
こんにちは、ウォンテッドリーでソフトウェアエンジニアをしている市古 (@sora_ichigo_x) です。現在は Visit AI Squad で AI エージェントモードといった LLM を活用した機能の開発をリードしています。
目次
はじめに
LLMアプリケーションにおける自動テストの課題
LLM パイプラインの複雑性
手動テストの非効率性
単にモックを外しても解決しない
課題解決のアプローチ
スナップショットテストの導入
技術選定:なぜ RSpec に乗せたか
ディレクトリ設計と CI/CD との棲み分け
スナップショット差分レビューのワークフロー
LLM as a Judge の導入
LLM as a Judge という考え方
自然言語で期待値をかけるカスタムマッチャー
スナップショット記録との組み合わせ
現在の課題と今後の展望
スナップショット数の増加
LLM as a Judge 自体の精度
LLM as a Judge の濫用リスク
完璧な解はない
はじめに
LLM アプリケーションの自動テストは、従来のセオリーに従うだけではうまくいきません。
自動テスト戦略には「テストピラミッド」と呼ばれる考え方があります。ビジネスロジックや分岐の検証はユニットテストが担い、結合テストや E2E テストはコンポーネント間の連携確認に留める、という役割分担です。また、ユニットテストでは外部 API をモックして安定性と実行速度を確保するのが一般的です。
しかし LLM アプリケーションでは、この考え方がうまく当てはまりません。LLM プロンプトはビジネスロジックそのものなので、本来ユニットテストで検証したい対象です。一方で LLM は外部 API でもあるため、セオリーに従えばモックすべき対象でもあります。つまり、ビジネスロジックを検証しようとすると、その検証対象をモックで潰してしまう、という問題が起きます。
本記事では、この課題に対して私たちのチームが取り組んできたアプローチを紹介します。LLM をモックしない専用テスト環境の構築から、LLM as a Judge(別の LLM に出力を判定させる手法)の導入まで、段階的に改善してきた経験をお話しします。
LLMアプリケーションにおける自動テストの課題
前章で述べたように、LLM アプリケーションでは「ビジネスロジックを検証したいが、その対象が外部 API (= LLM) である」という問題があります。ここでは、私たちのチームが実際に直面した課題をもう少し具体的に説明します。
LLM パイプラインの複雑性
昨年リリースした AI エージェントモードでは、ユーザー入力に応じて候補者リストを出力するまでに複数の LLM ステップを経由します。たとえば、ガードレールによる入力チェック、検索クエリの生成、ソートアルゴリズムの生成、といった具合です。これらのステップは前のステップの出力を入力として受け取るため、1つの LLM タスクの変更が後続のタスクの挙動に波及します。
この依存関係があるため、プロンプトやモデルを変更した際に「どこで何が壊れたのか」を特定するのが難しくなります。あるステップの出力が微妙に変わっただけで、最終的な結果が大きく変わることもあります。
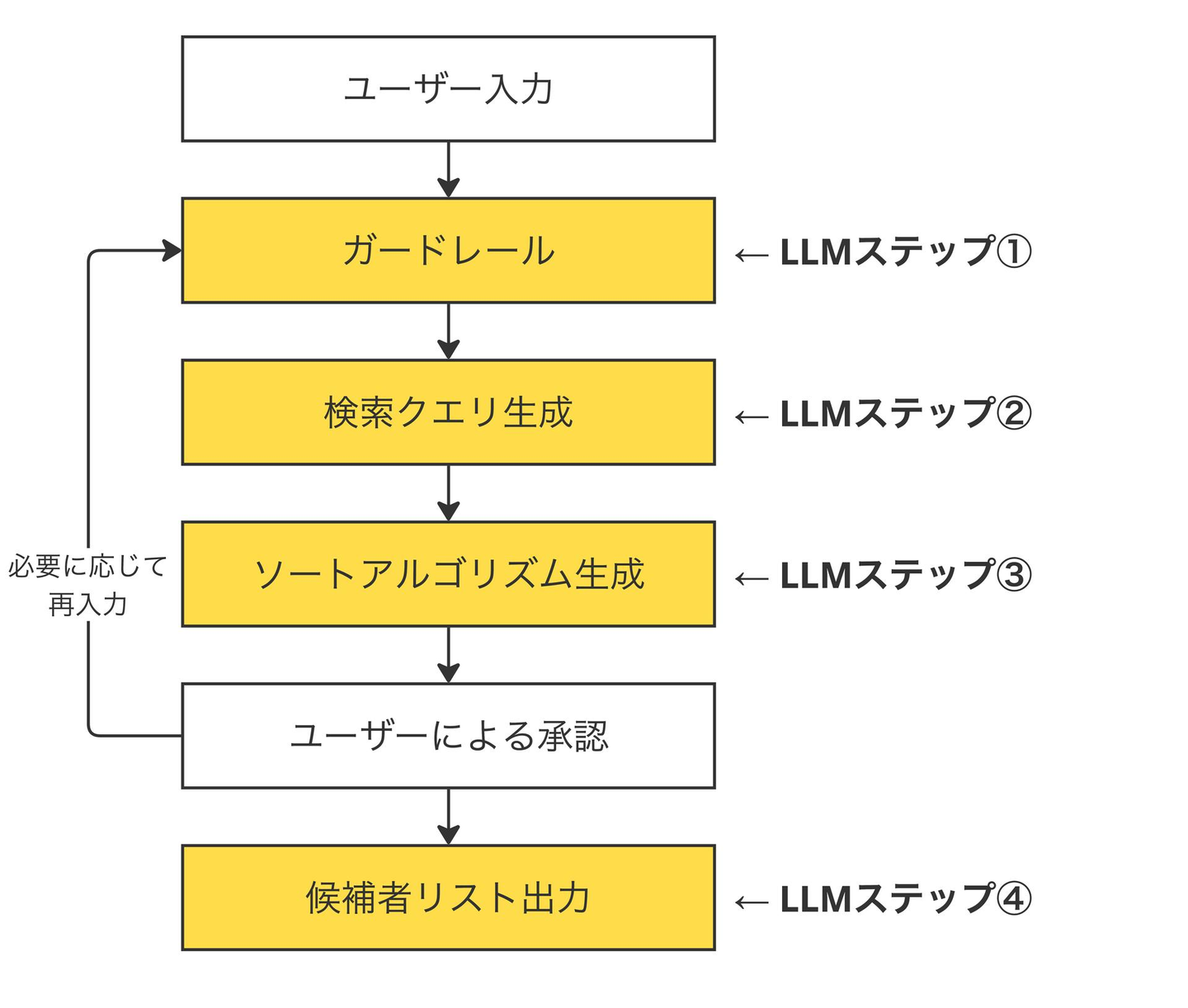
手動テストの非効率性
当初は、プロンプトを変更するたびに開発者が手動で動作確認を行なっていました。しかし、1つの応答を作成するのに数分程度かかり、複数パターンを試すと数十分が費やされます。パターン数が増えるにつれてこのやり方はスケールしなくなり、結果として「ちょっとした改善を試しずらい」「リリース後にデグレが発覚する」といった問題が起きていました。
単にモックを外しても解決しない
では、LLM の入出力をモックせずに自動テストを書けば良いかというと、そう単純ではありません。LLM の出力には非決定性があり、同じ入力でも毎回微妙に異なる出力が返ってきます。これにより、以下のような問題が発生します。
- テストが頻繁に落ちる (出力のわずかな揺れで失敗する)
- 期待値を「値が null でないこと」のように大雑把にせざるを得ない
- スナップショットテストを導入しても、差分を毎回人間がチェックする負荷が高い
つまり、モックを外すだけでは「不安定なテスト」か「検証不十分なテスト」のどちらかになってしまい、効果的な自動テストにはなりません。
次章以降では、この問題に対して私たちのチームがどうアプローチしたかを紹介します。
課題解決のアプローチ
前章で述べた課題を整理すると、解決したい課題は以下の2点です。
- プロンプトやモデル、ワークフローを変更した際に、デグレを早期に検出したい
- 手動テストに頼らず、自動化された仕組みでスケールさせたい
これらの課題に対して、私たちのチームでは2段階のアプローチで取り組むことにしました。
第1段階:LLM をモックせずにテストを実行し、出力をスナップショットとして記録する第2段階:スナップショットのレビューを人間でなく LLM に任せる (LLM as a Judge)
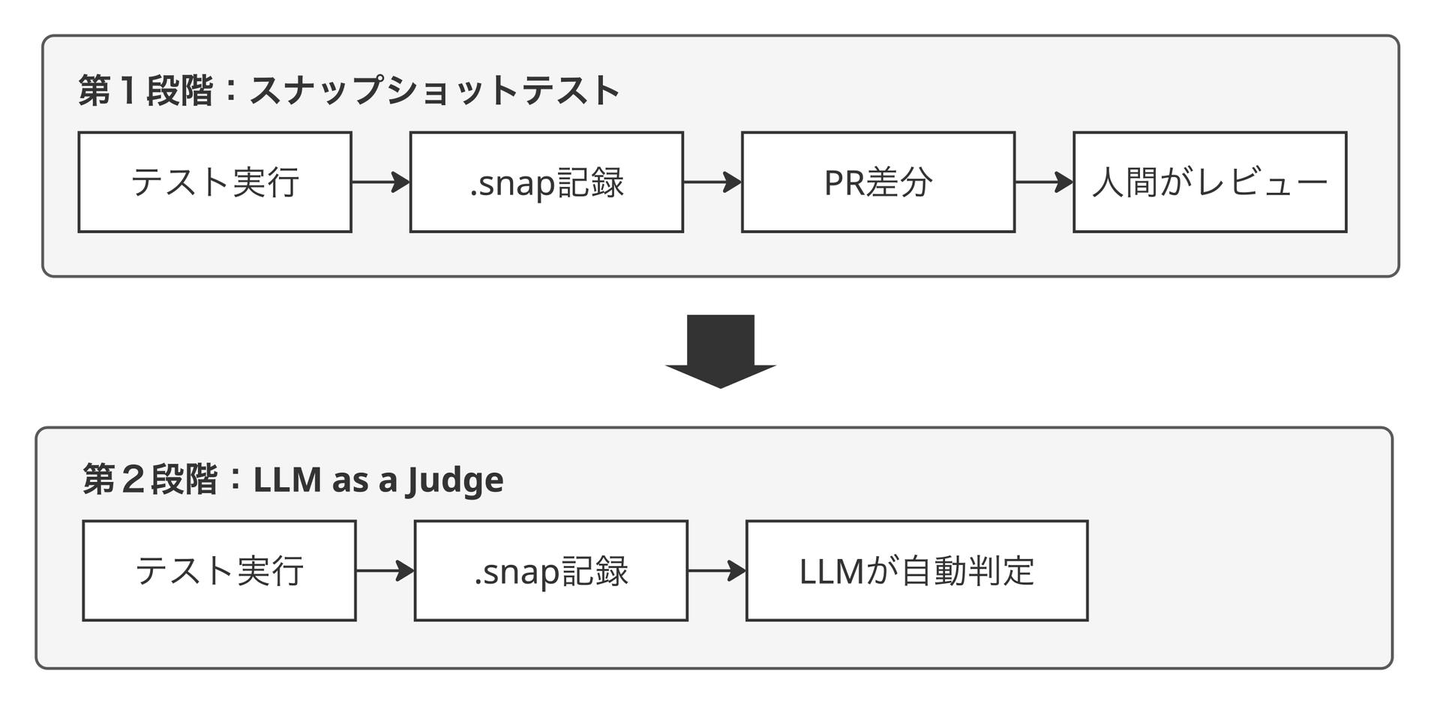
スナップショットテストの導入
本章ではまず第1段階について説明します。第1段階だけでも手動テストからの解放やデグレの可視化といった効果がありますが、LLM 出力の非決定性により「差分を人間がチェックする負荷」という課題が残ります。この課題を解決する第2段階の LLM as a Judge は次章で扱います。
前提として、ウォンテッドリーのバックエンドは Rails / RSpec で構成されており、LLM は Amazon Bedrock 経由で利用しています。この環境を活かしつつ、既存の開発フローに無理なく組み込める形を目指しました。
技術選定:なぜ RSpec に乗せたか
LLM の出力を検証する仕組みを作るにあたり、これを実行・記録する基盤としていくつかの選択肢を検討しました。
- 外部ツール (LangSmith、Promptfoo など):LLM の評価に特化したツールは存在しますが、Ruby 対応が限定的であり、既存の開発フローに組み込む導入コストが高いと判断しました。
- 専用バッチスクリプト:シンプルに作れる一方で、データのセットアップやクリーンアップを自前で実装する保守コストが許容できないと判断しました。
- 既存の RSpec に乗せる:すでにチームが慣れ親しんだテストフレームワークであり、テスト実行のセットアップ・クリーンアップを RSpec の標準機能で統一的に管理できます。
特に、テスト対象は LLM "プロンプト" ではなく LLM "アプリケーション" であり、テスト実行に必要なデータ管理をシンプルに書けることは重要な評価観点でした。結論として、特に大きな懸念がなかったこともあり RSpec に乗せる方針を採用しました。
ディレクトリ設計と CI/CD との棲み分け
LLM をモックしないテストは、通常のユニットテストとは性質が異なります。実際に Bedrock API を呼び出すため、テスト実行ごとに API コストが発生し、実行時間が増加します。
そこで、これらのテストは spec/llm_integration/ という専用ディレクトリに配置し、RSpec タグ (llm_integration: true) で通常のテストと分離しました。CI/CD では自動実行せず、プロンプト変更時や定期的なデグレチェックなど、必要なタイミングで手動実行する運用としています。
# spec/llm_integration/your_feature_spec.rb
RSpec.describe 'Your Feature LLM Integration', llm_integration: true do
it 'generates expected output' do
result = YourService.call(...)
output = JSON.pretty_generate(result)
# スナップショットとして記録(この時点では人間がレビュー)
record_llm_output(output)
end
end# spec/spec_helper.rb
RSpec.configure do |config|
# デフォルトでは llm_integration タグ付きのテストをスキップ
config.filter_run_excluding llm_integration: true unless ENV['RUN_LLM_INTEGRATION_TESTS']
end実行時は専用スクリプトを使い、Bedrock の認証情報を自動で設定した上でテストを走らせます。
# 特定のファイルを実行
./script/run_llm_integration_tests.sh spec/llm_integration/your_feature_spec.rb
# 全ての LLM 統合テストを実行
./script/run_llm_integration_tests.shスナップショット差分レビューのワークフロー
テスト実行時には、LLM の出力をスナップショットとして spec/llm_integration/__llm_outputs__ 配下に .snap ファイルとして保存します。このファイルは Git にコミットしておき、GitHub Pull Request の差分で LLM の振る舞いの変化を確認できるようにしています。
このワークフローにより、以下のことが可能になりました。
- 手動テストからの解放:プロンプト変更のたびに手動で確認する必要がなくなる
- デグレの可視化:出力の結果が PR 差分として見えるため、意図しない変化に気づきやすい
- 変更履歴の追跡:GIt の履歴を遡れば、いつどのような出力の変化があったかを確認できる
LLM as a Judge の導入
前章で紹介したスナップショット差分レビューにより、手動テストの負荷は大きく減りました。しかし、LLM の出力には非決定性があるため、意味的には同じ内容でも表現が微妙に異なることがあります。たとえば「バックエンドエンジニアを募集しています」と「バックエンドエンジニアの募集です」は意味としては同じですが、スナップショットとしては差分が出ます。
このような差分が発生するたびに、「この差分は問題ないのか」を人間が判断する必要があります。テストケースが少ないうちは対応できますが、LLM アプリケーションがスケールしてくると、この判断の負荷が無視できなくなります。
LLM as a Judge という考え方
この課題に対して導入したのが LLM as a Judge[1] です。これは、テスト対象の LLM とは別の LLM を「判定者 (Judge)」として使い、出力が期待を満たしているかを自動判定させる手法です。これにより、表記の揺れを吸収しつつ、意味的な検証を自動化できます。
当社では Judge 用の LLM として Claude Haiku 4.5 を使用しています。テスト対象の LLM アプリケーションとは独立して軽量なモデルを使うことで、コストと実行速度を抑えています。
[1] Gu, J. et al., "A survey on LLM-as-a-judge", arXiv:2411.15594 (2024)
自然言語で期待値をかけるカスタムマッチャー
私たちのチームでは LLM as a Judge を RSpec から利用しやすくするために専用のカスタムマッチャー (RSpecの検証用オブジェクト) を実装しました。
例えば satifsy_natural_expectation というマッチャーを使うと、期待値を自然言語で記述できます。
# spec/llm_integration/your_feature_spec.rb
RSpec.describe 'Your Feature LLM Integration', llm_integration: true do
it 'generates expected output' do
result = YourService.call(...)
output = JSON.pretty_generate(result)
expect(output).to satisfy_natural_expectation(
expected: '期待される内容が含まれている',
not_expected: '禁止された内容が含まれる'
)
end
endexpected には「出力に含まれていてほしい要件」を、not_expected には「出力に含まれていてほしくない要件」を自然言語で記述します。Judge 用の LLM がこれらの要件に基づいて出力を評価し、合否を判定します。
シンプルな期待値であれば、文字列を直接渡すこともできます。
expect(output).to satisfy_natural_expectation('ユーザー情報が含まれている')現在は他にも、事前に用意した正解データから判定を行うマッチャーなどを検討しています。
スナップショット記録との組み合わせ
LLM as a Judge を導入した後も、スナップショットの記録は継続しています。テスト実行時には、Judge による合否判定とは別に、LLM の出力を .snap ファイルとして保存されます。
この設計により、以下の運用が可能になっています。
- 自動判定:通常のテスト実行では、Judge が合否を判定するため人間の介入は不要
- 詳細確認:テストが失敗した場合や、出力の変化を詳しく確認したい場合は、スナップショットを見て実際の出力を確認できる
- 履歴追跡:Git の履歴を通じて、出力がどのように変化してきたかを追跡できる
また、詳細確認と履歴追跡に関しては人間ではなく Coding Agent に指示して確認させることも多いです。ファイルとして出力しておくと、Coding Agent がそれを読み込んで開発を進めてくれるという利点もあります。
このように LLM as a Judge による自動判定とスナップショットによる可視化を組み合わせることで、効率的かつ透明性のあるテスト運用を実現しています。
現在の課題と今後の展望
ここまで紹介してきた2段階のアプローチにより、LLM アプリケーションの自動テストは大きく改善しました。しかし、運用を続ける中で新たな課題も見えてきています。
スナップショット数の増加
LLM アプリケーションがスケールするにつれて、スナップショットの数も増加しています。LLM as a Judge による自動判定があるとはいえ、テストが失敗した際や出力の変化を確認したい際には、人間がスナップショットを見る必要があります。
現状では「必要な分だけスナップショットを更新する」という運用で認知負荷を抑えていますが、影響範囲を常に読み切れるわけではありません。将来的には LangSmith のような LLM Obserbability サービスの導入も選択肢として検討しています。
LLM as a Judge 自体の精度
LLM as a Judge は万能ではありません。Judge 用の LLM も間違えることがあり、本来 OK であるべき出力を NG と判定したり、その逆が起きることもあります。特に、期待値の記述が曖昧な場合や、判定基準が微妙なケースでは精度が落ちる傾向があります。
現状では、期待値をできるだけ明確に記述すること、テストが失敗した際はスナップショットを確認して Judge の判定が妥当かを検証することで対応しています。Judge の精度を上げるための基盤改善は継続的な取り組みになっています。
LLM as a Judge の濫用リスク
もう1つの課題は、LLM as a Judge が本来の設計意図と異なる使われ方をしてしまうリスクです。
LLM as as Judge は「LLM 出力の非決定性により、従来のマッチャーでは検証が難しいケース」のために導入しました。しかし、設計意図がチーム内で正しく共有されていないと、従来の eq や include で十分なテストまで LLM as a Judge で書いてしまう、ということが起こりえます。
LLM as a Judge は便利ですが、従来のマッチャーに比べて実行コストが高く、判定の透明性も低くなります。「LLM の出力を検証するから LLM as a Judge を使う」ではなく、「従来のマッチャーでは検証できないから LLM as a Judge を使う」という判断基準をチーム内で共有することが重要です。
完璧な解はない
LLM アプリケーションのテスト戦略には、まだ業界全体で確立された正解がありません。本記事で紹介したアプローチも、私たちのチームが試行錯誤の中でたどり着いた1つの形であり、完璧なものではありません。
それでも、段階的に課題を特定し、改善を重ねていくアプローチは有効だと考えています。同じような課題に直面しているチームにとって、本記事が何かのヒントになれば幸いです。
/assets/images/17704487/original/a231bd7f-ab14-4d6b-af89-1cd90207ec99?1753696825)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


