こんにちは、Wantedly で Webエンジニアをしている渡邉(@eityans) です。モチベーション・マネジメントサービスの Wantedly Pulse を開発しています。
Pulseはチームの状態を可視化するツールです。会社全体をチームとして扱うこともできますが、従業員数の多い企業の場合、より小さなチームの状態を可視化したくなります。Pulseでは、上司部下の関係を設定することで、チームの設定ができます。このときシステムでは、以下のような操作をしたくなります。
- ある人の部下が誰なのか取得したい。
- ある人の直属の部下を取得したい。
- ある人の上司が誰なのか取得したい。
- ...などなど
このような仕様を実現させるために、メンバーのツリー構造(上司部下の関係)をRDBで表現する必要があります。
この記事ではツリー構造(木構造、階層構造)をRDBで表現する方法について書いています。構成は以下です。
- ツリー構造をRDBで表現する難しさ
- Pulseにおけるツリー構造の表現
- Closure Table Model(閉包テーブルモデル)
- Pulseにおけるツリー構造の操作
- ユーザーの部下を取得する
- ユーザーの上司を取得する
- ユーザーの直属の部下を取得する
- 上司部下関係をつくる
- 上司部下関係をはずす
- ユーザーをツリー構造から外す
- ツリー構造をRDBで表現するその他の方法
- Adjacency List Model(隣接リストモデル, ナイーブツリー)
- Nested Sets Model(入れ子集合モデル)
- Path Enumeration Model(経路列挙モデル)
- さいごに
ツリー構造をRDBで表現する難しさ
Pulseのような上司部下関係もそうですし、住所(日本>東京都>港区)など、世の中にはツリー構造を持つものがたくさんあります。
ツリー構造の情報をRDBに保存すること自体は難しくないです。ただし、「パフォーマンス良く」となると難しくなります。
ツリー構造というものはデータとデータの繋がりによって表現されます。RDBの世界で、あるデータと別のデータの関係を取得しようと思ったら結合が必要になります。さらに、「つながりのつながり」のような関係性を調べようとすれば再帰的なクエリを書く必要がでてきます。調べたい階層が深くなればなるほどパフォーマンスが悪化することがイメージできると思います。つながり情報とRDBは相性が悪いのです。
では取得するときの処理を軽くしようと、関係の情報をなるべく保存するようにしたとします(例えば、上司の上司のidを全部保存するカラムを追加するなど)。この場合、今度はツリー構造を更新するときの処置が重くなります。上司部下の例で言えば、上司を変えただけでもとの上司に関連する人や、新しい上司に関連する人など多くの人に影響が伝わっていくのがイメージできると思います。しかもそれが連鎖的に発生しうるのです。
このように、ツリー構造から情報を取得するときのパフォーマンスと、ツリー構造を更新するときのパフォーマンスの両方を考慮する必要があります。これがツリー構造をRDBで表現する難しさです。
パフォーマンス良くツリー構造を表現するために、工夫を凝らしたモデルがいくつか考えられてきました。(モデルについては後述)これからツリー構造について考えるときにはそれらのモデルを適用すれば良いですが、上記で述べたような難しさは常に意識した上で、適切なモデルを選択しましょう。
Pulseにおけるツリー構造の表現
Pulseでは閉包テーブルモデルを利用してツリー構造を表現しています。閉包テーブルを採用した主な理由としては、「空間計算量や時間計算量が十分現実的な範囲であること」、「モデルの概念理解が比較的容易であること」があります。
この章では閉包テーブルモデルの説明をします。
Closure Table Model(閉包テーブルモデル)
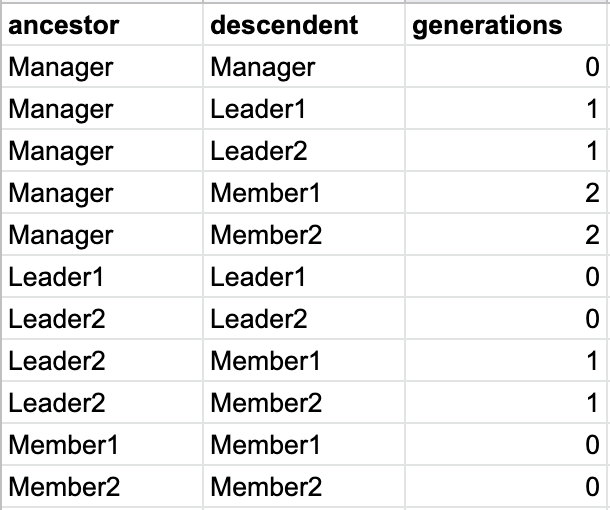
閉包テーブルモデルは、すべての世代の親子関係を保存します。
テーブルの列は3つです。
- 親の情報を格納するカラム( ancestor )
- 子の情報を格納するカラム( descendent )
- 二者の世代を格納するカラム( generations )
- 世代:ツリー構造において親子の距離を表すもの。
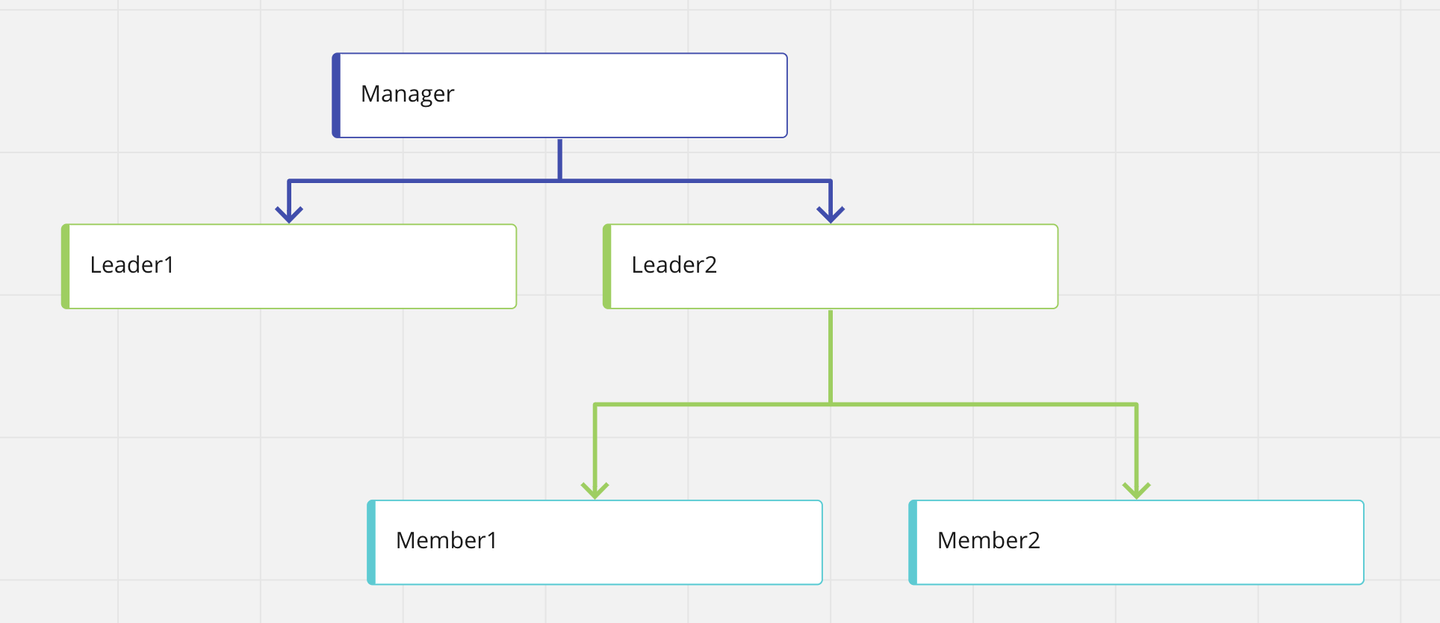
- 下の図で言えば、ManagerとMember1における世代は2、ManagerとLeader1における世代は1です。
また、自分自身も一つの上下関係として追加します。(generations = 0です)
例:以下のようなツリー構造があったとします。
![]()
このとき、対応する閉包テーブルのレコードは以下のようになります。Manager と Member1 は上司部下関係として直接つながっていませんが、generations = 2 として保存されているところがポイントです。
![]()
閉包テーブルモデルを使用するメリットとしては、親たちや、子たちの情報を取得できるのにあわせて、直属の子の情報を簡単に取得することができるところにあります。Pulseで扱いたい操作とマッチしています。(具体的な操作は後述。)
デメリットとしては、すべての世代間の親子関係を保存するためレコード数が増えることです。極端な例でいうと、会社全体の上司部下関係が直列の場合にはN^2のオーダーでレコード数が増えていきますが、そのような会社は皆無と言って良いでしょう。一般的に、ツリー構造が平衡に近い状態(ツリーの深さに偏りがない状態)であれば、レコード数のオーダーは(logN)^2 と言われています。十分実用的です。
閉包テーブルモデルを扱うgemとしては、 closure_tree などがありますが、gemの依存関係を増やしたくなかったのと、Pulseで使用するユースケース程度であれば実装コストがそこまで高くないことから今回は自前で実装しました。次の章では実装したコードを紹介します。
Pulseにおけるツリー構造の操作
ここでは、閉包テーブルをどのように利用しているのか、ユースケースごとに説明します。参考用にコードも記載しています。
閉包テーブルの情報を、MembershipHierarchy というモデルに格納しています。
また、人に関する情報を Membership モデルに格納しています。
ある人の部下や上司など、取得する操作はとても簡単です。SELECT1回で取得できます。
ユーザーの部下を取得する
MembershipHierarchy.where(ancestor_membership_id: membership_id)
ユーザーの上司を取得する
MembershipHierarchy.where(descendant_membership_id: membership_id)
ユーザーの直属の部下を取得する
MembershipHierarchy.where(ancestor_membership_id: membership_id, generations: 1)
新たに上司部下関係を作ったり、削除したりといった更新系の操作は少し複雑です。プロダクト固有の仕様に合った操作を考える必要があるためです。Pulse固有の仕様とともに説明します。
上司部下関係をつくる
上司部下関係を新しく作るときは、まず自分自身を表すレコードを作成します。
上司のその上司達に相当する人たちと、部下のその部下達に相当する人たちの直積を考え、対応するレコードを作成します。
上司のその上司達に相当する人たちの人数をA、部下のその部下達に相当する人たちの人数をDとすると、レコード生成用のデータ生成処理の計算量は O(AD) です。実際の組織におけるAやDの範囲を考えれば十分高速です。レコード生成は BULK INSERT で行っています。
def add_relation(ancestor_membership: , descendant_membership:)
# 上司部下関係のループを阻止する
return raise "Cyclic graph" if MembershipHierarchy.find_by(ancestor_membership_id: descendant_membership.id, descendant_membership_id: ancestor_membership.id)
existing_membership_hierarchy = MembershipHierarchy.find_by(descendant_membership_id: descendant_membership.id, generations: 1)
ActiveRecord::Base.transaction do
# 上司変更
if existing_membership_hierarchy && existing_membership_hierarchy.ancestor_membership_id != ancestor_membership.id
existing_ancestor_membership = Membership.find(existing_membership_hierarchy.ancestor_membership_id)
remove_relation(ancestor_membership: existing_ancestor_membership, descendant_membership: descendant_membership)
end
MembershipHierarchy.find_or_create_by(
ancestor_membership_id: ancestor_membership.id,
descendant_membership_id: ancestor_membership.id,
generations: 0
)
MembershipHierarchy.find_or_create_by(
ancestor_membership_id: descendant_membership.id,
descendant_membership_id: descendant_membership.id,
generations: 0
)
ancestors = MembershipHierarchy.where(descendant_membership_id: ancestor_membership.id)
descendants = MembershipHierarchy.where(ancestor_membership_id: descendant_membership.id)
membership_hierarchies = []
now = Time.zone.now
ancestors.each do |ancestor|
descendants.each do |descendant|
membership_hierarchies << {
ancestor_membership_id: ancestor.ancestor_membership_id,
descendant_membership_id: descendant.descendant_membership_id,
generations: ancestor.generations + descendant.generations + 1,
created_at: now,
updated_at: now
}
end
end
MembershipHierarchy.insert_all membership_hierarchies
end
end
上司部下関係のループを阻止する
閉包テーブルモデルは上司と部下の情報を保存するシンプルなモデルであるため、A->B, B->C, C->Aのような、上司部下関係がループするようなおかしなデータを保存することができてしまいます。そのため、そのようなデータを保存することが無いように制約を付ける必要があります。(これは閉包テーブルモデルに限らず、どの階層モデルでも考える必要がある事項です。)
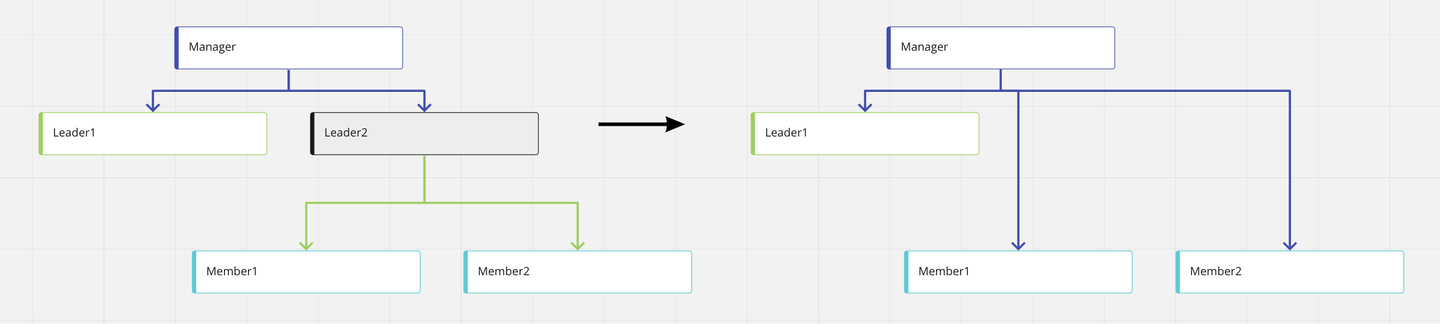
上司変更
Pulse固有の仕様として、設定できる上司は一人までとしています。上司を変更する場合(既に別の人と上司部下の関係にある人に対して上司の再設定をする場合)は、既にある上司部下関係を消す処理を行っています。なお、この操作を行うと、上司を再設定した人の部下全体が移動することになるため、部下からみると、上司の上司が変わることになります。このことをユーザーに伝えるために、Pulseでは確認画面をだすようにしています。このような、ツリー構造の処理に関する仕様はわかりにくい部分でもあるので、意識的にユーザーに伝えていく必要があります。
![]()
上司部下関係をはずす
上司のその上司達に相当する人たちと、部下のその部下達に相当する人たちの直積を考え、該当するレコードを消せば良いです。delete_byを使えばクエリ1回です。
def remove_relation(ancestor_membership: , descendant_membership:)
ancestor_membership_ids = MembershipHierarchy.where(descendant_membership_id: ancestor_membership.id).pluck(:ancestor_membership_id)
descendant_membership_ids = MembershipHierarchy.where(ancestor_membership_id: descendant_membership.id).pluck(:descendant_membership_id)
MembershipHierarchy.delete_by(ancestor_membership_id: ancestor_membership_ids, descendant_membership_id: descendant_membership_ids)
end
ユーザーをツリー構造から外す
削除の操作を行った場合、削除対象の子をどう扱うか、これはプロダクトによって仕様が分かれます。
例:ディレクトリ構造において、あるディレクトリを削除したら子のディレクトリを削除する等
Pulse固有の仕様として、ツリー構造にいるユーザーを削除した場合は、削除ユーザーの直属の上司と、削除ユーザーの直属の部下たちが新たな上司部下関係となるように扱います。
![]()
この操作を行うためには、削除対象の部下と、削除対象の直属の上司をadd_relationを用いてつなげ、
そのあと削除対象に関するMembershipHierarchyレコードを全て削除します。
この中で一番ボトルネックになりうる処理は削除対象の部下と、削除対象の直属の上司をadd_relationを用いてつなげるところです。先述したとおり、N人の会社全体に対して生成されるレコード数の平均が(logN)^2であることを考えると、この操作の影響を受けるレコード数は(logN)^2より小さいと言えるため、計算量としては O((logN)^2) 程度と言えます。なお、工夫すれば BULK INSERT 1回で済むかもしれませんが、この実装でも十分高速です。
def remove_membership(membership:)
direct_ancestor_membership_id = MembershipHierarchy.where(descendant_membership_id: membership.id, generations: 1).pluck(:ancestor_membership_id)
direct_ancestor_membership = Membership.find_by(id: direct_ancestor_membership_id)
direct_descendant_membership_ids = MembershipHierarchy.where(ancestor_membership_id: membership.id, generations: 1).pluck(:descendant_membership_id)
direct_descendant_memberships = Membership.where(id: direct_descendant_membership_ids)
ActiveRecord::Base.transaction do
if direct_ancestor_membership
direct_descendant_memberships.each do |direct_descenddant|
add_relation(ancestor_membership: direct_ancestor_membership, descendant_membership: direct_descenddant)
end
end
MembershipHierarchy.where(ancestor_membership_id: membership.id).or(MembershipHierarchy.where(descendant_membership_id: membership.id)).destroy_all
end
end
ツリー構造をRDBで表現するその他の方法
前の章ではツリー構造をRDBで表現する方法として閉包テーブルモデルについて説明しましたが、ツリー構造をRDBで表現するための代表的な方法は他にもあります。
- Adjacency List Model(隣接リストモデル, ナイーブツリー)
- Nested Sets Model(入れ子集合列挙モデル)
- Path Enumeration Model(経路列挙モデル)
この章ではそれぞれの方法の概略と、メリット/デメリットを説明していきます。
Adjacency List Model(隣接リストモデル, ナイーブツリー)
隣接リストモデルは、すべてのノードが、直属の親の情報を持ちます。閉包テーブルモデルにおいて、generations = 1 のレコードのみを作成した場合に相当します。
メリット
デメリット
- 子の子など、世代を超えた情報を取得しようとすると自己結合が必要である。また、何回結合が必要なのかがわからない。
SQLアンチパターン(Bill Karwin. 2013) では良くない例として紹介されていますが、階層が少ないことがわかっている場合は考慮に入れてもいいと思います。
Nested Sets Model(入れ子集合モデル, 入れ子区間モデル)
入れ子集合列挙モデルは、各ノードごとに区間の情報を持ち、その区間の包含関係でツリー構造を表現するモデルです。区間の情報を整数でもつ場合を入れ子集合モデル、実数でもつ場合を入れ子区間モデルと呼びます。このモデルは少し複雑なので詳しくはググってください。
メリット
- 子をすべて取るような操作が簡単
- 同じ階層のノードに順序をもたせることができる
- クエリ次第ではどんな操作もできそう
デメリット
- モデル自体が複雑でなれるまでが大変
- 直属の部下のような情報を取得するときに自己結合が必要になり複雑
個人的には興味深いモデルで、使ってみたさがあります。今回の仕様では複雑すぎると思いパスしました。
Path Enumeration Model(経路列挙モデル)
経路列挙モデルは、ツリー構造の頂点から各ノードまでの経路情報を文字列として保存していきます。
LIKE検索を駆使して検索することになります。
メリット
デメリット
- 更新処理が面倒
- ジェイウォーク(一つの列に複数の値を持つ)
一応紹介していますが、使える場面は限られそうです。
さいごに
ツリー構造の表現について、Pulseにおける開発例を交えつつ説明しました。
開発をすすめる上でのTipsでいうと、ツリー構造に関する言葉はややこしくなりがちなので、仕様を決めるときにあらかじめ言葉を定義すると進めやすくなります。例えばPulseで言えば、「部下はいるが、部下の部下はいない人」をリーダー呼んだり、「リーダーを部下に持つ人」をマネージャーと呼んだりしています。
Pulseはチームを表現するためにツリー構造を用いていますが、ツリー構造以外のチーム情報の持ち方など、まだまだ発展できる部分が残っています。このような分野について考えることができるのも新規開発の面白さです。興味があればお話しましょう。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

