




時系列データ内の類似部分列群の抽出、および類似部分列群に関する特徴から時系列データの逆生成
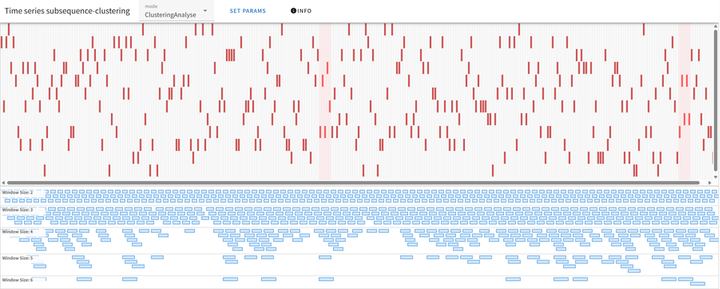
※urlは無料枠で動かしてるので処理遅いです。都度更新していて、バグもまだあります。 ・時系列データを渡すとその中にある類似部分列群を高速でクラスタリングし、結果をグラフィカルに表示することができる。ポイントは、様々な長さの類似部分列群の検知が可能。 ・そのアルゴリズムを利用して時系列データを逆に生成する。具体的には、 1.決定されている時系列データの末尾に、候補となる要素を1つ追加する。 2.追加された時系列データ全体から類似部分列群を抽出して解析。「類似部分列群の数が少ない」「クラスター同士の距離が長い」「類似部分列群自体が複雑」なデータは反復が少ない=複雑であるとみなし、複雑度を得る。 3.全候補に対して2.を繰り返し、複雑度順に候補を並べる 4.ユーザが求める複雑な度合いにマッチした候補を決定項とする。 5.ユーザは複雑な度合いを時系列で渡せるので、その時系列に沿って1.から4.を実行し最終的な時系列データを得る この時系列データを音楽の諸要素に渡すことでユーザが求める複雑度の遷移に沿った音楽を生成することが最終目標。