
検索を改善しやすい環境をマイクロサービスで実現する | Wantedly Engineer Blog
はじめまして。Wantedly Visitの推薦基盤チームの一條です。普段はData EngineerやMLOpsなどに取り組んでいます。 ...
https://www.wantedly.com/companies/wantedly/post_articles/309758
はじめまして。Wantedly VisitのMatching Squadの推薦基盤チームの一條です。普段はData EngineeringやMLOpsに取り組んでいます。
Wantedlyではユーザーと企業のマッチングをより良いものにするために募集やスカウトでのユーザー検索を日々改善しています。
しかし、改善が進むにつれてリリースフローのコミュニケーションコストや実装コストが目立つようになってきました。その問題についてにどういった取り組みをしたかについて書いていこうと思います。
基本的にWantedly Visitの募集とスカウトの検索はGoで書かれているマイクロサービス(以後visit-recommendation-XXXと表記)で行われます。Wantedlyでは基本的にRubyを使いサービスを実装していますが、ここでは複雑な検索を高速にするため並行なコードが簡単に書けるGoを使っています。
このマイクロサービスは利用するデータが巨大でかつ速度面の要求も強いことから、ソートに使うロジックへの制約として
といった制約を入れています。
推薦基盤チームから見える、具体的なリリースまでのフローとしては次のようになります。
というフローになっており、1と2はデータサイエンティストが、3と4に関しては基盤チームが行う、という形になっています。
余談ですが、ここでBigQueryにスコア付けした結果の保存とvisit-recommendation-XXXへの同期をタイミング良く行う必要があります。またスコア付に関してはPythonで書かれる機会が多いです。そのため言語を超えた依存関係の記述にArgoを利用しています。Argoについては、 同僚の@unbleeが書いた記事があるのでそちらをご覧ください。
ここでは主に次のような課題がありました。
これらを解決するために次を行いました。
この2つについて説明していきます。
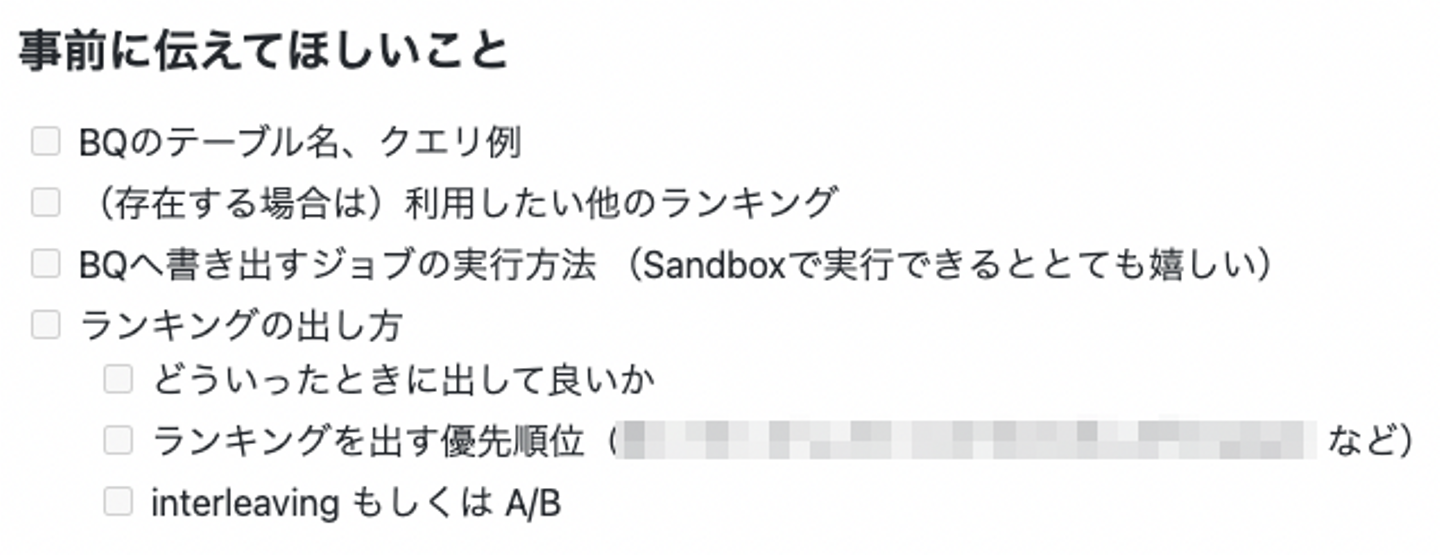
まず小さく改善を進めて行くために次のようなことをデータサイエンティストにお願いしました。
ここでの目的はある程度推薦基盤チームの知りたい情報を集約し、これが適切な境界かを確認していきました。
次に、これらを導入した後でも日本語での補足が多く、十分でないことがわかったため、visit-recommendation-XXXの実装内で利用されているその複雑な箇所にあたる用語をチーム内のMTGやissueなどに混ぜていき、データサイエンティストが自分から利用するかを確認していました。目的としては、データサイエンティストにとっても有益かを判断するために用いました。
その後、導入した単語を元に同じイメージを元に会話ができるよう、図などを用いて感覚をあわせていく、といったことを行いました。ここのステップは適宜フィードバックをもらい修正したり、利用頻度の低い単語をマージする、ということを行います。
ある程度やり取りに必要な情報や、単語の確認、考えなどはインターフェース作成の部分でわかったので、残りは自動生成を進めていきます。
自動生成で解決したい課題としては次です。
ただ、ここで重要な点として全てを自動生成する、ということは行わず「8割ほどの部分をカバーする」という方針で実装していくことにしました。これは2割部分が今後も使っていくかわからず、実装コストも高く、また適宜変わる部分だと判断し、その部分に関してはインターフェースだけ提供し、自動生成は行わないようにしました。またどこが2割の部分かは意識しても仕方ないので、データサイエンティストから見ると人間が書くか、自動生成されるかは意識しなくて良い状態が実現しています。
という方針を決めると、残りは当時インターンに来てくれていた [@nosukeru](https://github.com/nosukeru) くんに任せたら爆速で1週間ほどでやってくれました。
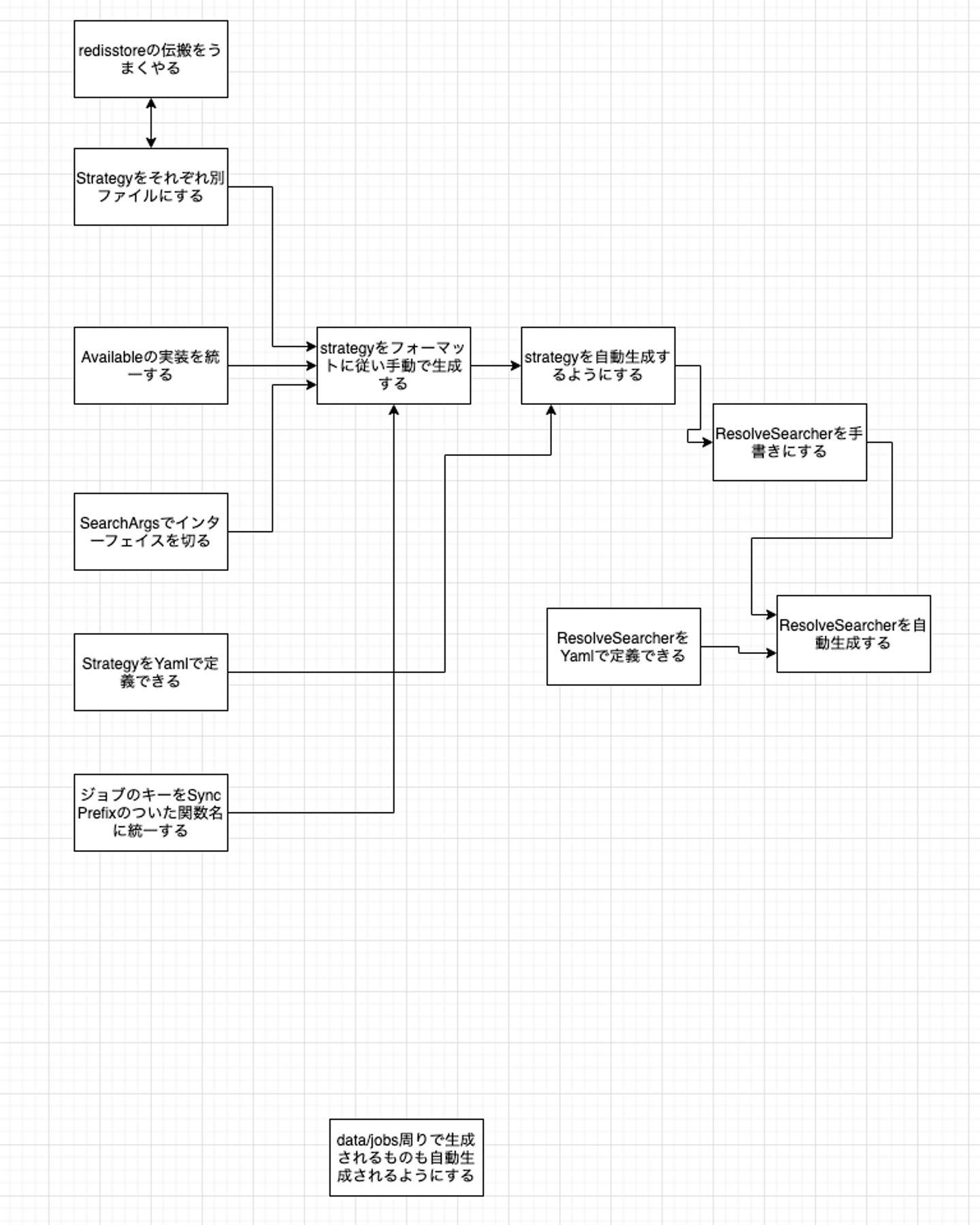
基本的に取り組んだものとしては次です。
自動生成に必要なタスクとその依存関係はこのようになっています。ここで重要なのは前ステップで定義した用語を使ってタスクを記述してます。
次のようなyamlに今までのコミュニケーションを凝縮し記述することにしました。
- name: Ranking
type: mix
children:
- RankingA
- RankingB
- name: RankingA
type: leaf
- name: RankingB
type: leaf
...- name: RankingA
query: |
SELECT
[] AS keys,
ARRAY_AGG(project_id) AS ids,
ARRAY_AGG(score) AS scores
table: visit.rankingA
repository: visit-rankingA
command: python job.py
- name: RankingB
...上のファイルはランキングの構造をDAGで記述したもので、データサイエンティストが出してほしいやり方を書いています。下のファイルはデータ同期の方法や形式について記述しています。これらの詳細については別の記事で書こうと思います。
この改善によりデプロイするまでの時間は1時間程度まで短縮され、またチーム内でストレスのかかっていたコミュニケーションコストもyamlをPRで出すだけでほとんど完結し、コミュニケーションコストはかなり減りました。
また、過去のリリースについても、gitに全て残っているためいつでも遡れ、議論もプルリクエストベースで行うためどういう意思決定がリリースの際にあったのかも簡単に遡れるようになりました。
また、副次的な効果としては、データサイエンティストとのインターフェースが正しく切れていることにより、スケーラビリティを上げる、といったプロジェクトに関しても、データサイエンティストとのやり取りをあまり必要とせず進めることができました。
また、海外は特有の事情で日本と同じようなロジックではなく、海外チームで行っていますが、その際も基盤チームのリソースがほぼ一切かからず、独自にデプロイをする、ということができるようになりました。
正しくインターフェースを切ることで、ここまで業務を高速化することができ、更には自動化までが行えるのは想定していた以上の絶大な効果が得られたのではないかと思います。
また、このプロジェクトは自分のサイドタスクとして進めていましたが、この絶大な効果を見るにもっと早くこのプロジェクトに取り組むべきだったな、というのが反省としてあります。効果としてはこれによりコミュニケーションや実装に割いてたコストが破壊的に減ったからです。
もし、こういったことに興味があればカジュアルに話を聞きに来てもらえると嬉しいです。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()






/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

