ウォンテッドリーの推薦システムを支えるMLOps -現状の取り組みと課題- | Wantedly Engineer Blog
はじめにウォンテッドリーでデータサイエンティストとして働いている市村です。私たちのチームは Wantedly Visit の推薦システムの開発と運用を担っています。機械学習をベースとした推薦シス...
https://www.wantedly.com/companies/wantedly/post_articles/1047307
こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。
推薦チームでは推薦システムの開発だけでなく、モデルの開発・運用で使用するMLOps環境改善にも取り組んでおり、先日社内のMLOpsについての現状に関して投稿しました。
今回はMLOps環境改善の一環として、Vertex AI Model Monitoringを試験導入した事例についてご紹介しようと思います。
モデル性能の劣化と機械学習モデルの再学習
「毎日最新化しているから安心」は本当か?
入力データ自体の異常(データ品質の劣化)
突発的なドリフト
Vertex AI Model Monitoringによるモニタリング
外部モデルを用いたモニタリング
入力特徴量のモニタリング
出力のモニタリング
わかってきたポイント
まとめ
機械学習モデルは過去のデータからパターンを学習して予測を行うため、本番環境のデータが学習時のデータと変化すると性能が劣化する可能性があります。下記の「MLOps実装ガイド」によれば、機械学習モデルの性能劣化を引き起こす原因の一例としてドリフトが紹介されています。
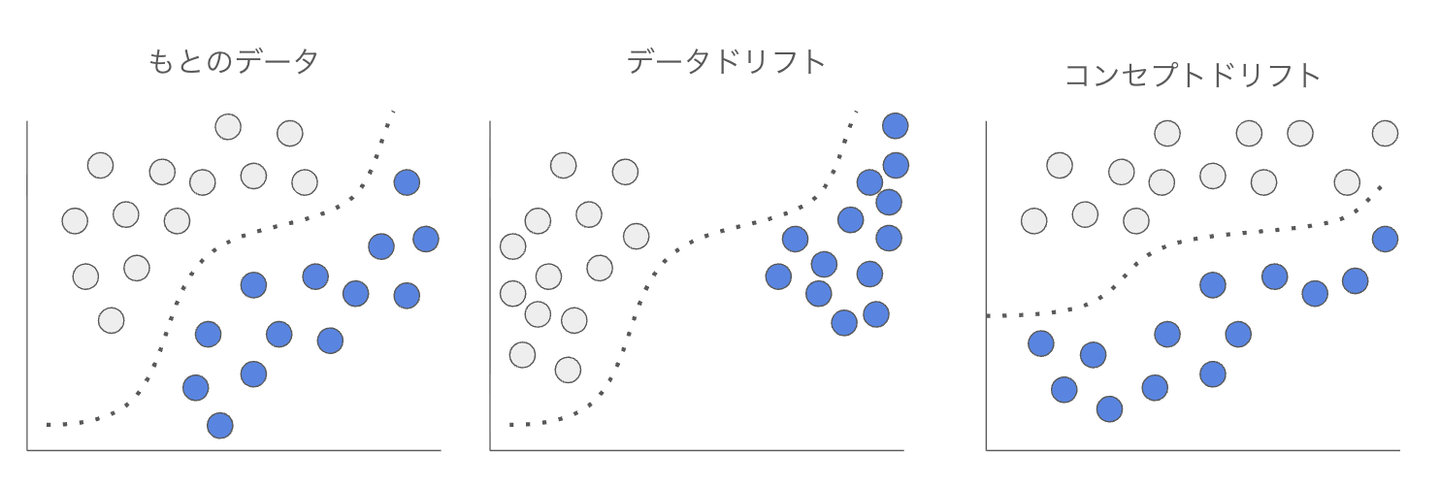
上記の書籍ではドリフトについて下記の2種類が紹介されています。
これらはどちらも学習時と推論時の間でデータの傾向が変わってしまうため、学習時に高い性能を出していたようなモデルであってもデータの傾向変化によって性能劣化を引き起こしてしまいます。
モニタリングによってモデルの異常や性能劣化を早期に発見することができれば、必要に応じて調査や再学習などの対応を行うことができるようになります。
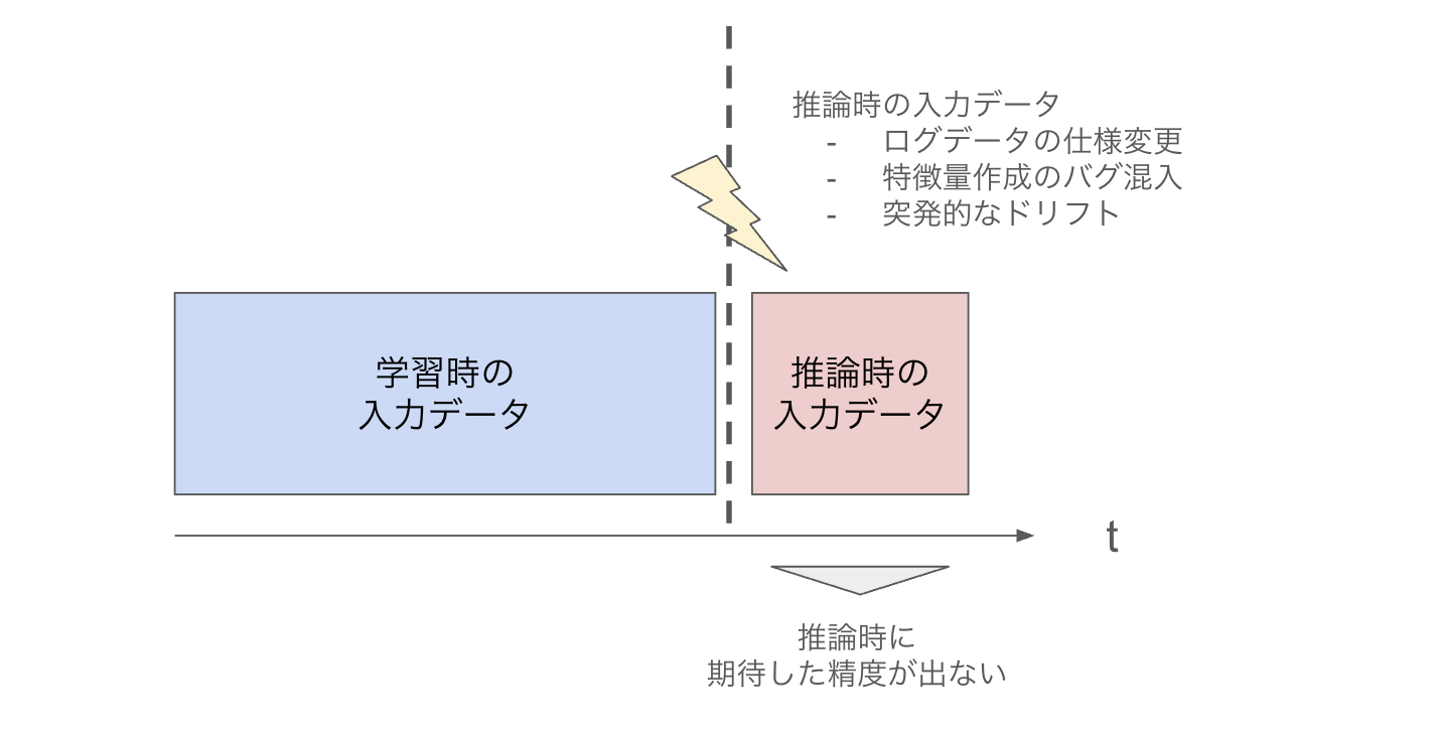
先ほど紹介したドリフトが引き起こす問題の例としてよく挙げられるのは、一度作成した機械学習モデルをデプロイし、その後継続して運用しているケースです。極端な例ですが、1年前に作成したモデルを継続して推論に使用していたとする場合、その1年間でモデルへの入力データ自体や、入力データと出力データの関係性が変化してしまうことは十分に考えられます。このようなドリフトが発生した場合、一般的には性能劣化を防ぐためにモデルを再学習することが望ましいです。
では、毎日最新のデータを用いて再学習を行っているシステムであれば、ドリフトは無視できるのでしょうか?結論から言うと、機械学習モデルのワークフローを自動化し、毎日自動でモデルを更新していたとしても、システムが気づかないうちに劣化していくリスクがあります。
毎日自動でモデルを更新するシステムを運用している場合でも、気づかないうちにモデルが劣化する例の一つが入力データ自体の異常です。
例えば、データ抽出元のシステムにおいてバグが発生したり、予期せぬ仕様変更が行われたりするケースが考えられます。自動化されたワークフローでは、こうして生じた「異常なデータ」であっても、システムがストップせずにそのままモデルの学習に使われてしまう可能性があります。
モニタリングを通じて入力データの品質劣化を監視することは、異常なデータをそのまま学習してしまうという事故を未然に防ぐために非常に重要な役割を果たします。
日々の学習だけでは吸収しきれないようなトレンドの急変が発生する可能性もあります。サービスの外部環境の変化によって突然データの傾向が変化することがあり、SNSやメディアでの話題を起点に傾向が変化することは十分に起こり得ます。
上記のようなドリフトを早期に検知できれば、モデルの改善やシステムの修正といった具体的なアクションにつなげていくことが可能になります。そのため急激なデータの傾向変化は性能劣化を引き起こすドリフトをシステムとしていち早く異常を捉える仕組みがあることが望ましいと言えます。
Vertex AI Model Monitoringはモデルの品質を追跡できるGoogle Cloudのサービスです。推薦チームでもMLモデルを日々活用していることから、こちらのサービスを使ってモニタリング出来ないか試してみることにしました。
Wantedlyの推薦システムは基本的にバッチ推論となっており、AWS上にあるKubernetes クラスタ上で動作しています。Vertex AI Model MonitoringはGoogle Cloudのサービスではあるものの、今回のようなVertex AI以外で動作しているモデルのモニタリングもサポートしています。
外部モデルのモニタリングはコンセプトドリフトを検知するような入出力の関係性については記録することができないという制約はあるものの、入力特徴量・出力の分布についてはトラッキングすることができます。
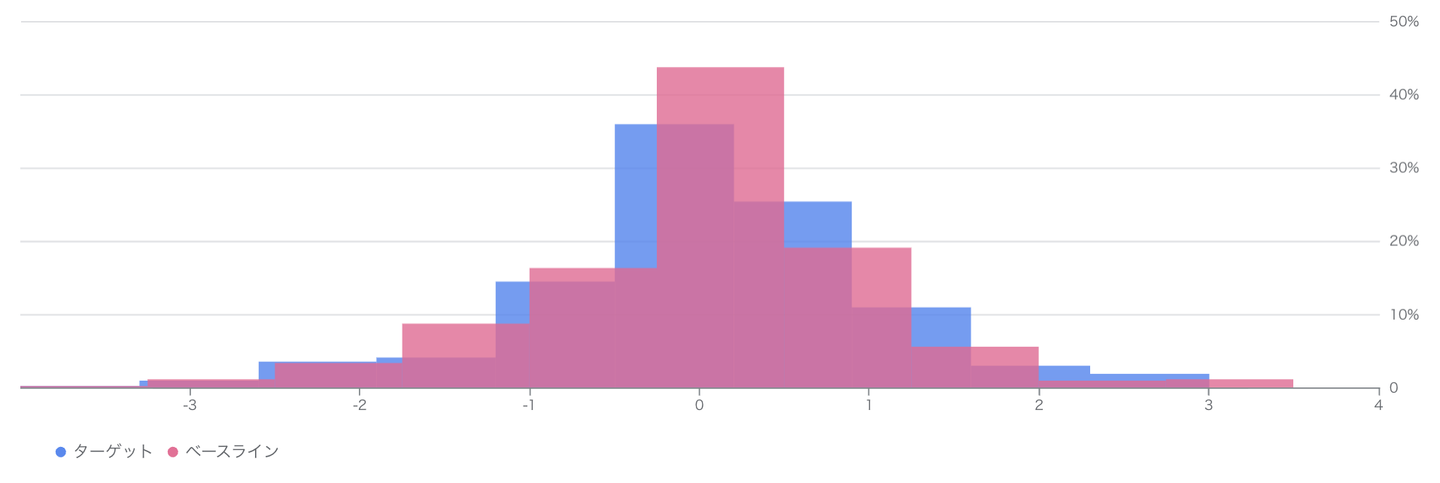
データドリフトを検知する単純な方法は特徴量について前後比較する方法かと思います。学習時と推論時のデータの分布の変化がモデルを劣化させる一因になるため、Vertex AI Model Monitoringでは特徴量ごとに分布を下記の例のようなグラフでモニタリング・比較することが可能になっています。
上記の図のように、学習時(ベースライン)と推論時(ターゲット)の分布が乖離し始めるとなんらかのデータの傾向が変化している疑いがあると予想でき、ここから調査を進めることが出来ます。
特徴量の数が多い場合であっても、特徴量ごとに学習・推論間の分布の乖離度合いによってアラートを出すことができるのでいち早く異常を検知できるようになっていました。
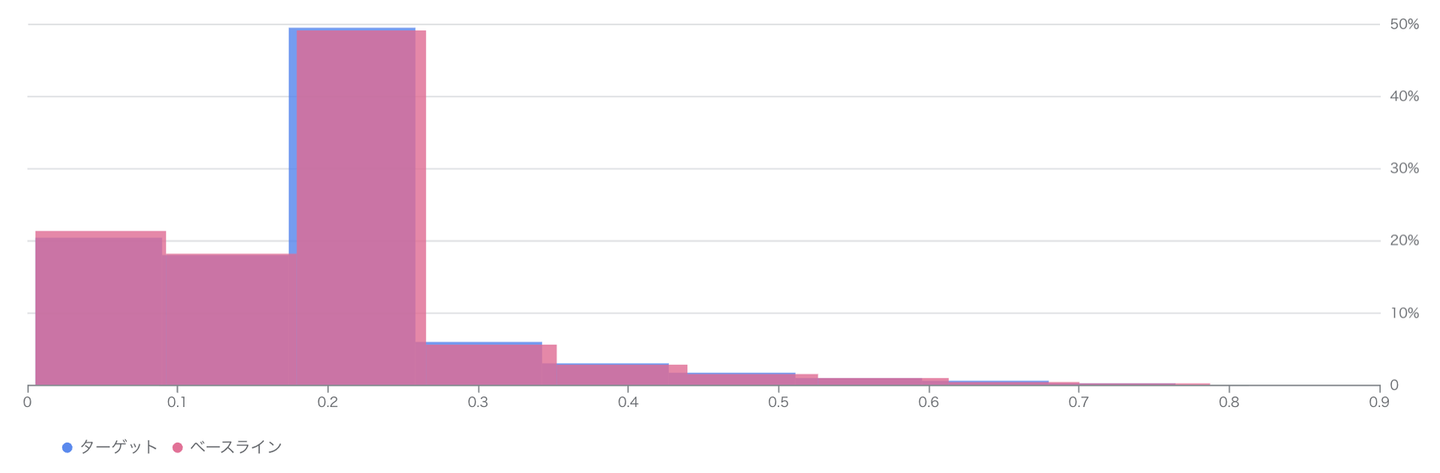
一見すると入力特徴量は大きく変化していない場合でも出力の分布が変わる可能性もあり、出力の分布もモニタリング可能になっています。
上記のように出力がベースライン(学習時)とターゲット(推論時)で乖離が少ない場合は問題なさそうに判断できますし、逆に分布が大幅に乖離している場合には何らかのデータの傾向が変化している疑いがあるとわかります。
モデルの出力が大きく変動する際には、ユーザーに対しても大きな体験変化が発生する可能性があるため、その変動が体験上問題のないものなのか確認するためにもモデル出力のドリフトを検知することができるようになっています。
Vertex AI Model Monitoringを使って入力特徴量・出力のモニタリングを試験的に運用してみたのですが、モニタリングにあたって正常とする範囲をどう定義するのが1つのポイントになると感じました。
実サービスではユーザーの行動傾向が変化するものなので、入力特徴量・モデル出力も当然日常的に変化します。分布の乖離によって異常を検知できると言っても、その閾値がどこにあるのかはサービスやタスクごとに大きく異なると思います。この正常・異常の閾値設定が甘いと、異常が発生していてもアラートが発生しなかったり、逆に常にアラートが出て本当に重要なアラートを見過ごしてしまう本末転倒な結果にもなりかねません。
過去のデータの傾向を踏まえて、モニタリング対象ごとの正常の範囲を精査・設定することが意味のあるモニタリングを継続するために必要だと考えています。
今回はMLOps環境改善の一環として、Vertex AI Model Monitoringを試験導入した事例についてご紹介しました。意図しないモデルの精度劣化を検知するためにもMonitoringは重要ですが、その設定にも難しさがあることがわかりました。安定したMLモデル開発のためにも、今回以外にもMLOps環境の整備に継続して取り組んでいこうと思います。
ウォンテッドリーでは、ユーザーにとってより良い推薦を届けるために日々開発を行っています。ユーザーファーストの推薦システムを作ることに興味があるという方は、下の募集の「話を聞きに行きたい」ボタンから気軽に話を聞きに来ていただけるとうれしいです!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
![]()
/assets/images/22261847/original/19d99707-beb7-41c1-8e85-6c8e8099f547?1761203707)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

