
こんにちは!
グロービスでデータサイエンスチームのプロダクトマネージャーをしている宮島です。
こちらの記事でも紹介したように、現在グロービスでは学習データとHRデータの活用に本腰を入れ始めています!
その一例として最近は機械学習PJTもいくつか開始しています。
しかし一般論として、企業内で機械学習PJTを初めて行う場合は失敗する確率が高いと言われています。
そこで、今回はグロービスで機械学習PJTを失敗させないために重視しているポイントについて紹介したいと思います。
その上でグロービスにおいてどのように実践しているかも紹介出来ればと思います。
機械学習PJTを進めるときに気をつけているポイント
これまでの自分自身のPM経験から、機械学習PJTを進行する際には下記5つのポイントに気をつけています。

しかしこれだけですとイメージが沸かないかと思いますので、グロービスにおける実践例を通して具体的に内容を説明していきます。
実践に用いた機械学習PJTの概要
実践例をお伝えする前の前提情報として、実践に用いた機械学習PJTの内容を紹介します。
どんなPJTか?
一言でいうと、オウンドメディアであるGLOBIS知見録(以下知見録)からオンライン学習サービスであるグロービス学び放題(以下グロ放題)への誘導を最適化するというPJTになります。
改良前のアルゴリズムは、下記のように知見録記事に付与されたタグと合致するグロ放題のコースをランダムで5個表示するというルールベースのアルゴリズムになっていました。
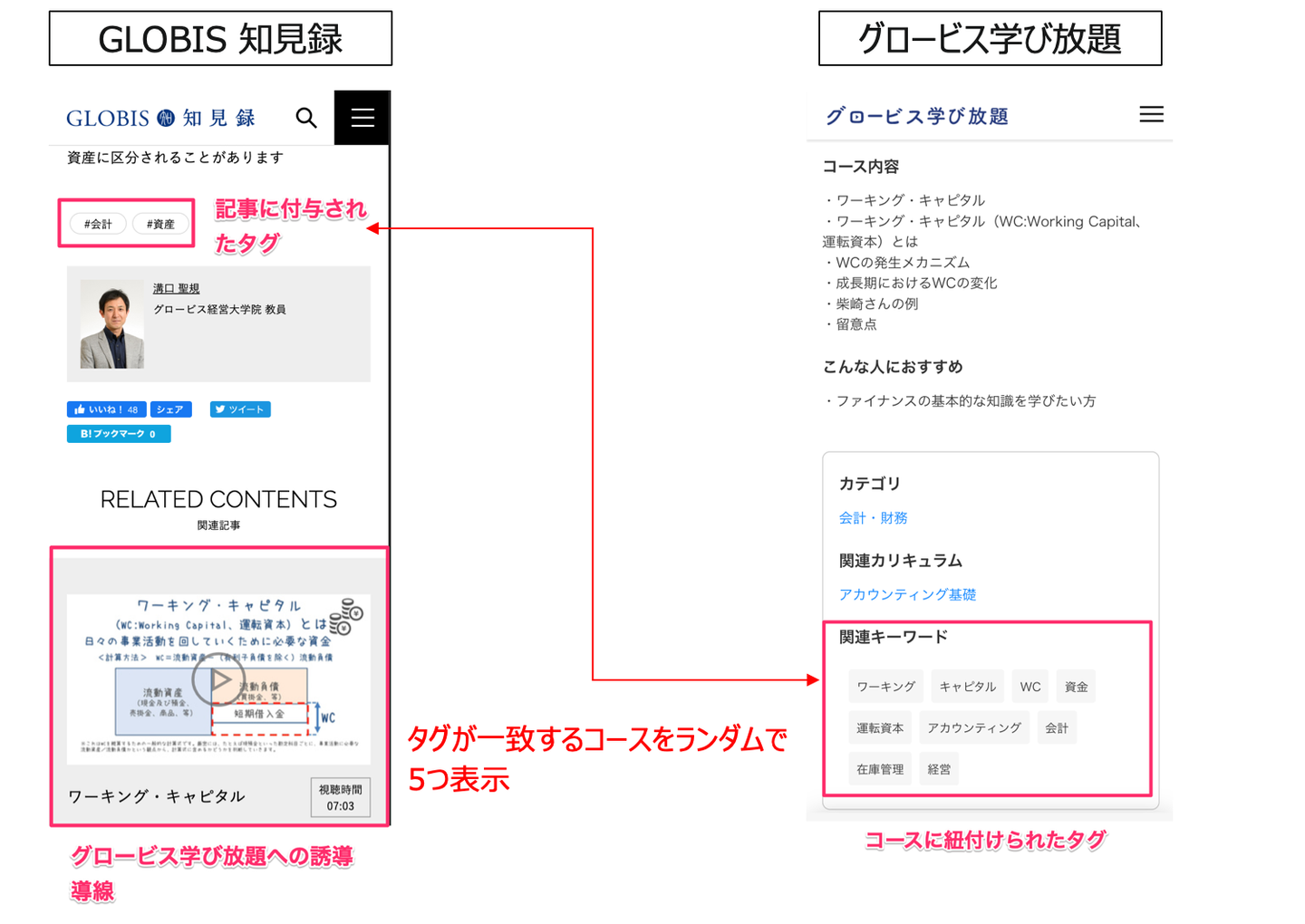
旧アルゴリズムの問題点は何か?
大きく2つの問題点がありました。
1つ目の問題点は、グロ放題への誘導導線が表示されないという機会損失です。
知見録上には存在するがグロ放題には存在しないタグを付与された記事に関しては、グロ放題コースが表示されなくなりimpression観点で機会損失が発生していました。
2つ目の問題点は、関連性の低いコースも表示されてしまう点です。
タグ一致でかつランダム表示であるため、記事の内容と本当に関連度の高いグロ放題コースが表示されないケースも発生していました。
解決策としてどんなアルゴリズムにしたか?
知見録記事とコース情報のそれぞれの文章をTF-IDF表現でベクトル化し、コサイン類似度を使って類似度計算をする事で類似度が高いコースを5個表示するというコンテンツベースのレコメンドアルゴリズムにしました。
ImpressionやClickログを用いたアルゴリズムも試したかったのですが、これらのログが取得出来ていなかった事からログベースは一旦諦めました。
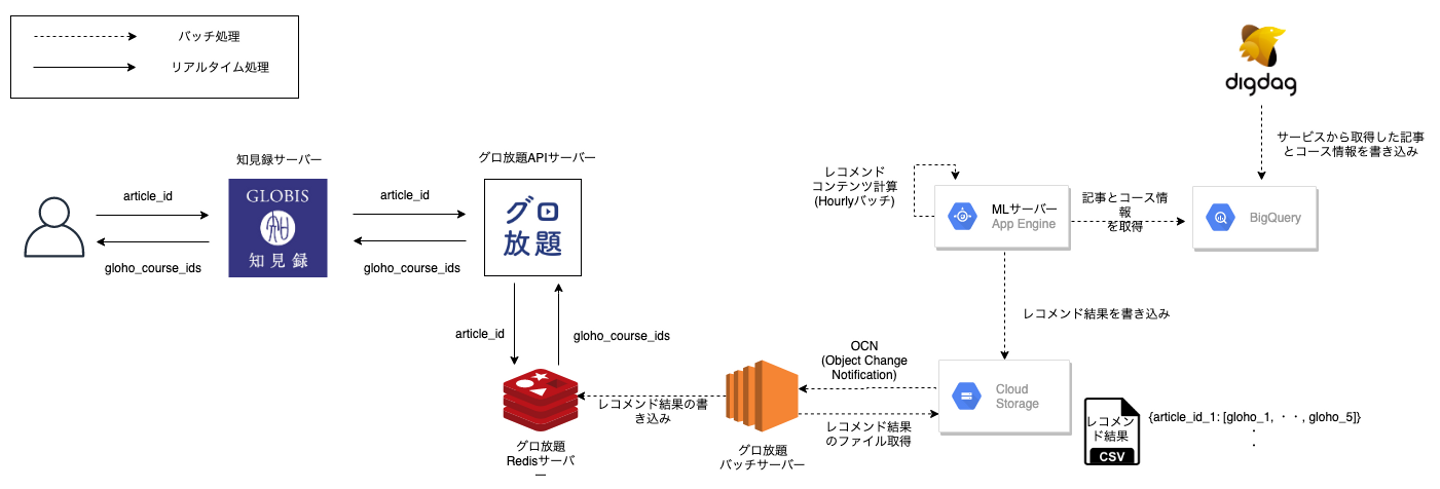
どのようなデータパイプラインにしたか?
データパイプラインは下記のようなファイル連携の形にしました。
リアルタイムの学習や推論が求められるPJTではなかったためです。
機械学習PJTの重視ポイントをどう実践したか?
以上の内容を踏まえて、前述の重視ポイントをどう実践したかを説明します。
表形式で若干見にくいですが、下記のような形で実践しました。

いずれも大事なポイントだと思いますが、今回特に重視したポイントは以下2つになります。
1.簡単なアルゴリズムでも良いので早期リリースを目指す。
2.自チームのみの対応でアルゴリズム改良が可能なデータパイプラインにする。
60点の出来でも良いのでアルゴリズムのシステム導入が実現できれば後から改良する事は可能ですし、収集したログを使って更にアルゴリズム性能を上げていくという良い改善サイクルを作る事が出来るからです。
さいごに
今回は機械学習PJTを進める際に気をつけているポイントを紹介させて頂きました。
本当は実践例として紹介した機械学習PJTの結果もお伝えしたいのですが、まだリリース前となっているのでこちらは後日紹介出来ればと思っています。(近日リリース予定です)
今回のPJT紹介からもわかるように、グロービスでは機械学習を始めとしたデータ活用のホワイトスペースが非常に大きいです!
引き続きデータ系ポジションで募集を行っていますので、少しでも興味を持って頂けたら気軽に話を聞きに来て下さい!

/assets/images/17478267/original/811c7fd1-005f-481d-abba-454cd7a7ed9e?1711958341)





/assets/images/17478267/original/811c7fd1-005f-481d-abba-454cd7a7ed9e?1711958341)


