こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。
この記事では、相互推薦のスコア集約をマルチタスク学習で代替する検証の事例についてご紹介しようと思います。
目次
相互推薦システムと集約関数
集約関数
MIRROR
簡易実装
実データでの評価
まとめ
相互推薦システムと集約関数
相互推薦システム (Reciprocal Recommender System) はジョブマッチングやオンラインデーティングサービスなど、2種類のユーザーが互いを評価・選択する場面で、双方の嗜好やマッチング成立の可能性を同時に考慮する推薦システムです。
相互推薦では、ジョブマッチングにおける求職者と企業、デーティングサービスにおける男性と女性のように、2種類のユーザー双方のマッチングを成立させるために、一方からもう一方に関する嗜好をそれぞれ算出し、それらを集約することで双方のユーザーの嗜好が合致するであろうペアの優先順位に従って推薦を行います。
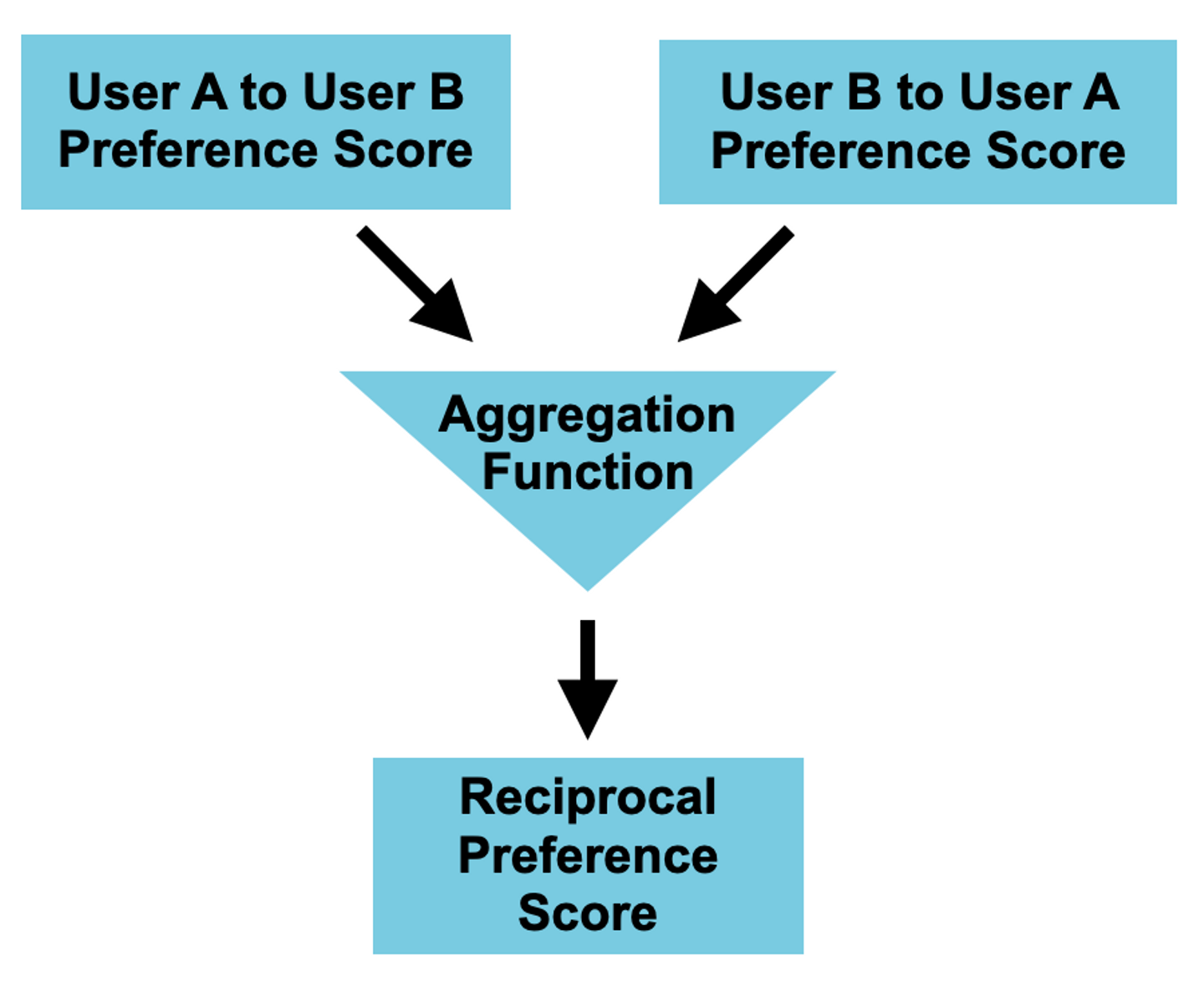
モデル構成は下記の概念図のようになっていることが一般的です。
![]()
相互推薦では2種類のユーザーのスコアを計算する構造が前提になっている一方で、最終的にスコアに基づいて推薦するアイテムの並び替えを行う必要があるため、2種類のスコアを1つにまとめる集約関数が必要になる特徴があります。
集約関数
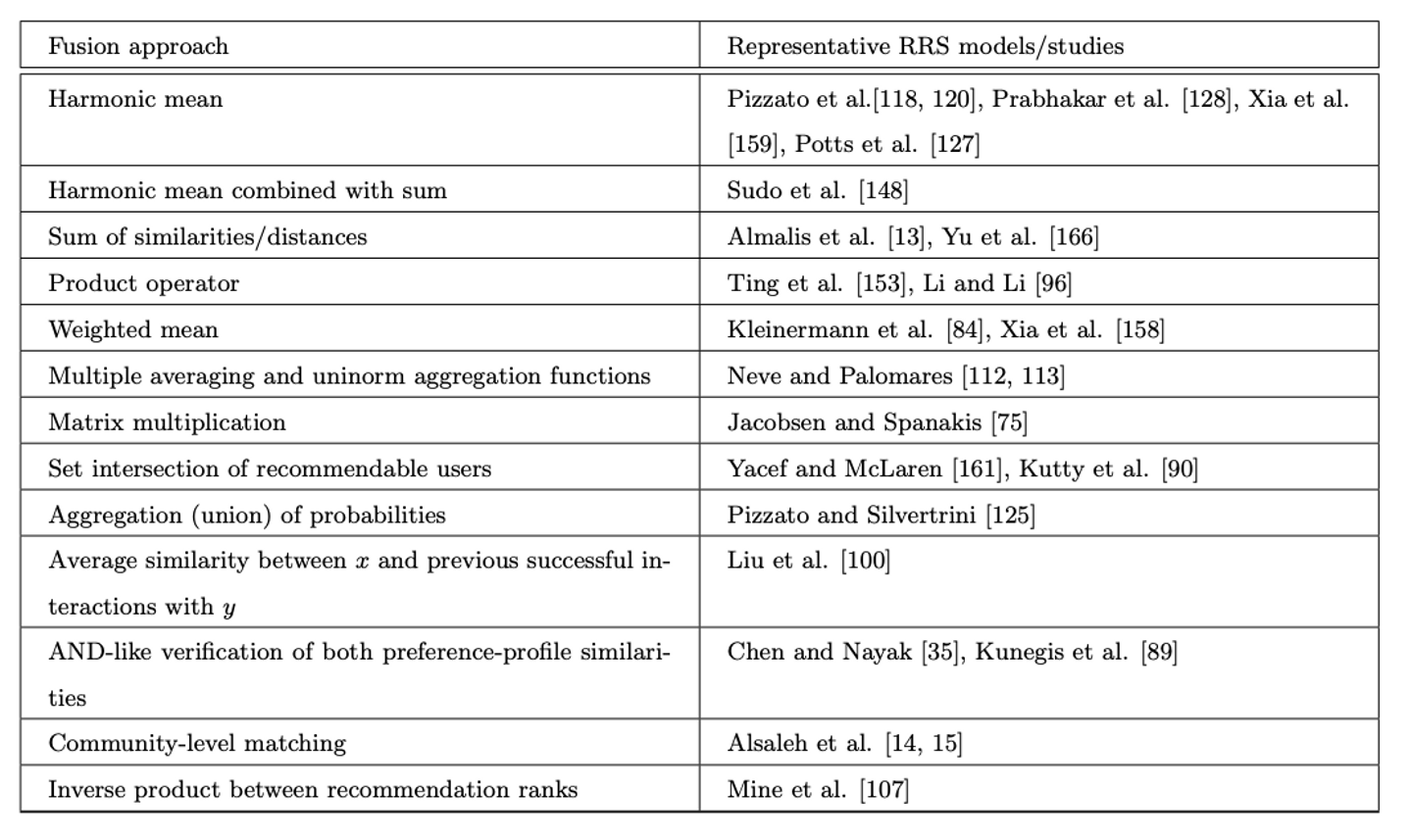
相互推薦システムの集約関数については過去の研究でも様々な手法が使われており、相互推薦システムのサーベイ論文によれば下記の表に示すように多岐にわたっているようです。
![]()
"Reciprocal Recommender Systems: Analysis of State-of-Art Literature, Challenges and Opportunities on Social Recommendation" より引用
しかしながら、これらの集約関数はどれも万能ではなく一長一短です。例えば、ログデータ自体に偏りがある場合には、一方のscoreが高くもう一方のscoreが相対的に低く算出されることもあります。この場合に一般的な集約関数をそのまま使うと一方の嗜好が過剰に重要視されてしまい、結果的にマッチングしにくくなることがあり、集約関数も推薦タスクに応じて調整が必要になることがあります。
このような問題については過去に研究の取り組みも公開していますので、よろしければこちらもご参照ください。
また、推薦するユーザーごとに2つのscoreのどちらを優先すべきかが異なる場合も考えられます。ジョブマッチングの場合で言えば、積極的にジョブに応募するユーザーに対しては、多少応募確率は低くとも返信される可能性の高いジョブを推薦したほうが最終的なマッチングにつながりやすいかもしれません。逆に、応募自体に慎重なユーザーであれば応募確率が高いジョブを推薦することを優先して応募のハードルを下げることが有効な場合もあるかもしれません。そのため、集約の振る舞いもユーザーごとに最適な形が異なることも予想できます。このような相互推薦の集約関数をパーソナライズする取り組みについては、下記の記事でも紹介していますので併せてご参考ください。
MIRROR
上記のような問題に関連して、SIGIR'24で発表された"MIRROR: A Multi-View Reciprocal Recommender System for Online Recruitment"では、集約関数ではなくマルチタスク学習によって最終的なscoreを計算するアプローチを取っています。
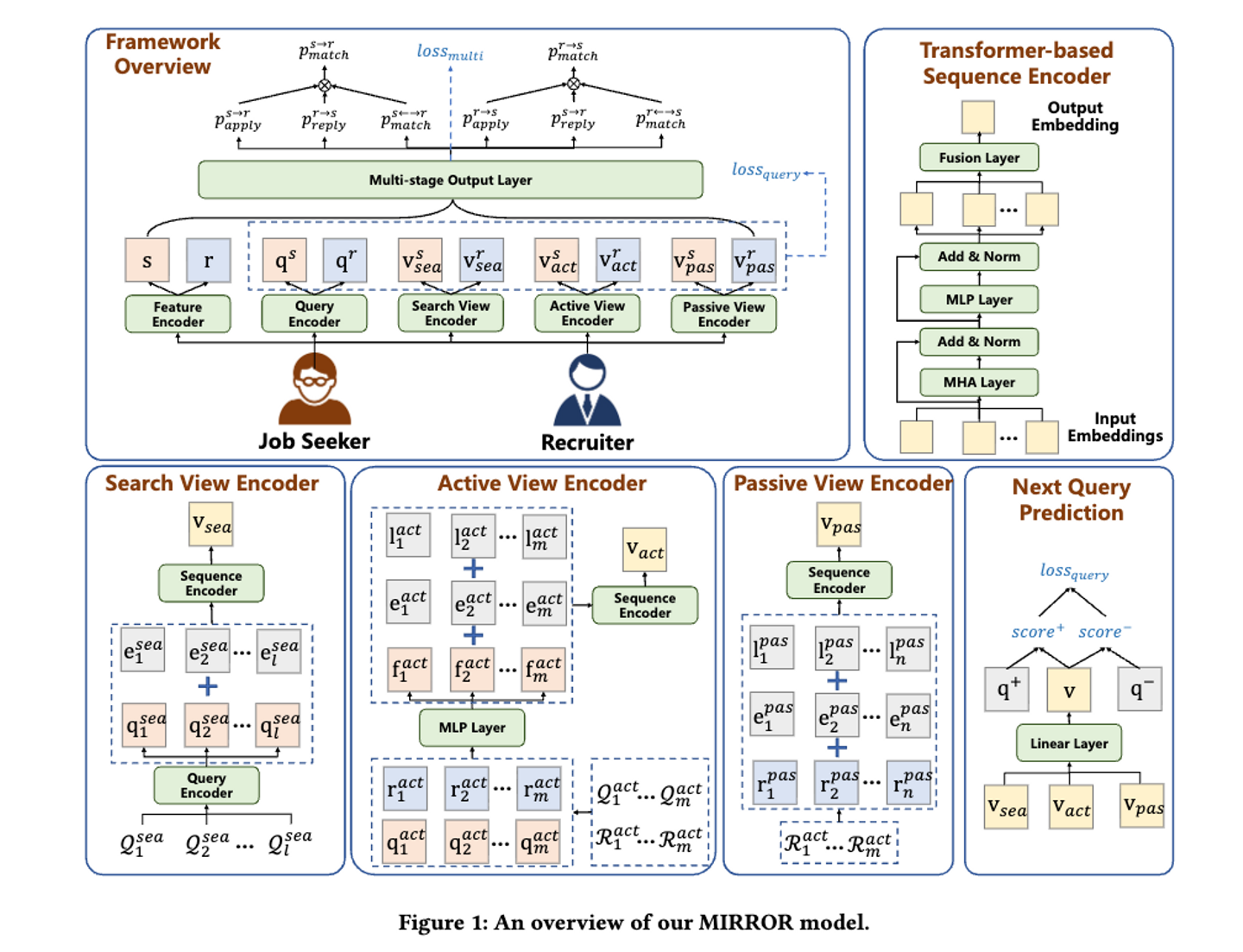
MIRRORの概念図は下記のようになっています。
![]()
"MIRROR: A Multi-View Reciprocal Recommender System for Online Recruitment"より引用
求職者と採用担当者のマッチングを相互推薦によって解消するアプローチではありますが、集約関数ではなくMulti-stage Output Layerを使用しています。これにより、最終的な「マッチング」だけでなく「応募」や「返信」といった中間段階の豊富なデータを学習に活用することできるようになり、最終的なマッチングデータが極端に少ないという「データの疎性(Data Sparsity)」の問題に対応しています。
簡易実装
この記事では、マルチタスク学習による各scoreと集約を同時に計算するアプローチが社内のデータに適用可能かどうかについて検証してみようと思います。
MIRRORの実装自体は集約関数の工夫以外にもEncoderの実装なども考慮した作りになっており、これをそのまま社内のデータに適用するには実装規模が大きくなってしまいます。今回は、マルチタスク学習による集約が社内の相互推薦に対して有効なのかを検証すべく簡易的な実装に書き換えてみようと思います。
ここでは、マルチタスク学習を行うためにXGBoostのマルチタスク学習の設定を利用して検証を行ってみようと思います。XGBoostでは、下記のように multi_strategy=multi_output_tree を使うことで、1つの木で複数種類の推論を同時に行うマルチタスク学習を行うことができます。
clf = xgb.XGBClassifier(
tree_method="hist",
multi_strategy="multi_output_tree"
)
今回はXGBoostのマルチタスク学習の機能を使って簡易実装を進めました。
実データでの評価
今回は通常通り相互推薦を行った結果と比較してみたいと思います。Wantedlyのスカウトに関するデータを用いて、使用する特徴量についてはすべて同じものを使用し、集約関数だけを下記の4パターンに変えて比較してみようと思います。
- 会社→ユーザーの嗜好スコアのみ使用
- ユーザー→会社の嗜好スコアのみ使用
- 調和平均
- マルチタスク学習
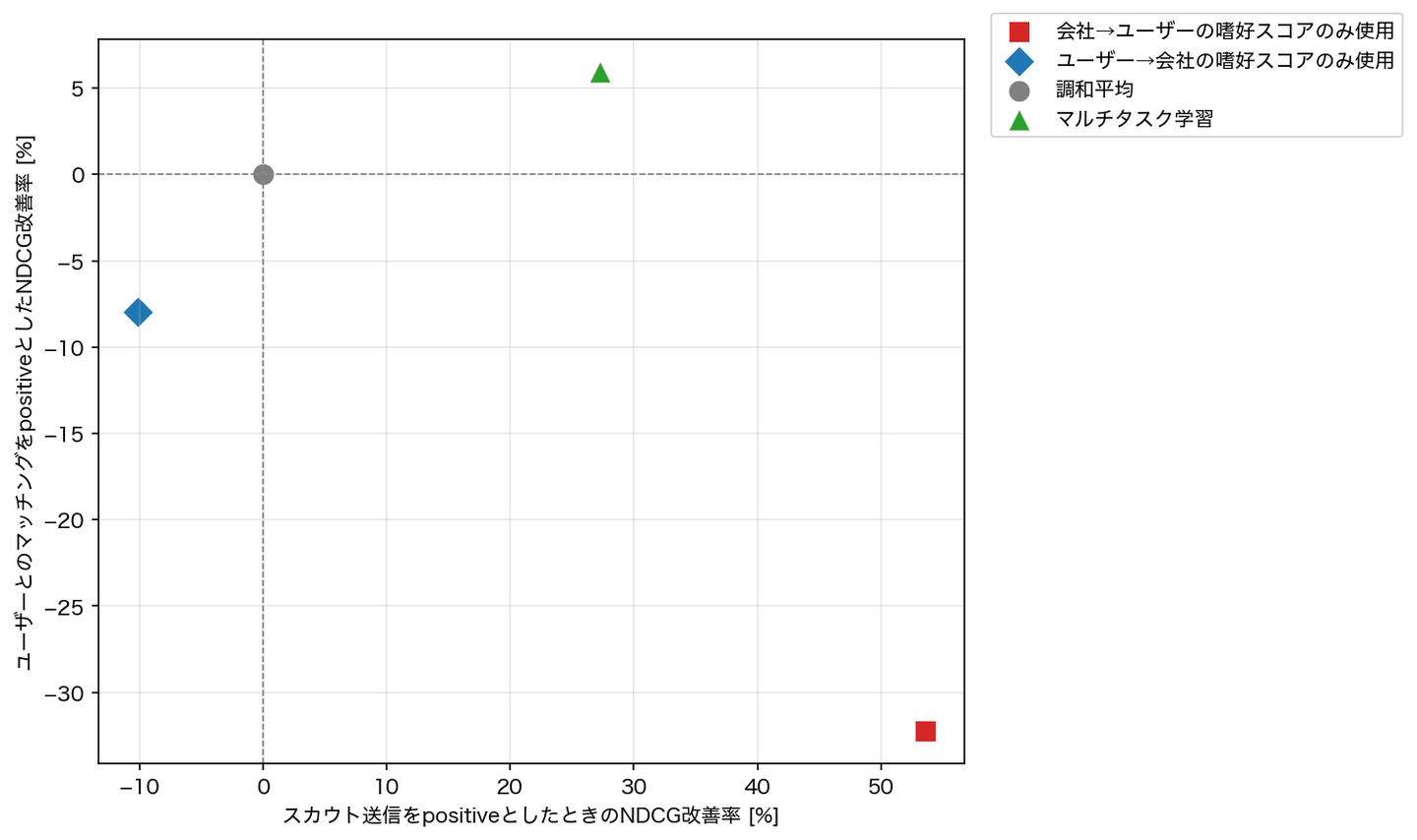
これらのパターンについて、スカウト送信をpositiveとしたときのnDCG (ランキングの並びの良さを示す指標)、ユーザーとのマッチングをpositiveとしたnDCGそれぞれについて、調和平均のスコアを基準に整理すると下記のようになりました。
![]()
調和平均を基準に考えると、会社→ユーザーの嗜好スコアのみを使用してランキングを作ると、スカウト送信をpositiveとしたときのnDCGは最大になり会社のスカウト担当者からの見え方は良いようです。一方で、ユーザーからの反応については考慮できていないので、ユーザーとのマッチングは調和平均より悪化する結果になっています。
逆に、ユーザー→会社の嗜好スコアのみを使用した場合は、会社→ユーザーの嗜好スコアのみを使用した場合よりユーザーとのマッチングをpositiveとしたnDCGは改善するものの、スカウト送信をpositiveとしたときのnDCGが悪化しています。このように相互推薦においては両者の嗜好スコアのバランスを取ることが重要になってきます。
今回のマルチタスク学習では、スカウト送信をpositiveとしたときのnDCG、ユーザーとのマッチングをpositiveとしたnDCGの両者が改善しており、机上評価では単純な調和平均より良くなっていそうなことがわかりました。
まとめ
今回は相互推薦のスコア集約をマルチタスク学習で代替する検証を行った事例についてご紹介しました。実際に社内のデータを使った検証を行ったところ悪くなさそうな結果だったので、細かいところを精査して今後どこかで使えないか検討してみようと思います。
ウォンテッドリーでは、ユーザーにとってより良い推薦を届けるために日々開発を行っています。ユーザーファーストの推薦システムを作ることに興味があるという方は、下の募集の「話を聞きに行きたい」ボタンから気軽に話を聞きに来ていただけるとうれしいです!
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

