまでにとどめています。良い感じでのパイプライン上での実行は今後の課題になります。
定例MTGでやっていること
SRE定例というミーティングを行っている旨を上記で記載しましたが、定例では気になるレベルのことも共有したうえで、課題ややるべきことを確認し、ネクストアクションにつなげています。具体的には以下の内容を話しています。
- 各自が前回のMTGからの間でやったことの共有・確認
- 前回のMTGからの間で起きたアラートの確認
- SLI/SLO確認
- ダッシュボードのメトリクス確認
- インフラコストの動き確認
- ザッソウ
とくに問題がなければ30分程度で終わりますが、相談事はもちろん、少しでも気になるところがあればその場でMackerel、AWSのCloudWatch LogsやCost Explorerなどを画面共有で開きみんなで見ながら仮説を立て原因を探るようにしています。
全員でモブプロするように話しながら作業をするので、仮説の立て方からメトリクスの見方、ログの探り方など、普段の開発ではなかなか気づけないようなことの良い気づきの場にもなっています。
課題が見つかった場合はこの場でタスクのアサインをするのではなく、タスク管理しているTrelloのボード上にカードを残しておき、後日プロジェクト・タスクのアサインを行う別のミーティングで緊急度やおおよその工数をすり合わせて対応を行うことにしています。
ザッソウは雑談・相談の時間で、最近気になっているツールやサービス、脆弱性、聞きたかったけど聞けなかったことなどを話します。
ザッソウについては弊社社外取締役でもある株式会社ソニックガーデン倉貫さんの考えが元なのですが、エンジニア以外のスタッフも参考にしています。
まとめ
クラシコムの開発組織の規模はまだ小さく課題もなくなることはありません。しかしSREの活動を続けることで安定した運用を行うことができるようになってきました。
オオカミ少年気味だったアラートも現在ではほとんどなくなり、何かあったとしても迅速に対応できるメンバーが増えてきています。初期のメンバーが少なかった頃と比べ、安心感や効率性が段違いです。
チームメンバー同士で知見を共有しつつ、相互の信頼性を向上していくことも、安定してサービスを運用するには必要なことだと改めて感じます。
記事中にあげた課題以外に、DevSecOpsの充実や、深夜にメンテナンス作業しているのをどうにかしていく取り組みであったり、マルチステージング環境の構築などが今後の課題としてあります。
これらの課題も少しずつ着手しているところなので、ある程度解消できたらご紹介できればと思います。
以上、イベントおよびこの記事がSREに課題を感じている方の参考になれば幸いです。



/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)
/assets/images/8962265/original/c7866d47-17e7-4032-8d3d-04275630324d?1646121547)


