こんにちは、ナイトレイインターン生の鈴木梨子です!
Wantedlyをご覧の方に、ナイトレイのエンジニアがどのようなことをしているか知っていただきたく、Qiitaに公開している記事をストーリーに載せています。
少しでも私たちに興味を持ってくれた方は下に表示される募集記事もご覧ください↓↓
1. scikit-mobilityとは?
scikit-mobilityは位置情報データを使用して人の動きを解析したり、可視化することができるpythonライブラリです。
公式ドキュメント:https://scikit-mobility.github.io/scikit-mobility/index.html
GitHub:https://github.com/scikit-mobility/scikit-mobility
公式ドキュメントは英語しかありませんが結構充実していて、
GitHubにはチュートリアル等も載っているので試してみるのがおすすめです。
scikit-mobilityの主な機能と、チュートリアルについて解説しているQiitaもありますのでこちらも是非参考にしてください。
2. 今回紹介する関数
また、データ解析用の関数には二種類のカテゴリがあります。
- Collective measures(集団解析) : データセット全体の人流データの動きを解析できる関数
- Individual measures (個別解析):データセット内のユーザーそれぞれの動きを解析できる関数
今回はこのうち
Individual measures (個別解析)
に分類される17個の関数のうち以下の6個の関数を、コードを交えて紹介していきます。
※ 今回この記事で使用しているデータは社内検証用のデータになります。
3. 前提処理
ライブラリのインストール
$ pip install scikit-mobility
詳しい環境構築はこちらを参考にしてください
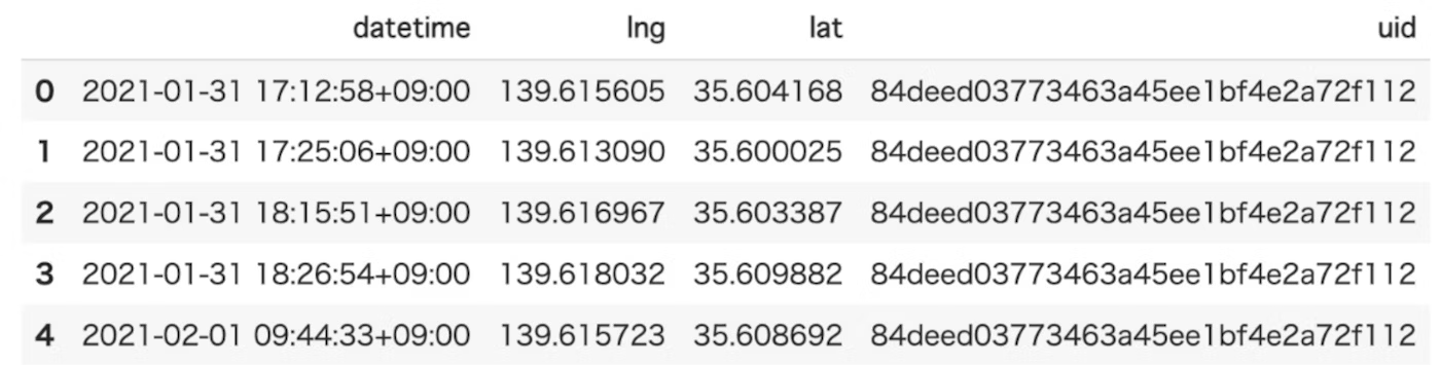
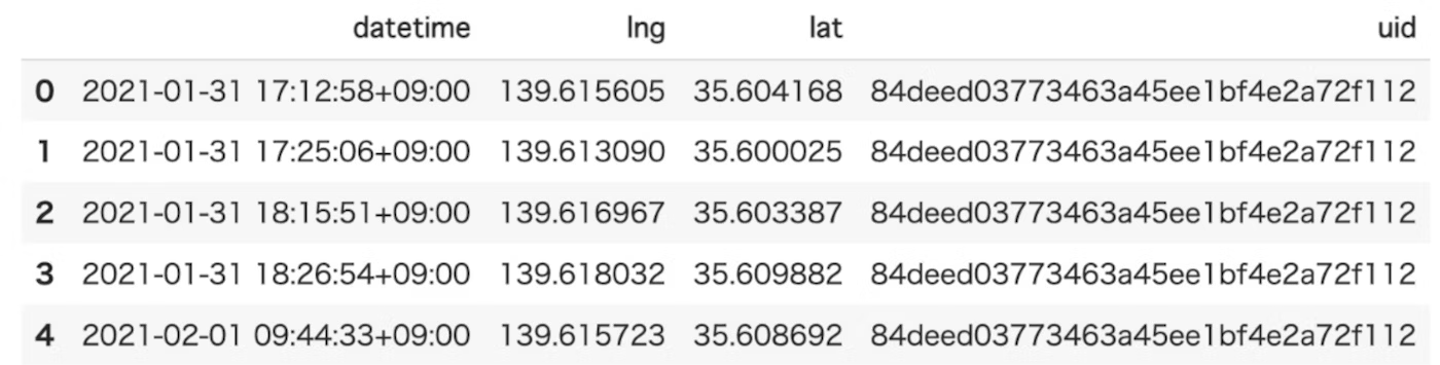
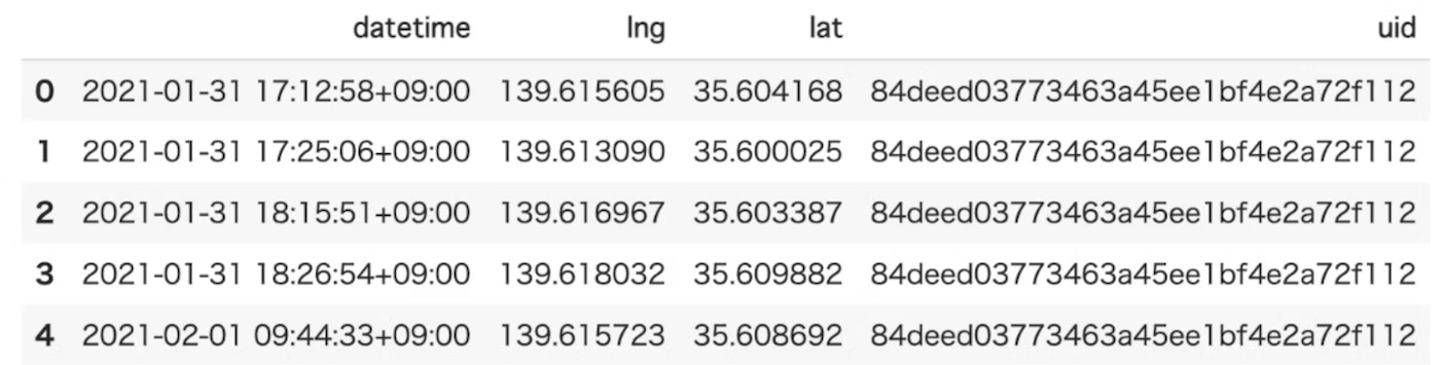
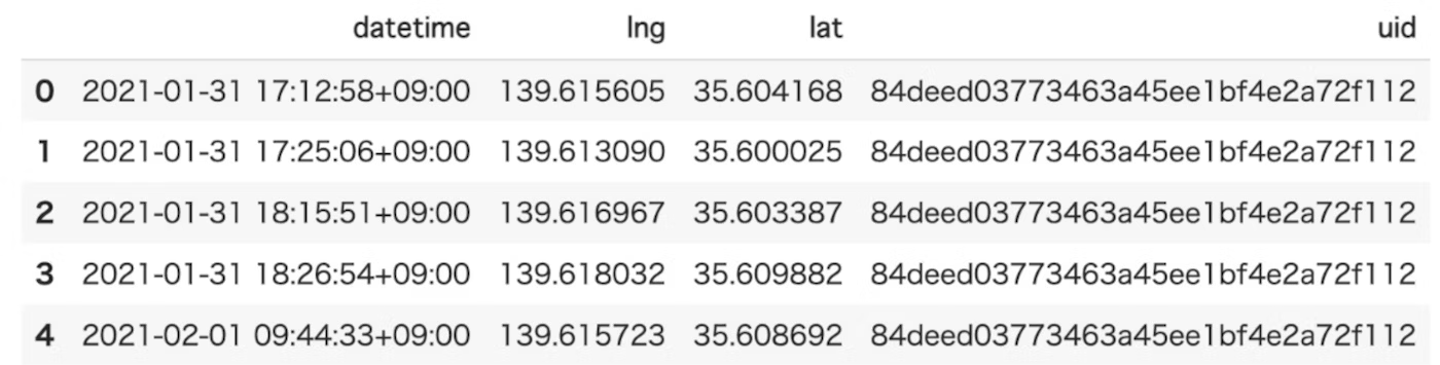
TrajDataFrameデータの作成
latitude(type: float); 緯度(必須)
longitude (type: float); 経度(必須)
datetime (type: date-time); 日時(必須)
uid (type: string);(オプション)
tid (type: string); (オプション)
特に使いたいデータがない場合はscikit-mobilityのチュートリアルを参考にこちらのデータをダウンロードするといいと思います。
※自動でデータがダウンロードされるので気をつけてください
# ファイルのダウンロード(google colab等で実行する場合はこうすると楽です。)
import urllib.request
url='https://raw.githubusercontent.com/scikit-mobility/scikit-mobility/master/examples/geolife_sample.txt.gz'
save_name='geolife_sample.txt.gz'
urllib.request.urlretrieve(url, save_name)
- 用意したデータをTrajDataFrameに変換します。
import skmob
# リストをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_list, latitude=1, longitude=2, datetime=3)
# pandas.DataFrameをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_df, latitude='latitude', datetime='hour', user_id='user')
4.Individual measures (個別解析)
参考URL:https://scikit-mobility.github.io/scikit-mobility/reference/individual_measures.html
概要
入力したuidごとの移動履歴、行動パターンを解析する関数
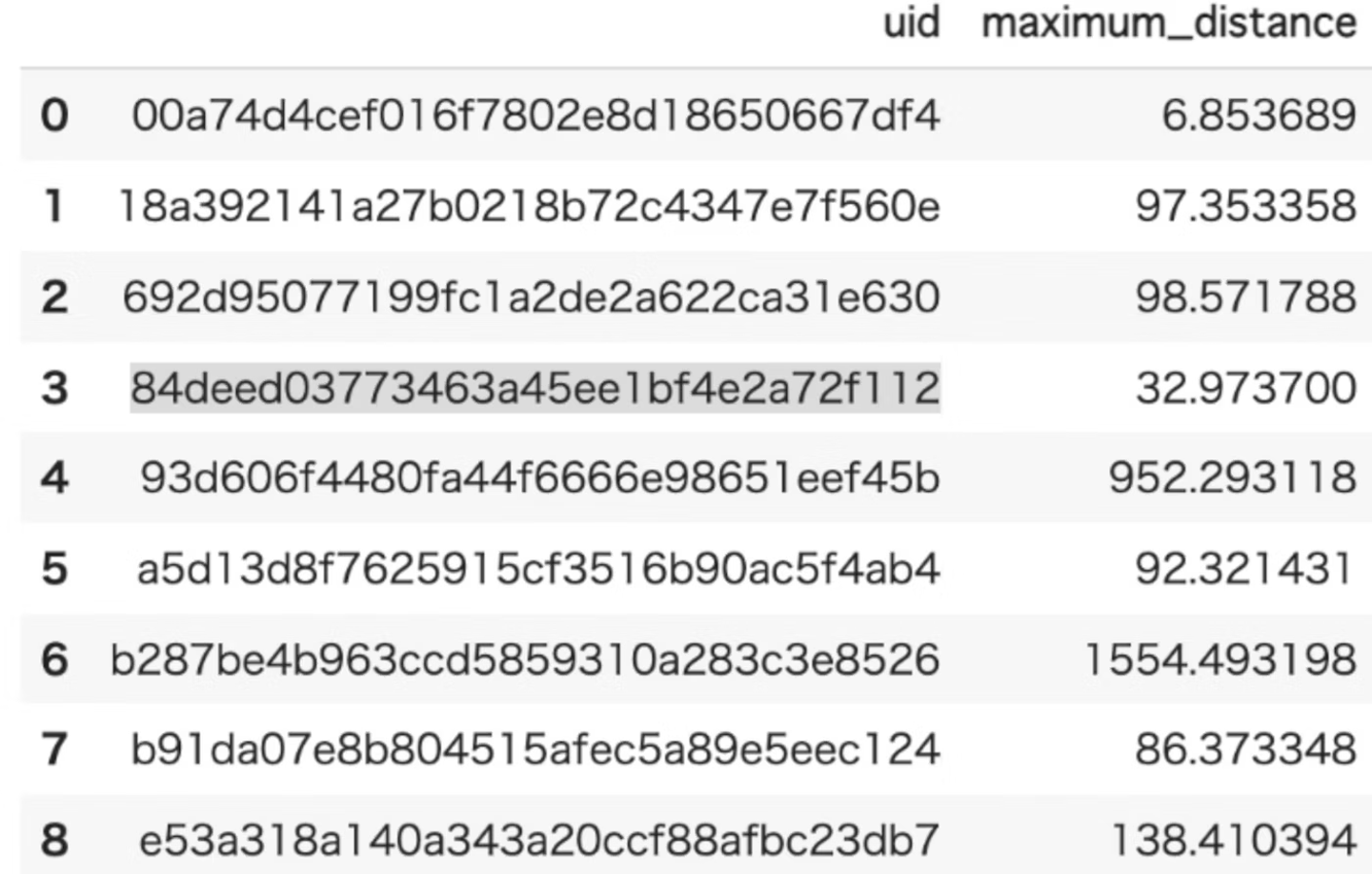
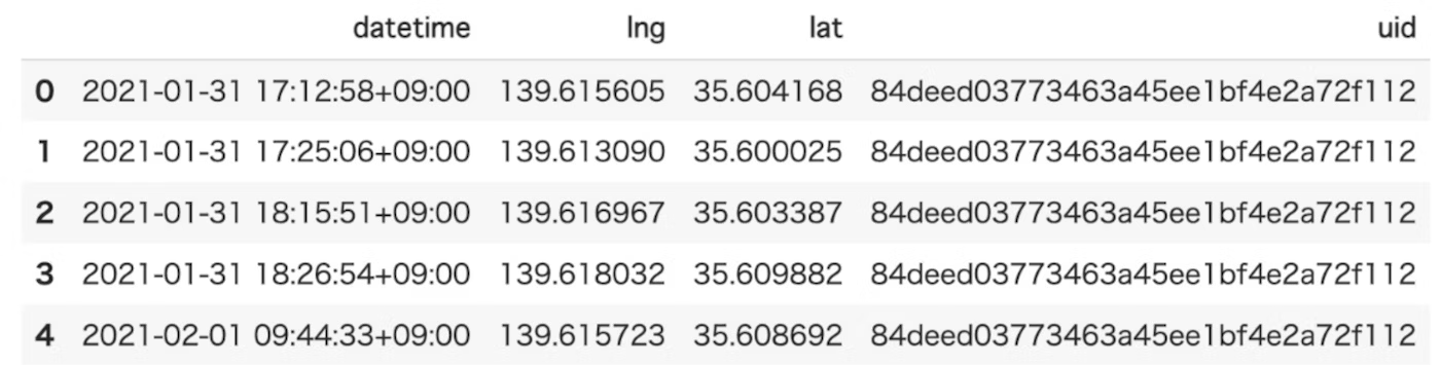
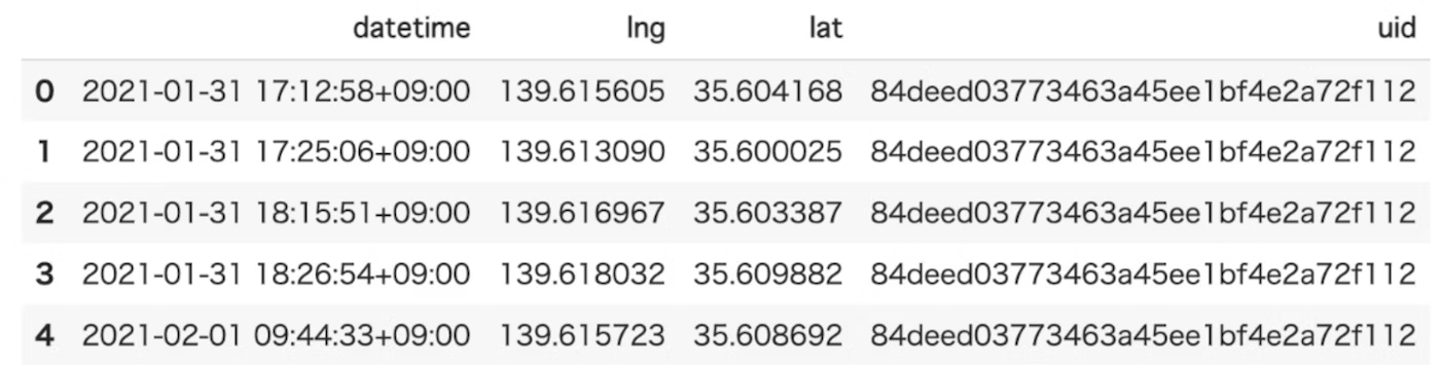
maximum_distance
概要
各ユーザーの時間順に並んだ連続する2点間の地理的距離の最大距離(km単位)を算出する。
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ、パラメータ
- tdf(TrajDataFrame): 緯度経度データ
- show_progress: Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 各ユーザーの最大移動距離
- outputされるデータ例
![]()
- これを地域別で解析したりすると、地理的な特徴と合わせて、その土地の人の傾向などが見えてきたりしそうだなと思いました。
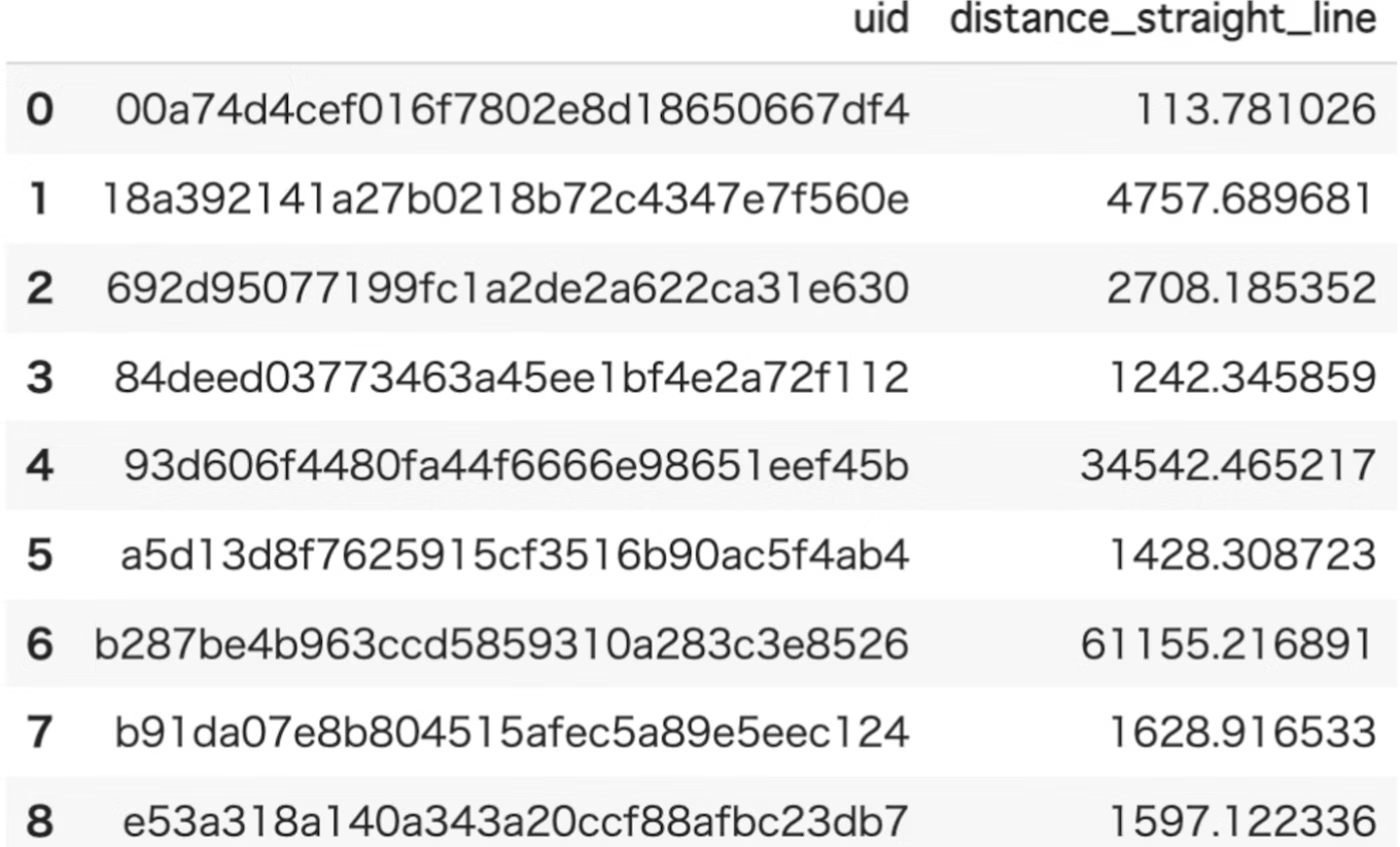
distance_straight_line
概要
各ユーザーが移動した総移動距離(km)を算出する関数
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ、パラメータ
- tdf(TrajDataFrame): 緯度経度データ
- show_progress: Trueの場合、プログレスバーを表示
●inputデータ例
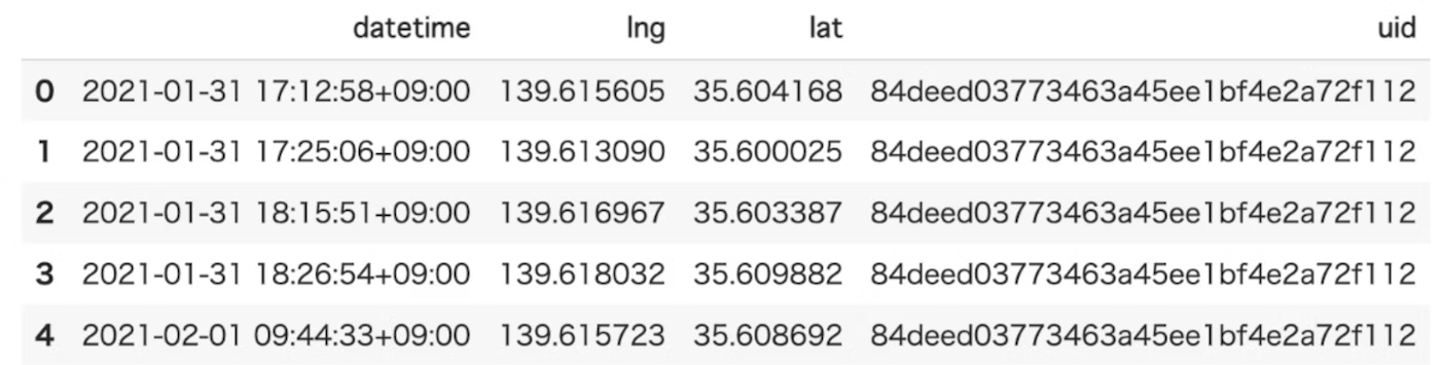
- データ型はTrajDataFrame。
- inputデータは、datetimeで昇順に並べ替える必要があります。
![]()
●outputデータ
- 各ユーザーが移動した総移動距離(km)が算出されます
- outputされるデータ例
![]()
- ユーザーの総移動距離を算出できるので、移動が多いユーザー、反対になかなか移動がないユーザーを判定したりすると、データ内のユーザーの傾向が掴めそうです。
- 時間帯や、ユーザーが住む地域等でデータを絞ってからこの関数にかけてみても、ユーザーの傾向が出やすいのではないかなと思いました。
waiting_times
概要
各ユーザーの移動間の待機時間(秒単位)を算出します。
待機時間:2つの連続するポイント間の時間とも定義されます。
数式で見た方がわかりやすいかもしれないです。
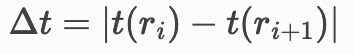
Δt :waiting_time(待機時間)
t(ri) :i地点でのdatetime
t(ri+1) :i+1地点でのdatetime
(久々にLaTex使いました。数式綺麗に書くの楽しいですよね)
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ
- tdf(TrajDataFrame): 緯度経度データ
●パラメータ
- show_progress: Trueの場合、プログレスバーを表示
- merge: Trueの場合、ユーザーのリストを1つのリストにマージ
●inputデータ例
- データ型はTrajDataFrame。
- inputデータは、 datetimeで昇順で並べ替える必要があります。
![]()
●outputデータ
- 各ユーザーの待機時間のリスト。(mergeがTrueの場合は全ての待機時間をまとめたリスト)
- outputされるデータ例
![]()
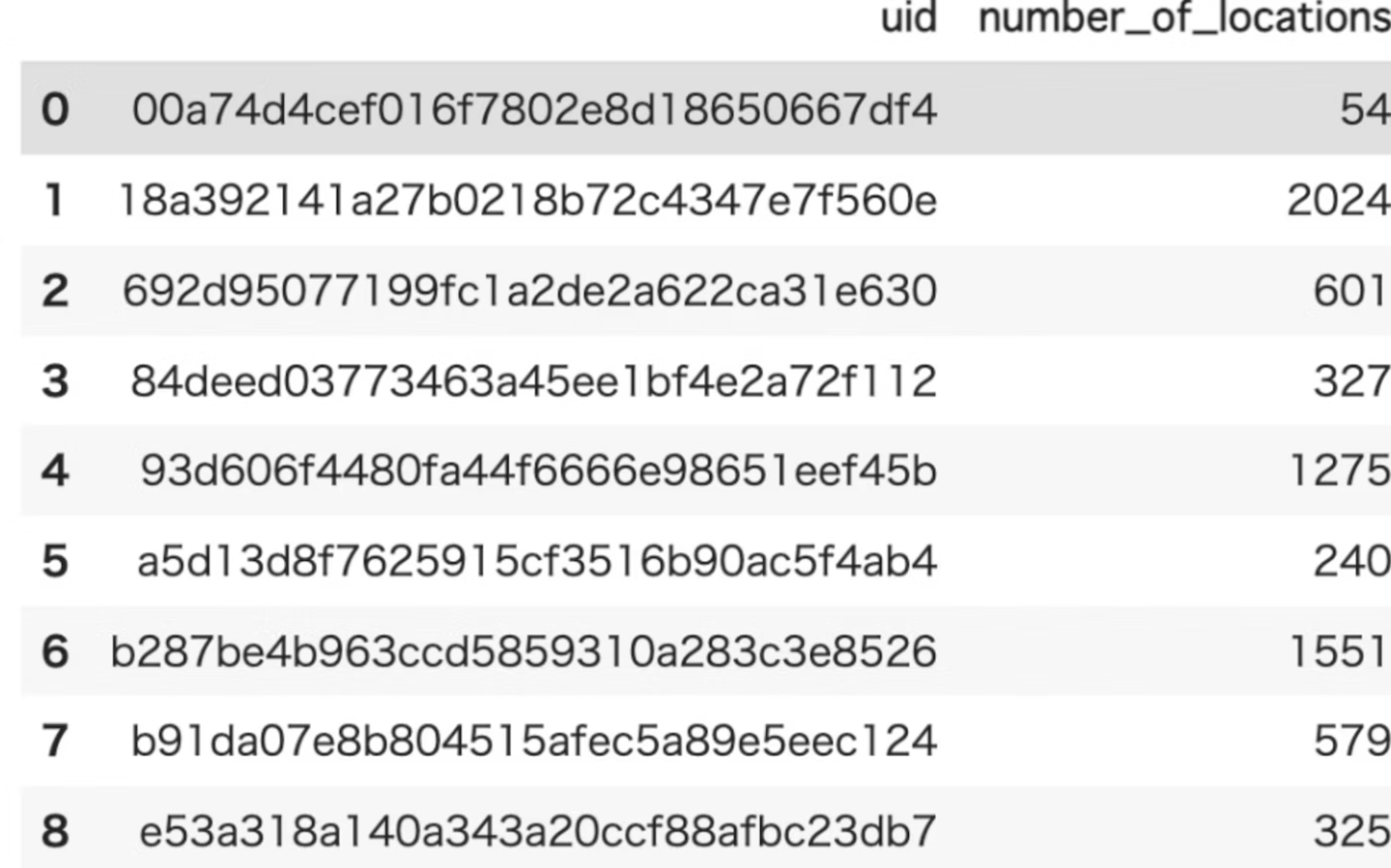
number_of_locations
概要
各ユーザーが訪れた個別の場所の数を算出する関数。
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ、パラメータ:
- tdf(TrajDataFrame): 緯度経度データ
- show_progress: Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 各ユーザーごとの訪れた個別の場所の数を算出します。(number_of_locations)
- outputされるデータ例
![]()
- 移動距離の多さだけでなく、訪問した場所の数がわかるとさらにユーザーの移動パターンの特徴が出そうだなと思いました。 (距離は多くても、訪問した場所が少ないのは移動が多いから?など)
home_location
概要
各ユーザーの自宅の位置を特定します。
夜間(パラメータで指定した時間内)に最も訪れた場所が自宅と定義されます。
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ
- tdf(TrajDataFrame): 緯度経度データ
●パラメータ
- start_night(HH:MM): 夜の開始時刻
- end_night(HH:MM): 夜の終了時刻
- show_progress(True/False): Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 自宅の場所の緯度経度とユーザーID(uid)のペアを出力します。
- outputされるデータ例
![]()
- 自宅とされる場所が緯度経度レベルで出力されるので、結構詳しく出る印象です。
- 夜間と判定する時間を詳しくパラメータで指定できるので、ここのパラメータとデータを工夫すれば、色々な場所を推定することができるのではないかなと思いました。
- 例えば:平日のデータのみにして、昼間の9:00~18:00くらいを指定して、ユーザーの職場や学校などの位置の傾向を推定することができるのではと思いました。
- 休日や連休にデータを絞ってみても面白いかもしれないです。
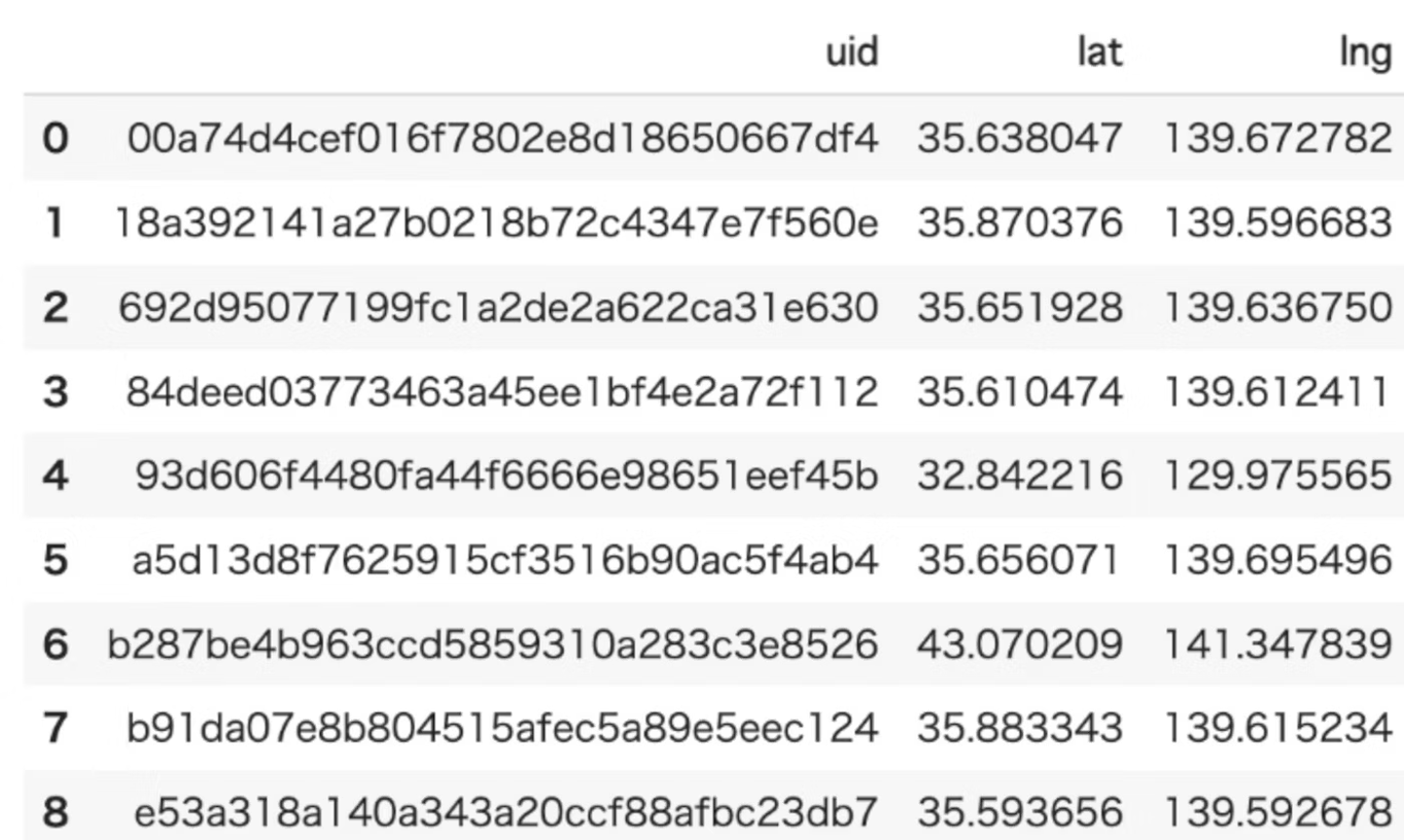
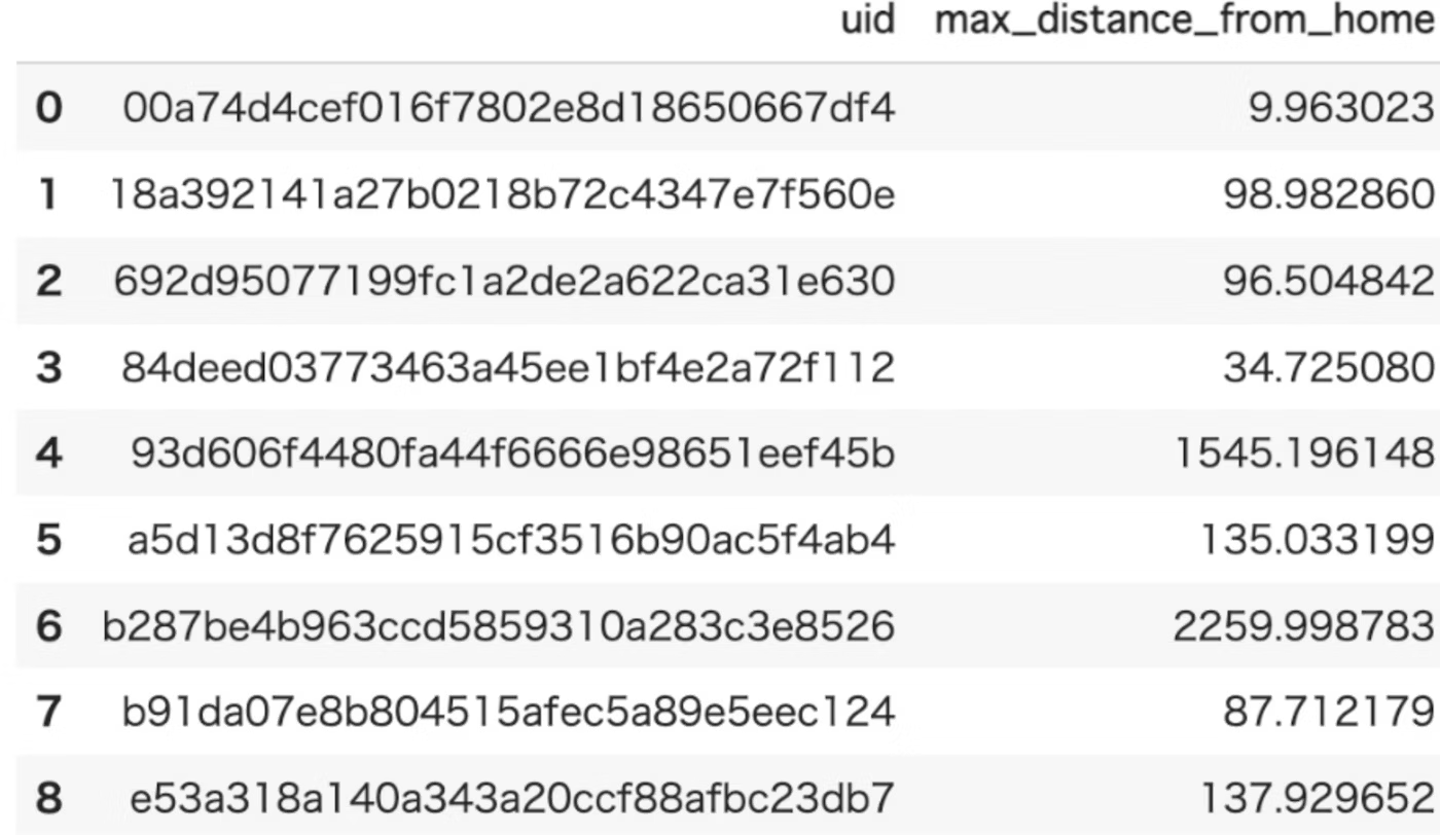
max_distance_from_home
概要
ユーザーが自宅の場所から移動した最大距離(km)を算出します。
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ
- tdf(TrajDataFrame): 緯度経度データ
●パラメータ
- start_night(HH:MM): 夜の開始時刻
- end_night(HH:MM): 夜の終了時刻
- show_progress(True/False): Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- ユーザーが自宅から移動した最大距離(km)
- outputされるデータ例
![]()
- こちらはユーザーが自宅と判断した場所から移動した最大距離を算出します。
- こちらも自宅と判定するための時間をパラメータで細かく指定できるので、"自宅からの最大距離"に縛られずに、データの内容や、パラメータの指定で色々なユーザーの行動パターンが推定できるのではないかと思います。
- 平日のデータに絞って、昼間の時間をパラメータで指定し、職場や学校を推定しそこからの最大移動距離を見てみるのもまたユーザーの行動パターンが現れそうです。(仕事や学校の後に行く最大の距離は職場と自宅との距離と関係があるのか?なども見れそうです。)
- また、データを休日や連休に絞ってみるのも色々なパターンが見えてきそうです。
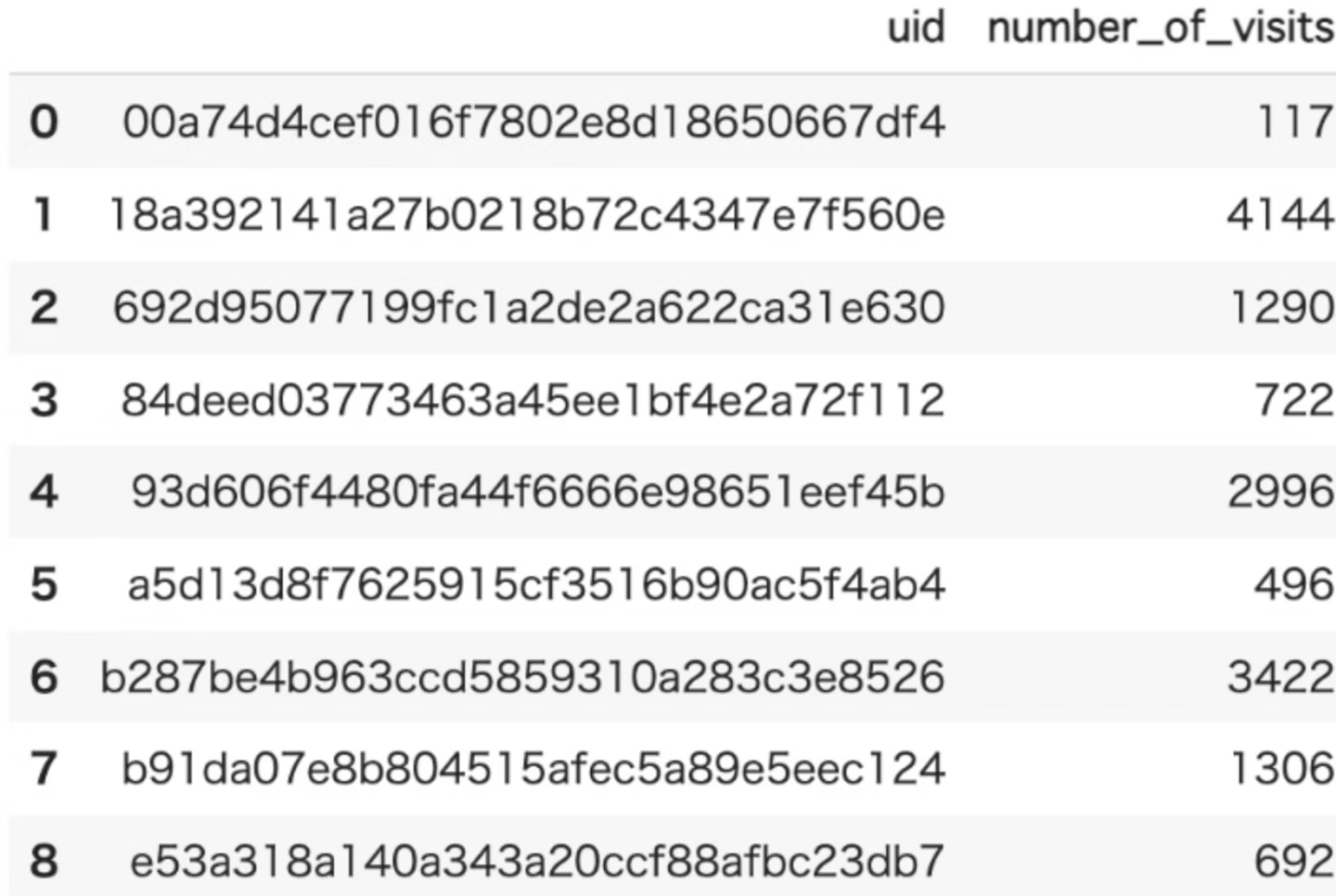
number_of_visits
概要
各ユーザーの訪問(データポイント)数を計算
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ、パラメータ
- tdf(TrajDataFrame): 緯度経度データ
- show_progress(True/False): Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 各ユーザーあたりの訪問数またはデータポイント数
- outputされるデータ例
![]()
- こちらはデータポイント数がわかるので、GPSデータがどれくらい取れているかなどがわかるかなと思います。ユーザーごとのデータポイントがわかると、ユーザーごとのデータの比率がわかるので、データセット内の分布の特徴を捉えるのに向いている関数かなと思います。
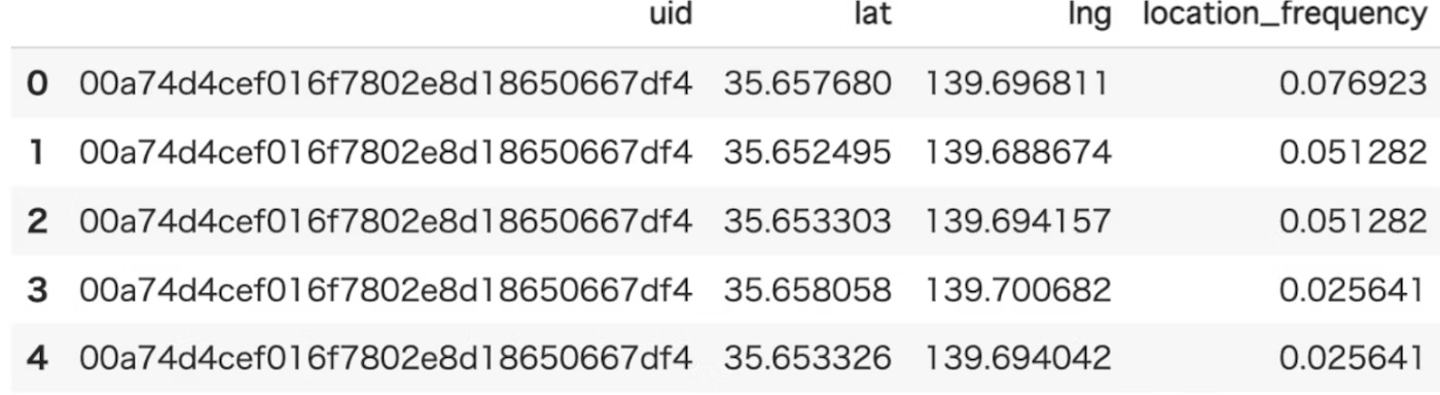
location_frequency
概要
各ユーザーの各場所への訪問頻度を算出します。
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ
- tdf(TrajDataFrame): 緯度経度データ
●パラメータ
- normalize(True/False): Trueの場合ユーザーによるlocationへ訪問数は確率として計算される
- as_ranks(True/False): Trueの場合、平均訪問回数のリストを返す(リストの要素の”i”番目が”i”番目に頻度の高い訪問場所への訪問回数を表す)
- show_progress(True/False): Trueの場合、プログレスバーを表示
- location_columns(string): locationを表す列の名前を指定できます。
●inputデータ例
![]()
●outputデータ
- 各ユーザーの各場所に訪問した頻度を算出できます。
- outputされるデータ例は以下のようになります。
- uidとユーザーが訪問した場所の緯度経度、その場所に訪問する頻度(location_frequency)が出力されます。
![]()
- これもユーザーの行動の傾向を知るのに良い関数かなと思います。
- どのユーザーがどのくらいの頻度で特定の場所を訪れているか、どの地域にある場所によく訪れるのかなどを知ることができそうです。
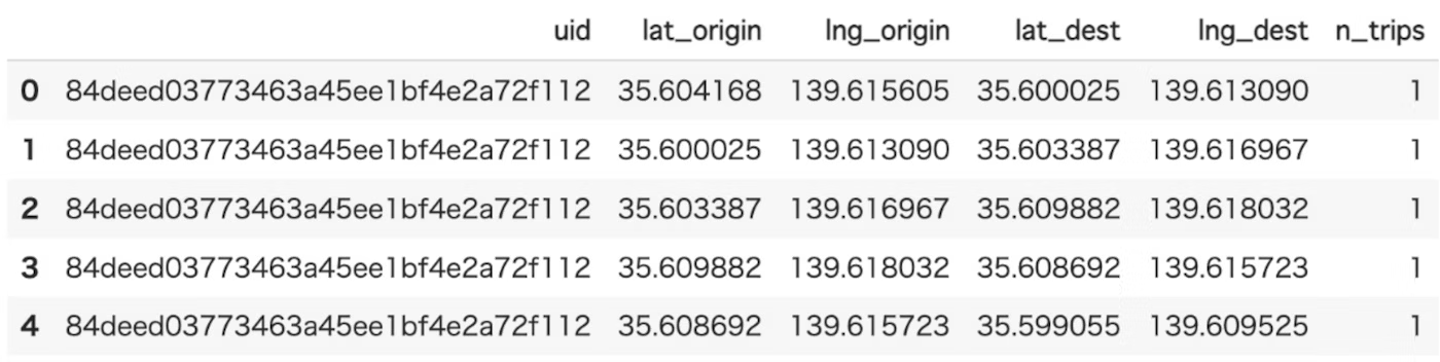
individual_mobility_network
概要
各個人の個々のモビリティネットワーク(起点、目的地、移動回数)を算出
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ
- tdf(TrajDataFrame): 緯度経度データ
●パラメータ
- self_loops(True/False): Trueの場合、自己ループを追加
- show_progress(True/False): Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 各個人の個々のモビリティネットワーク(起点、目的地、移動回数)を算出します。
- outputされるデータ例は以下のようになります。
![]()
- lat_origin, lng_origin:出発点の緯度経度
- lat_dest, lng_dest: 目的地の緯度経度
- n_trips:移動回数
- この解析の結果を見てみると面白いことに起点から目的地までの間で少し止まった回数を移動回数としているようで、"乗り換え"がこの移動回数とされているんだなとわかるデータがあったりして興味深い関数だなと思いました。
- 起点から目的地まで平均でどのくらい移動するのかを調べたりするのもいいかなと思います。
- 移動が多いユーザーの目的地や起点がどこなのかなどそういったユーザーの傾向を調べるのにも役立ちそうです。
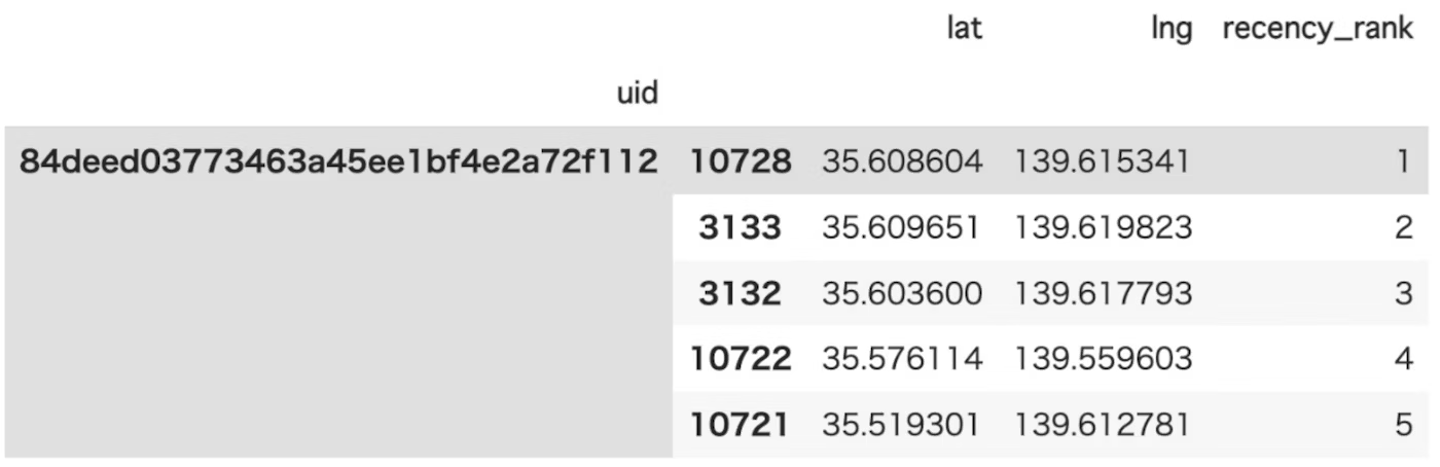
recency_rank
概要
各ユーザーが訪れた場所の最新ランクを計算
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ、パラメータ
- tdf(TrajDataFrame): 緯度経度データ
- show_progress(True/False): Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 各ユーザーが訪問した場所の訪問頻度ランク
- ランク1:ユーザーが最も最近訪問した場所
- ランク2:ユーザーが2番目に最近訪れた場所(以下同様)
- outputされるデータ例は以下になります。
- uidと訪れた場所の緯度経度、最新から何番目に訪れたかのランク(recency_rank)が表示されます。
![]()
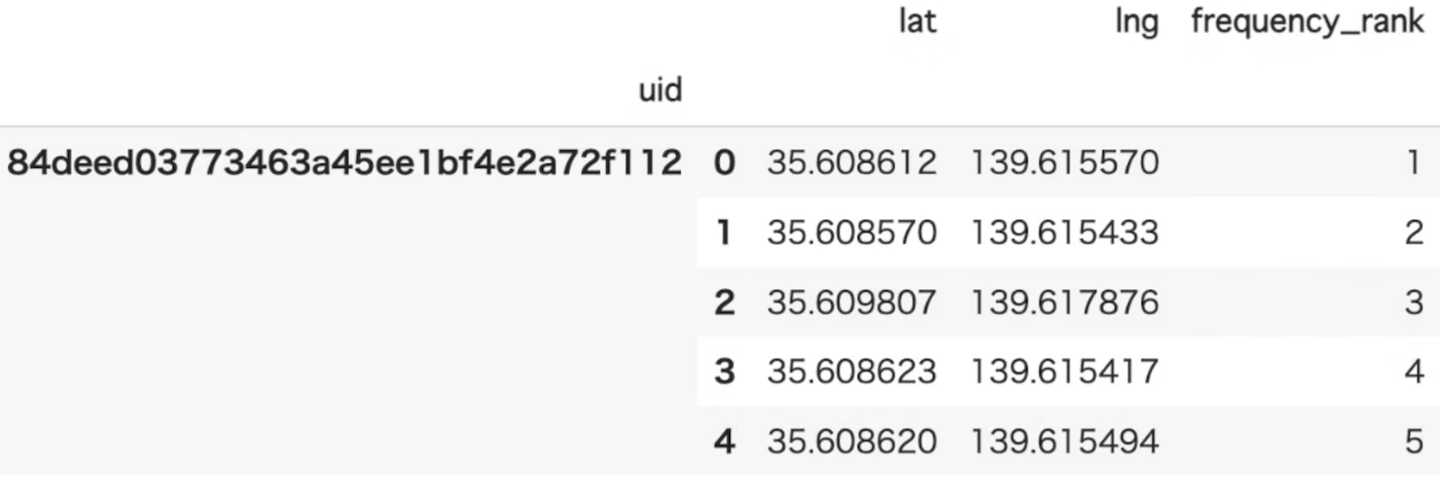
frequency_rank
概要
各ユーザーのよく行く場所ランキングを算出します。
inputに必要なデータとパラメータ、outputされるデータ
●inputデータ
- tdf(TrajDataFrame): 緯度経度データ
●パラメータ
- show_progress(True/False): Trueの場合、プログレスバーを表示
●inputデータ例
![]()
●outputデータ
- 各ユーザーが訪問した場所の訪問頻度ランク
- ランク1:ユーザーが最も訪問した場所
- ランク2:ユーザーが2番目に多く訪れた場所(以下同様)
- outputされるデータ例は以下のようになります。
- uidと訪れた場所の緯度経度、訪問頻度のランク(frequency_rank)が表示されます。
![]()
- こちらは時系列関係なく、よく訪問する場所のランキングを表示します。
- 各ユーザーがよく訪れる場所のランキングが出力されます。データ内のユーザーが訪問する傾向にある場所や、地域などの傾向を解析できそうです。
- 自宅付近がランキングの上位に来ることが多いようです。その辺の傾向を抑えてから関数を使うと、よりよくユーザーの傾向が解析できると思います。
5.シリーズ記事
scikit-mobilityについて、シリーズで記事を投稿しています。
シリーズの記事もぜひ読んでいただけると嬉しいです。
前回の記事はこちらです。
最後に
私たちの会社、ナイトレイでは一緒に事業を盛り上げてくれるGISチームメンバーを募集しています!
現在活躍中のメンバーは開発部に所属しながらセールス部門と密に動いており、
慣れてくれば顧客とのフロントに立ち進行を任されるなど、顧客に近い分やりがいを感じやすい
ポジションです。
このような方は是非Wantedlyからお気軽にご連絡ください(もしくは recruit@nightley.jp まで)
✔︎ GISの使用経験があり、観光・まちづくり・交通系などの分野でスキルを活かしてみたい
✔︎ ビッグデータの処理が好き!(達成感を感じられる)
✔︎ 社内メンバーだけではなく顧客とのやり取りも実はけっこう好き
✔︎ 地理や地図が好きで仕事中も眺めていたい
一つでも当てはまる方は是非こちらの記事をご覧ください 。
二つ当てはまった方は是非エントリーお待ちしております(^ ^)
「位置情報×モビリティ.まちづくりetc事業領域拡大の為GISエンジニア募集」
▼ナイトレイとは?


/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)


/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)
/assets/images/8300070/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1639042247)


