
こんにちは。ウォンテッドリーでバックエンドエンジニアをしている小室 (@nekorush14) です。今回は先日 市古さん(@sora_ichigo_x) が公開した「Human-in-the-Loop な AI エージェントを作るためのソフトウェア設計」でお話できなかったLLM 出力の検証と安全ガードレール設計について話します。
はじめに
「AI エージェントモード」は2025年11月にリリースされた「候補者探しの一部を AI で自動化する」ことができるスカウトの新機能です。
/assets/images/22548540/original/f6847924-a0ef-432c-a1ff-ecdae8ee7980?1764039383&w=1440)
AIが候補者リストを作成提案する「AIエージェントモード」提供開始 | Wantedly, Inc.
「Human-in-the-Loop な AI エージェントを作るためのソフトウェア設計」 では、「AI エージェントモード」を開発した背景やどのようにして AI に候補者のリストを作成させるかを紹介しました。この中でも紹介されていましたが、「AI エージェントモード」は内部で LLM (Large Language Model) を使用して推論します。したがって、エンドユーザーにとって LLM の回答が安全でなければなりません。また、LLM を使用するにあたり検討しなければならない事項が「レートリミットの到達」問題です。
本稿では、ビジネスロジックに基づいた柔軟なガードレールを構築するために採用した「Self-consistency」による判定精度の向上と、それを支える堅牢なリトライ戦略である「Exponential backoff + Full Jitter」について紹介します。
ガードレールをLLMにする
「AI エージェントモード」の構成を図示すると以下の通りとなります。
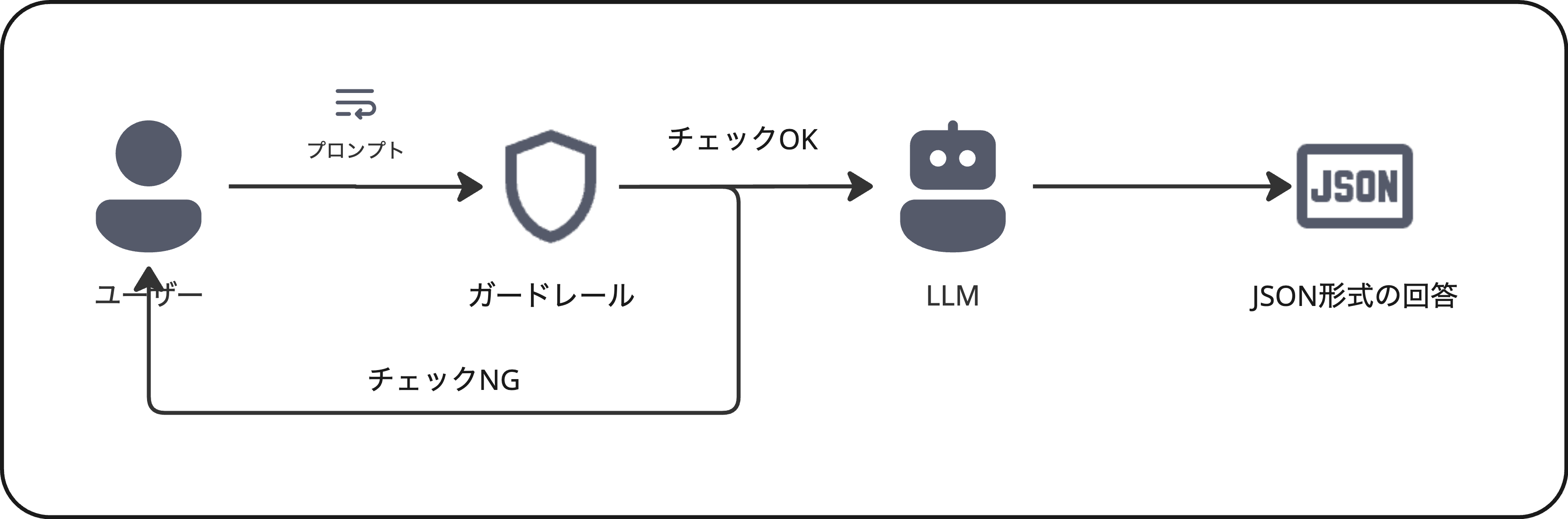
上図ではユーザーからのプロンプトをAIエージェントが実行する前に、その指示内容が安全かつ適切であるかを判断する「ガードレール層」を設けています。
一般に、LLM プロバイダとして AWS を利用する場合、「Amazon Bedrock Guardrails」といったマネージドサービスや、単純な正規表現によるワードフィルタが用いられます。一方で、「AI エージェントモード」では安全性を担保しつつ、プロダクト要件を満たす必要があり、より細かく柔軟なガードレールを実現しなければなりませんでした。特に、採用文脈での独特の表現に対応する必要があり、採用文脈でのドメイン知識と照らし合わせた上での意味論的 (Semantic) なバリデーションが求められました。
採用した設計
前述の要求を実現するために、「AIエージェントモード」ではマネージドサービスではなく、ドメイン知識をプロンプトとして与えた「ガードレール専用の LLM 」に判定を委ねる設計としました。これにより、採用担当者が頻繁に使用する単語を適切に判断できるようになりました。
一方で、この設計としたことで以下の2点の課題がありました。
- LLM は確率的に動作するため判定結果が揺らぐ場合がある
- レートリミットの到達の可能性が増加する
特に課題2は後述する課題1の対策のため、更なる可能性の増加が予見されたため、効果的な対策を検討する必要がありました。
Self-consistency
まず、課題1の「LLM は確率的に動作するため判定結果が揺らぐ場合がある」に対し、今回は Self-consistency という手法を採用することにしました。
一般に、 LLM に対して物事を判定するためにスコア算出するように指示を与えた場合、その信頼度は低くなることが知られています。[1] エンドユーザーから「AI エージェントモード」への指示は曖昧な表現も含まれることが想定されたため単なる二値 (Safe / Unsafe)での判定も難しいことが予想されました。
Self-consistency では、以下のフローで判定が行われます。
- 事前に脅威度の分類やスコア、脅威と判定する閾値を定義しておく
- LLM のパラメータである Temperature を調整し、推論結果に適切なばらつきを与える
- 同一のプロンプトで n 回推論する
- n 回分の推論結果に含まれる脅威度分類に紐づくスコアを出現頻度に応じて平均を算出する
- 算出結果が閾値を超えた場合、Unsafe と判断する
疑似コードで示すと例えば以下の通りとなります。
class GuardrailLLM
# 0. 事前に脅威度の分類やスコア、脅威と判定する閾値を定義しておく
THREAT_LEVELS = {
"SAFE" => 0, # 安全
"LOW" => 2, # 軽微なリスク
"MEDIUM" => 5, # 中程度のリスク
"HIGH" => 10 # 重大なリスク
}.freeze
# 判定の厳しさを決める閾値
# 平均スコアがこれを超えたら Unsafe とみなす
THRESHOLD = 3.0
# 推論回数 (Self-consistency の試行回数)
SAMPLE_COUNT = 5
def safe?(user_input)
# 2. 同一のプロンプトで n 回推論する
results = SAMPLE_COUNT.times.map do
# 1. LLMのパラメータであるTemperatureをガードレールタスクにおける安定性を考慮し調整する
call_llm_api(user_input, temperature: 0.7)
end
# 3. n回分の推論結果に含まれる脅威度分類に紐づくスコアの平均を算出する
total_score = results.sum do |result|
# レスポンスに含まれる分類ラベル("SAFE", "HIGH"等)をスコアに変換
THREAT_LEVELS[result.classification_label] || 0
end
average_score = total_score.to_f / SAMPLE_COUNT
# ログ出力用(運用時のチューニングに活用)
logger.info "Guardrail Score: #{average_score} (Results: #{results.map(&:classification_label)})"
# 4. 算出結果が閾値以下の場合、Safe と判断する
average_score <= THRESHOLD
end
private
def call_llm_api(input, temperature:)
# ここで Bedrock Client 等を呼び出す
# Exponential Backoff + Full Jitterのリトライロジックもここで呼び出す
end
end
*注: このコードは説明用のサンプルコードであり、実際に動いているコードとは異なります。
この手法を用いることで、単一のLLMによる回答よりも推論精度が大幅に向上することが知られています。[2] また、プロダクトのフェーズや要件に合わせて、「厳しくブロックするようにする (閾値を下げる)」のか「利便性を優先する (閾値を上げる)」のかを柔軟に調整可能となります。
Exponential backoff + Full Jitter
次に、課題2の「レートリミットの到達の可能性が増加する」について、前述の Self-consistency を採用すると、1回のユーザーリクエストに対して N回のLLM APIコールが発生します。API プロバイダのレートリミット (Throttling Exception) に到達する可能性が飛躍的に高まります。 単純なリトライ (固定時間待機して再試行) では、リトライのタイミングが他のリクエストと重なり、再度レートリミットに到達する「Thundering Herd 問題」を引き起こし、可用性が大幅に低下してしまいます。
そこで、今回は Exponential backoff + Full Jitter を採用しました。
Exponential backoff ではリトライ回数に応じて、待機時間を指数関数的に伸ばします。(例: 1秒, 2秒, 4秒...) これにより、サーバー負荷が高い時に十分な回復時間を確保します。Full Jitter は Exponential backoff により指数関数的に伸ばした待機時間に、ランダムな「揺らぎ (Jitter)」を加えます。AWS Architecture Blog [3] でも推奨されている手法で、疑似コードとしては以下のようになります。
# cap: 最大待機時間
# base: 基準待機時間
# attempt: リトライ回数
temp = [cap, base * (2 ** attempt)].min
sleep_time = temp / rand(0..temp)
sleep(sleep_time)
*注: このコードは説明用のサンプルコードであり、実際に動いているコードとは異なります。
これにより、リトライを行うタイミングがリクエストごとに分散されるため、レートリミットに到達する可能性を低下させることができます。
実装後の運用
ここまで紹介した「LLM によるガードレール」や「Self-consistency」の実装自体は比較的簡単に実装できます。一方で、これらは「実装して終わり」ではなく、運用の中で以下のような課題が発生することがあります。
- 誤検知 (False positive): 安全な指示なのに、過剰に危険と判定して弾いてしまう事象
- 見逃し (False negative): 本来弾くべき危険な指示を通してしまったり、エージェントが意図しない挙動をする事象
特に独自のドメイン知識を用いたバリデーションの場合、初期のプロンプトだけで全てのケースを網羅することは不可能です。そのため、「誤検知が発生することを前提とし、それに気づいて改善できる仕組み」をセットで構築する必要があります。所属チームでは、判定ログの定期的なモニタリングを行っています。「スコアが境界値ギリギリだったもの」や「ユーザーから『できない』と報告があったもの」を人間がレビューし、そのケースを「正解データの Few-shot (具体例)」としてプロンプトに追加することで、継続的に判定精度を向上させています。
まとめ
本稿では、「AI エージェントモード」を支えるガードレール設計について紹介しました。ドメイン知識が必要な複雑なバリデーションには「LLM 自体をガードレールにする」アプローチが有効であると判断しました。その際、Self-consistency を用いてプロンプト解釈の揺らぎを吸収し、「Exponential backoff + Full Jitter」で API 通信の安定性を確保することで、確率的な挙動をする AI を、信頼できるシステムコンポーネントとして組み込むことが可能になります。
参考文献
[1] Dhruva Bansal, Nihit Desai, “Improving data quality with confidence”
[2] Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
[3] Exponential Backoff And Jitter | AWS Architecture Blog
/assets/images/16907545/original/ec791cd3-ea53-45e2-bc6f-a1262b413594?1753696883)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


