こんにちは. Wantedlyでデータサイエンティストをしている合田です.
2019年12月10日11日の2日間, Kaggle Days Tokyoというイベントに参加してきました. このフィードでは, オンサイトコンペとプレゼンテーションについてまとめを書いていこうと思います. 同僚の石崎さんが下記の記事を先行して書いてくれたので, 基本的にはそちらに書かれていないことをまとめていこうと思います.
Competition
始めにコンペについてお話しようと思います. Kaggle Days Tokyo の2日目ではイベント参加者限定のデータ分析コンペが開催されました. 日本経済新聞社がスポンサーになっており, 日経電子版のデータを使った問題でした.
扱うデータはユーザの記事閲覧ログデータと記事のメタデータ (タイトルや属性, 記事内容など) で, ユーザのログを元に年齢を推定するという問題でした. 一般的なテーブル要素に加えてNLP要素もあり, やることの多いコンペでした.
3人を上限としてチームを組むことができたので, NLPを専門にしている機械学習エンジニアとatmaCupというデータ分析コンペの優勝者と一緒のチームでチャレンジしました. 私たちのチームは2人がモデリング担当, 1人がテキストデータから特徴量を抽出してモデリング側に渡すという役割で進めていきました.
私の取り組みですが, 記事のテキストデータ以外のデータを使って特徴量を作成してモデルを学習させました. 基本的な取り組みはユーザ毎に特徴量を作成してユーザ単位で学習・予測を行いますが, 私は差別化のために, ログ毎で特徴量を作成してログ単位で学習・予測を行い, その出力とログ単位の特徴量をユーザ毎に集約して2段目でユーザ単位の学習・予測を実施しました. ユーザ毎に集約させるとどうしても情報量が落ちてしまうので, それを出来るだけ避けるために取った手法でした. ただこのやり方だと学習時間が大幅に増えてしまうので, 試行錯誤のサイクルがより重要となるオンサイトコンペでは悪手だったと思っています. あとデータの性質的にtarget encodingが効きそうだなと思って特徴量として採用しましたが, これはとても有効でした.
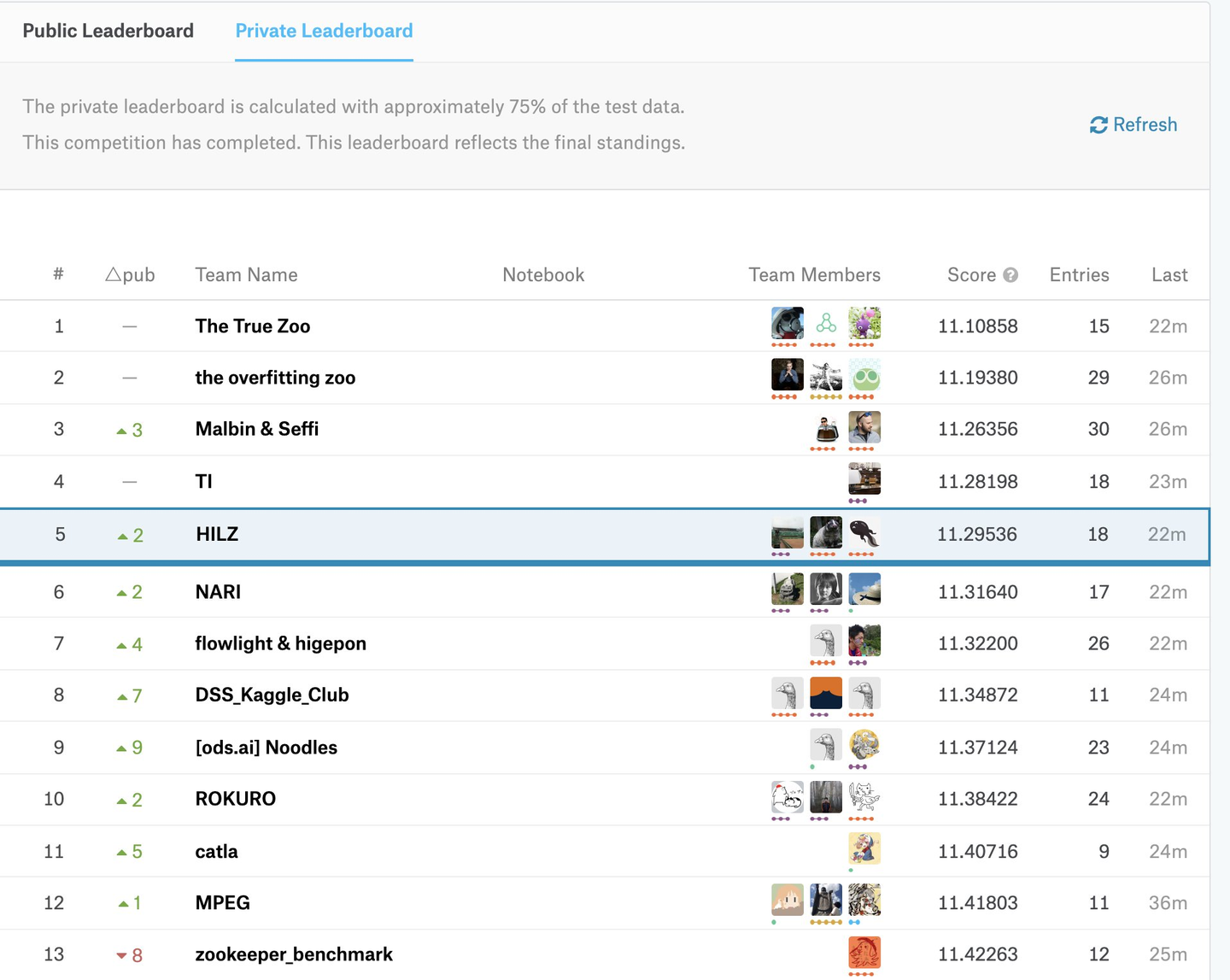
最終的には, 自分のモデルとチームメイトのモデルの加重平均を取ったものを最終サブミットに選択しました. やれることは大方やり, チームメイトみんなで力を出し切ったのですが, 結果は88チーム中5位という結果に終わりました.
![]()
コンペ終了後に入賞チームの解法を聞くことができましたが, 上位チームは試した手法の数が圧倒的に多く, その試行錯誤を経て有効なものを多く見つけており, 手数の足りなさを痛感しました.
オンサイトコンペは, 素早い EDA/特徴量作成/モデリングのサイクルが必要なことと, タスクの優先順位設定が求められること, 結果発表がその場でされるドキドキ感, 終了後に他の参加者と解法を共有し合えることが魅力だと思っています. 今回のコンペは, 非常に良質なデータと取り組んでいて楽しい問題設計でした. 次に参加するオンサイトコンペも, 今回の反省を踏まえて取り組んでいきたいです.
Presentations
Imputation Strategy
こちらは「Kaggleで勝つデータ分析の技術」の著者の一人である平松 雄司さんの発表です. 予測精度の向上を目的とした欠損値処理について解説されていました.
本プレゼンでは, 以下のようなトピックが紹介されていました.
- 統計分析における欠損値の対処方法
- XGBoost における欠損値処理のアルゴリズム
- XGBoost と MICE+XGBoost の比較実験
Kaggleや実務で予測精度を目的としたモデリングでは, XGBoostやLightGBMなどのGBDTフレームワークが採用されることが多く, 欠損値は処理せずそのまま学習データとしてモデルに突っ込むことが常套手段です. これはXGBoostなどの学習アルゴリズム内では, 学習データに含まれている欠損値に対する処理が行われているためです.
しかし, 統計分析においては, 多重代入法などの欠損値処理でデータの前処理を行うことが定番です. 本プレゼンでは, XGBoostに欠損値を含む不完全データを投げる前に多重代入法による前処理を実施することで, 不完全データをそのままXGBoostに投げるよりも予測精度が向上するか検証していました.
実験では, Kaggleコンペのデータ (BNP Paribas Cardif Claims Management) を使い, 多重代入法の一種であるMICE (Multiple Imputation by Chained Equation) を学習データに対して実施した場合と実施しない場合の2パターンを比較しています.
最初の実験では, MICEを使う場合よりMICEを使わない場合の方が精度が高いことが確認されました. 平松さんは原因について2点考察されています.
- そもそもXGBoostの欠損値に対応した学習アルゴリズムが優秀である. XGBoostではノード毎にデータの分割を行うが, 始めに非欠損データのみで最適な分割をして, その後に欠損データを左右のどちらのノードに振り分けるか実際に試してみて, よりベストな方向に欠損データを流すようにしている. 生成されたノード/木毎に, ある特徴量の欠損値に対する分割位置が異なるため, XGBoostでは欠損データに対して暗黙的に多重代入法的な処理をしている.
- MICEで欠損を埋めたが, モデルがどの値が元々欠損だったのか分かっていない. データのどこに欠損があったかという重要な情報は, データに対して欠損値補完しただけだと消失してしまう.
次の実験では, 前の実験の考察を踏まえて, MICEによる前処理に加えて欠損値フラグをモデルに投入することを検討されました. その結果, MICEを使う場合の方が, MICEを使わない場合よりも予測精度が高くなることが確認されました.
実験結果をまとめると, 以下の順で予測精度が良くなるみたいです.
MICEで欠損処理してからXBGoost < 特に前処理せずXGBoost < MICEで欠損処理して欠損値フラグを特徴量に追加したXBGoost
(私が知らないだけかもしれませんが) Kaggleであまり試行錯誤されていない欠損値処理について統計的手法でアプローチし, 実際にコンペのデータで精度向上を検証されていた点が聞いていて大変面白かったです.また個人的にはXGBoostの学習アルゴリズムが欠損データに対しても良い感じに機能する理由が納得できて勉強になりました.
Feature Engineering and GBDT Implementation
こちらは「Kaggleで勝つデータ分析の技術」の著者の一人である門脇 大輔さんの発表です. Kaggleで使われる特徴量エンジニアリングのテクニックとGBDTのアルゴリズムについて紹介されていました.
特徴量エンジニアリングではカテゴリカル変数の特徴量エンジニアリングやトランザクションデータなどの集約方法などを紹介されていました. これらは基本的にはKaggle本の3章「特徴量の作成」に書いてある内容で, 今回のプレゼンでは外国の方向けにKaggle本を紹介するというモチベーションで発表されていました.
GBDTのアルゴリズムの話では, 学習アルゴリズムの概要に加えて, 門脇さんがpythonとcythonでGBDTをスクラッチ実装したコードを紹介していました. 実装は読みやすさを重視するような構成になっており, スライド資料には実装したクラスの概要もまとめられて, アルゴリズムを理解するのにとても良い教材となっています. アルゴリズムの数式表現を確認しながら, アルゴリズムに対応するコードをプリントデバッグして出力を見てみることで, より詳細な理解が得られるのではないかと思います.
How to encode categorical features for GBDT
こちらは「Kaggleで勝つデータ分析の技術」の著者の一人である阪田 隆司さんの発表です. カテゴリカル変数に対する様々なエンコーディング手法の差異について, 実験ベースで紹介されていました.
カテゴリカル変数に対するエンコーディングは以下のものが良く使われています.
- label encoding
- count encoding (frequency encoding)
- one-hot encoding
- target encoding
- lightgbm の categorical feature support
- catboost の ordered target encoding
阪田さんは, 各エンコーディング手法がデータセットの特性によってパフォーマンスがどのように変化するのかを本プレゼンのモチベーションとしていて, 人工的にデータセットを生成してlabel encoding, one-hot encoding, target encoding, lightgbm categorical feature support の4つを比較されていました. データセットの生成用関数のパラメータは, データ数N, カテゴリカル変数の数M, カテゴリカル変数の水準数Lであり, 実験ではデータセットのパラメータ水準数Lとモデルのパラメータnum_leavesを変化させながら各エンコーディング手法の結果を計算して各手法を比較しています.
非常に面白いと思ったのが, label encoding と one-hot encoding の比較です. Kaggleではlabel encodingの方が良く使われる傾向にあるのですが, 実験上ではone-hot encodingの方がパフォーマンスが全体的に良いことが確認されました. 特にlabel encodingだとハイカーディナリティなカテゴリ変数に対してoverfitしやすく, one-hot encodingはlabel encodingよりは多少overfitが軽減されています (恐らく今回の実験用データセットがシンプルだから).
target encodingはlabel encodingと比べるとハイカーディナリティなカテゴリ変数に対しても良いパフォーマンスが発揮されていることが確認されました. 目的変数の平均値でカテゴリをソートするtarget encodingはGBDTアルゴリズムでは大変効率が良く, それは水準数が大きいほど機能します.
同様に各ノードでobjectiveの大きさでカテゴリをソートし直す lightgbm categorical feature support もlabel encodingに比べてパフォーマンスが良いことが確認されました. ただしtarget encodingと比べると複雑な木構造 (データセットが複雑もしくはモデルのnum_leavesが大きい) であるほどパフォーマンスがより悪化しています. これはlightgbm categorical feature supportが学習データの目的変数を使ってソートしておりleak気味なので, 複雑なデータほどtrainとvalidation(もしくはtest) の乖離が大きくなっていくからです.
本プレゼンでは, データ数が少ないか, 水準数の高いカテゴリカル変数を lightgbm categorical feature support で扱う場合は, lightgbmのパラメータ min_data_per_group と cat_smooth を調整する必要があると教えてもらえました.
My Journey to Grandmaster: Success & Failure
Jin ZhanさんがGrandmasterに至るまでのKaggle遍歴とその経験から得たことを紹介されています.
予測モデルを作成する上で適切なValidationを設定することは, Kaggleや実務において非常に重要です. 本プレゼンでは, 2つのコンペを挙げてそれぞれのコンペで実施したValidation戦略を紹介しています. リクルートコンペは時系列データであり予測対象は未来であるため, 時間方向にデータをsplitする必要があります. ELOコンペは外れ値が紛れているデータであり, trainとvalidationが近い分布になるように, 外れ値にフラグをつけて外れ値フラグで層別サンプリング (stratifiedkfold) する必要があるようです.
特徴量エンジニアリングではドメイン知識を元に特徴量を作ることが大変強力であることを紹介しています. カテゴリ変数のシーケンス情報がある場合は, それを文字列とみなしてTF-IDFを計算し行列分解 (SVDやLDAなど) をして特徴量を作成することができます. 非常に聞いていて面白かったのが, カテゴリ変数間のインタラクション情報からグラフを作成してDeepWalkでベクトル表現を得るやり方で, 一般的な特徴量エンジニアリング手法とは異なるアプローチなのでどこかで試してみたいと思いました.
特徴選択では, モデルから得られた変数重要度とNULL Importanceを混ぜて上位N個の特徴量を選択して使用していて, これでいくつかのコンペで良い結果が出たと話されていました.
モデリングでは, どのコンペでもLightGBMとNNの両方を試されていると聞いて, LightGBMしか使っていない自分には耳が痛い話でした (反省) ... テーブルコンペでは基本的にLightGBMの方が精度が高くなる傾向になりますが, アンサンブル要員として期待することもできます.
Stackingでは, local cvとLBに相関があるときに機能すると話されていました. 私はめんどくさいので一度もstackingをしたことがないのですが(これまた耳が痛い), 精度向上のためには確かに有効な手段だと再認識しました.
終わり
プレゼンの内容がバラエティ豊富で, 学びの多かったイベントでした. またオンサイトコンペもとても盛り上がり, 非常に楽しく取り組むことができました. このイベントでKaggleのモチベがグワッと上がったので, 近いうちに開催中のコンペに出て頑張ってみたいと思います!
Wantedly の機械学習の勉強会に遊びに来ませんか?
Wantedlyでは毎週木曜日18:30から, 機械学習の勉強会を開催しています. 外部の方も参加可能ですので, ぜひ遊びに来てください. Kaggleのコンペネタも大歓迎です!
また, Wantedlyで機械学習エンジニアとして活躍してくれるメンバーも募集中です. カジュアル面談も受け付けてますので, 気軽に話を聞きに来てください!

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


