


AWS Summit Japan 2026
AWS SummitJapan | 2026年6月25日~26日、幕張メッセにてご参加ください。基調講演、260以上のセッション、Agentic AI、ネットワーキングの無料イベントです。ご登録はお早めに!
https://aws.amazon.com/jp/events/summits/japan/
こんにちは、ウォンテッドリーでバックエンドエンジニアをしている小室 (@nekorush14) です。先日 2026年6月25・26日に開催された AWS の年次イベントの1つである「AWS Summit Japan 2026」に、小室、市古 (@sora_ichigo_x)、池田(@ikedams_x)の3名で参加してきました。
本記事では、6月25日、6月26日に参加した中で、それぞれが注目したセッションやブースでの気づき、イベントを通して得たインサイトを3名それぞれの視点でお届けします。
AWS Summit Japan とは
セッション聴講レポート
Day1 - マルチエージェントシステムの設計パターン 3 選! (小室)
Day1 - AWS サービスを使ったエージェントのメモリ実装パターン (市古)
Day1 - マルチキーサポートで変わる Amazon DynamoDB の GSI 戦略 (市古)
Day2 - 本番運用を見据えた AI エージェント - Amazon Bedrock AgentCore を活用したベストプラクティス (小室)
Day2 - 生成 AI で「売れる製品」を作る ― PoC 止まりを突破する 6 つのプロダクトデザイン戦略 (池田)
Day2 - スタートアップのための速習AI-DLC (池田)
ブースでの展示の様子
まとめ
AWS Summit Japan は AWS が日本で開催するクラウドテクノロジーに関するイベントです。
イベントでは AWS の技術をどのように導入したかなどの事例や企業ごとのセッション、AWS のソリューションアーキテクトによる技術的な解説のほか、ワークショップやハンズオンに参加できます。
また、ブースでは実際に AWS のソリューションアーキテクトに直接質問でき、学びを深められます。
今回は特に Amazon Bedrock AgentCore や、AWS が OSS として公開している AI 駆動開発サイクルである AI-DLC Workflows を題材にした事例が、各セッションや展示で多く紹介されていました。
ここからは、小室、市古、池田の3名が、それぞれ印象に残ったセッションについて紹介します。
このセッションでは、AI エージェントの設計パターンを3つ挙げ、Amazon Bedrock AgentCore で適用する際のアーキテクチャについて紹介されました。ここでは、マルチエージェントの構成パターンを以下の3つに分類しています。
Supervisor パターンは Strands Agents では Agent as Tools に該当し、複数のタスク特化型のエージェントを取りまとめるオーケストレーターが各処理結果を統合する構成になっています。
また、事例の紹介では、「ワークフロープロンプト」と呼ばれるオーケストレーターがどのようにタスクを分解・移譲するのかを定義したプロンプトと Supervisor パターンを組み合わせた設計が紹介され、より複雑だが非決定性を低減したいワークロードで有効に作用しそうだと感じました。
参考資料:
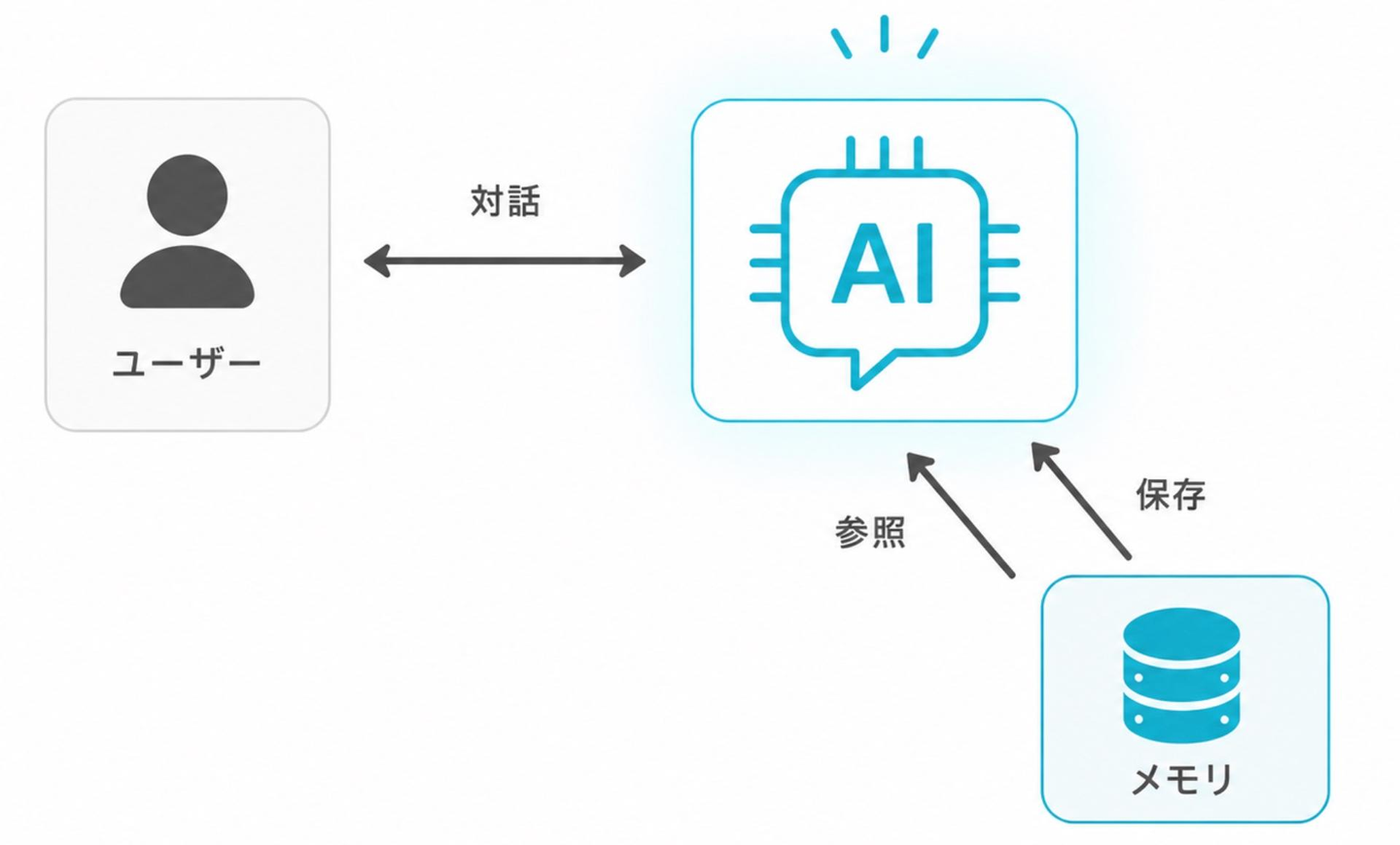
このセッションでは、AI エージェントにおける「メモリ」の概念や分類、設計パターンが紹介されていました。
過去の会話を全部プロンプトに入れると、トークンが増えてコストとレイテンシーが上がり、無関係な情報が混じって精度も落ちます。そのため、情報を整理して保存し、必要なときだけ取り出す仕組みが要ります。
個人的には、メモリを役割で3種類に分け、それぞれ適切なデータストア選定を行う必要があるという主張が印象的でした。
ウォンテッドリーでもいくつかの AI プロダクトでメモリ実装を行っているため、今後の参考にしようと思います。
参考資料:
このセッションでは、2025年11月に発表されたGSI のマルチアトリビュート複合キーを題材に、これまでの設計がどう変わるかが解説されていました。
従来の DynamoDB の検索はパーティションキーを1つの値に完全一致で固定するのが必須で、それ以外を入口にすると全件走査になります。
そのため、複数の属性で絞りたいとき、これまでは値を連結した属性(例: Country#State#City)を自前で作ってソートキーにする「合成キー」アプローチが一般的でした。
const item = {
country: "JP",
state: "Tokyo",
city: "Shibuya",
// GSI 用に連結した属性を持たせる
locationKey: "JP#Tokyo#Shibuya",
};
await putItem(item);
await query({
IndexName: "LocationIndex",
KeyConditionExpression: "locationKey = :locationKey",
ExpressionAttributeValues: {
":locationKey": "JP#Tokyo#Shibuya",
},
});しかし、このアプローチには以下の欠点があります。
今回 マルチキーがサポートされ、PK と SK にそれぞれ最大4属性ずつを指定できるようになったことで、既存の多くの合成キーを廃止できます。
const item = {
country: "JP",
state: "Tokyo",
city: "Shibuya",
};
await putItem(item);
await query({
IndexName: "LocationIndex",
KeyConditionExpression: `
country = :country
AND #state = :state
AND city = :city
`,
ExpressionAttributeNames: {
"#state": "state",
},
ExpressionAttributeValues: {
":country": "JP",
":state": "Tokyo",
":city": "Shibuya",
},
});私たちは普段の開発では RDB を前提に設計することが多く、正規化されたデータモデルを起点に、SQL やインデックスでさまざまなアクセスパターンに対応する考え方に慣れています。
一方で DynamoDB では、事前に想定したアクセスパターンから逆算してキーや GSI を設計する必要があります。ユースケースに特化したデータ配置によって、高スループットと大規模スケールを両立するという、RDB とは異なる設計思想を学ぶことができました。
参考資料:
このセッションでは、AI エージェントをビジネスで活用する際に検討するべき9つのベストプラクティスについて紹介されていました。AI エージェントのロジックや LLM の選定などに注力しがちですが、本番で運用するためにはそのほかにも多くの考慮事項があり、ここではそれぞれを「1. 基盤を作る」、「2. 高品質に磨く」、「3. 継続運用する」の3つに分類していました。
この中で特に重要だと感じたのは「課題から逆算して小さく始める」と「オブザーバビリティを初日から設定する」です。
「課題から逆算して小さく始める」では、始めに「エージェントがすること・しないことを明確に定義」し、あらかじめ「期待されるやりとりの正解データを定義」することが挙げられていました。確かに、ゴールが明確になっていないと意図しない挙動をする、あるいは想定と全く異なるエージェントが出来上がる可能性が高いため、この観点で小さく始めることは有効だと感じました。
「オブザーバビリティを初日から設定する」では、「フレームワークやサービスが出力するOTel (Open Telemetry) トレース」をデバッグや品質監査、問題の検出、パフォーマンスの把握などに重要であることが挙げられていました。トレース情報を適切に利用することで、アプリケーションの開発者とインフラチームにおいてそれぞれ以下のような利点があります。
これらの利点は開発時に役立つものであり、後回しにせずに設計として組み込むことが重要だと感じました。
参考資料:
このセッションでは、生成 AI をビジネスにつなげるためのプロダクトデザインに焦点を当てて、どのようにすれば PoC 止まりではなく本番で売れる製品につなげることができるのかについて解説されていました。
冒頭では AI スタートアップへの投資額が年々膨らんでいく一方で、半数近くの案件は PoC 止まりで本番にたどり着けていないという実態が具体的な数字とともに紹介され、その解決策として以下の 6 つの戦略が紹介されています。
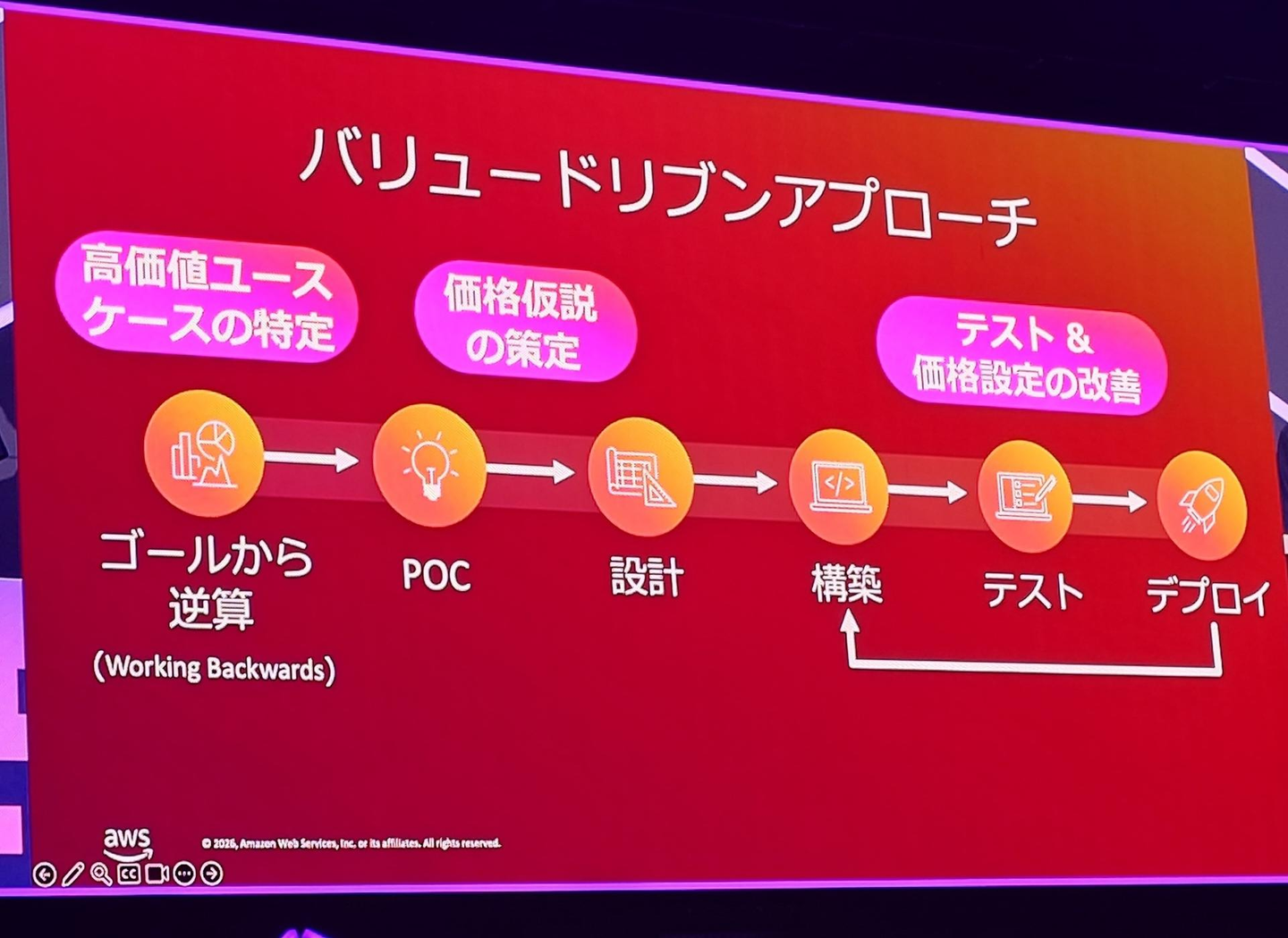
個人的に特に気になったのは、「バリュードリブンアプローチで収益成長を実現する」という点です。テクノロジードリブンアプローチ(PoC → 設計 → 構築 → テスト → デプロイの後にユースケースや価格を検討)ではなく、ゴールから逆算するバリュードリブンアプローチ(高価値ユースケースを特定 → 価格仮説 → PoC → テストと価格改善)という順序が推奨されています。
特に開発者の目線では PoC 段階では意外と価格まで意識できていないケースが多く、こういった考え方はプロダクトが失敗に終わるのを避ける上で重要な視点だと感じました。
このセッションでは、AI-DLC (AI-Driven Development Lifecycle) とは何か、そしてその始め方について分かりやすく解説されていました。
「なぜAIツールを入れても開発プロセスは早くならないのか?」という疑問について、コーディングがソフトウェア開発の約3割だけであり、残りの約7割が保守・テスト・会議に費やされているため、コーディングの改善だけでは全体のボトルネックは解消されない、と説明した上でその解決策としてAI-DLCが紹介されています。
AI-DLC とはAIを介して人間の決定のサイクルを速くするための仕組みのことで、AIが作業計画の作成や実装を行い、開発者とビジネスメンバーは検証、意思決定、監督の最終的な責任を取る、といった考え方です。
また、AIを活用したシステム開発(AI駆動開発)のためのフレームワーク・ワークフローテンプレートとして、awslabs/aidlc-workflows というOSSが公開されているため、こちらをコーディングエージェントに読み込むことですぐ試せます。
AI-DLCの実際の流れとしては、PdM と 3〜10 名の開発メンバーがオフラインで集まり、AI-DLC ワークフローの skills を設定したコーディングツールに「作りたいもの・背景・期限」をプロンプトとして投げ、AI が生成した作業単位をレビューし、実装フェーズで各開発者がAIを使って開発していく、という流れで紹介されていました。
私自身もまずは awslabs/aidlc-workflows を手元のプロジェクトに読み込ませて、新規プロジェクトや個人開発などで実際に試してみたいと思います。
参考資料:
セッション以外にも、製造業などに特化した展示が並ぶ「AWS for Industries Zone」でのPhysical AI 特設展示や、「AWS Builders' Fair」での生成AI・AWSサービスを用いた遊び心のある展示など、様々な展示が行われていました。
2日間の参加を通じ、最新技術についてセッションで学びを深めるだけではなく、スピーカーや参加者との交流においても深い洞察を得ることができたと考えています。また、ここで得た学びはすぐにわたしたちの開発へ活かせるものが多く、有意義な時間となりました。運営スタッフの皆様、2日間ありがとうございました。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()








/assets/images/16907545/original/ec791cd3-ea53-45e2-bc6f-a1262b413594?1753696883)



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

