GraphQL Gateway - アプリ向けにAPIを公開する
https://docs.wantedly.dev/fields/the-system/graphql-gateway#naze-graphql-nanoka

この記事は Wantedly Advent Calendar 2023 の8日目の記事です。
こんにちは。ウォンテッドリーでインフラエンジニアをしている田中 (@bgpat) です。
この記事では Infrastructure Squad でサービスの信頼性を維持するために取り組んでいる SLO 運用について、これまでの振り返りとこれから取り組もうと考えていることについて紹介しようと思います。
Wantedly で SLO の運用が始まったのは2018年でした。インフラチームが提供しているサービスの異変を早く検知できるようにするために導入されました。
SLO の対象は提供している中から特に重要なものを10機能を選定し、目標として設定しました。草案をインフラが作り、各プロダクトチームのリーダーと議論することで決定しました。
どこで計測するかについては以下の3点に着目して比較し、最終的にロードバランサーのログ、つまり REST API のパスとステータスコードを使用することになりました。
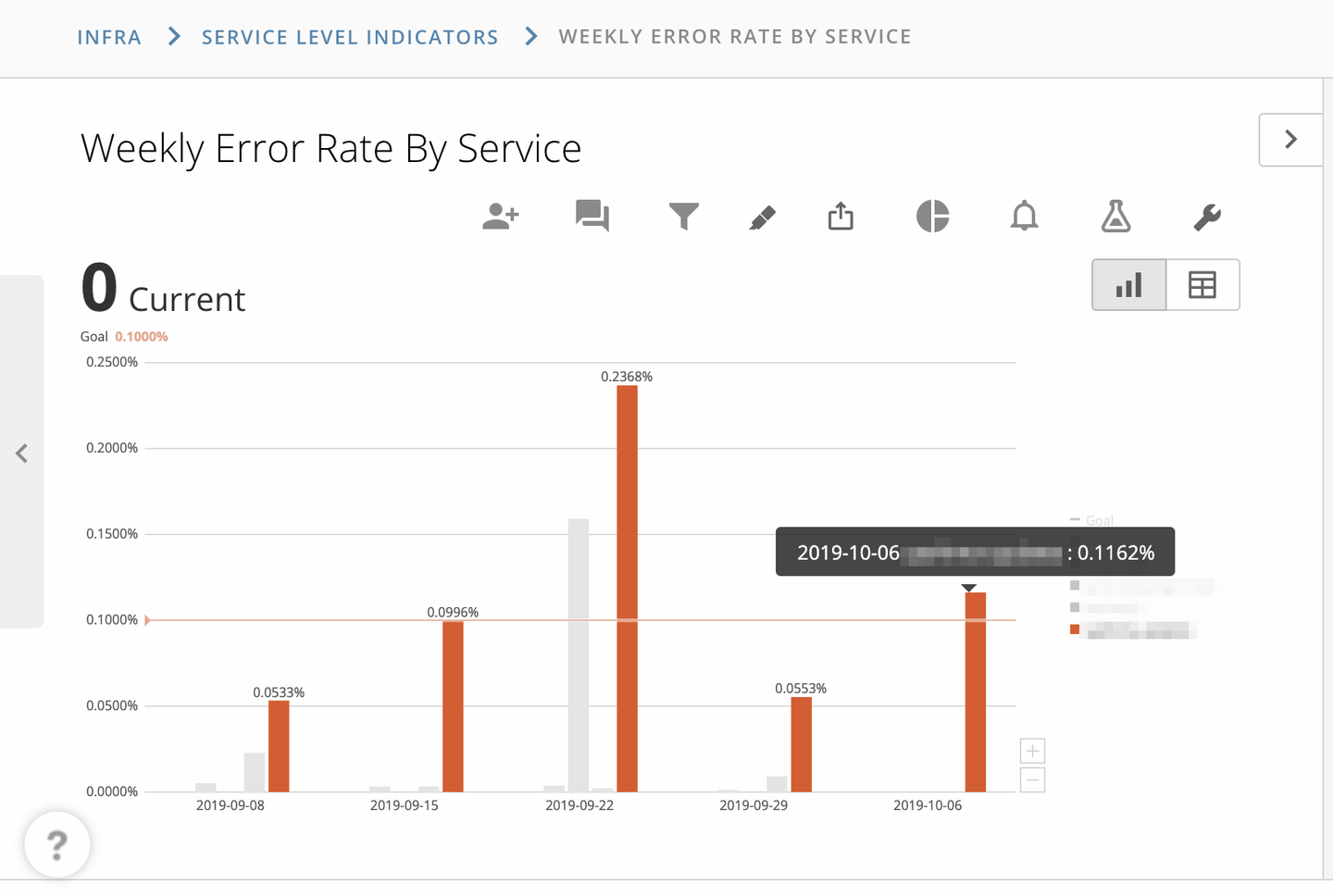
Infrastructure Squad では提供しているサービスの信頼性に問題がないかを毎週チェックする運用を2018年から開始し、現在も続けています。
SLO を用いて信頼性を監視する取り組みを継続する中で、2020年頃に運用面で課題が発生し始めました。
平常時は問題ありませんが、 SLO が未達となった場合にどう対応するのかが曖昧な状態でした。どう対応するかは担当者次第となっており、回復のためのアクションが遅れてしまい信頼性が低下してしまうといった問題や、逆に過剰に反応してしまい本来必要なかったリソースを掛けてプロダクト開発の手を止めてしまうといったケースもありました。
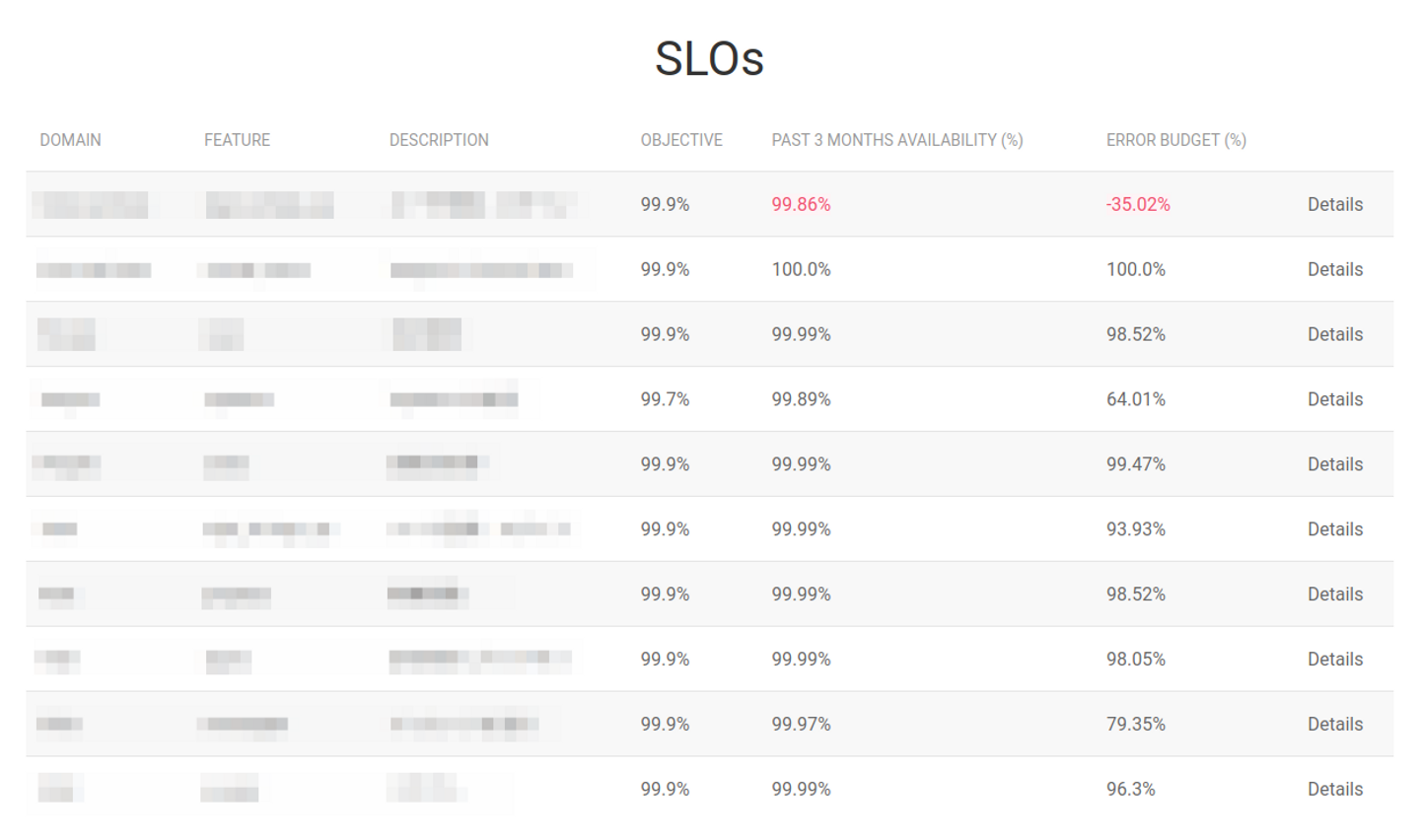
この課題に対応するために Error Budget の概念を導入しました。ある期間で許容されるエラー数を可視化し、 Error Budget が消化され 0 になった場合に行動のトリガーとすることが明文化されました。
また、既存の集計基盤では Error Budget の可視化が難しかったことから、 SLO Dashboard という社内サービスを内製しました。
2021年頃から社内で GraphQL の利用が増加し、既存の基盤では SLI を集計することができず SLO の運用に影響が出てきました。
はじめは新機能等の SLO としては定義されていない箇所で GraphQL が採用されていましたが、徐々に SLO に設定されているコア機能でも利用されるようになりました。
今まで SLI はロードバランサーのログに含まれるリクエスト情報とステータスコードにより集計していましたが、 GraphQL の場合は集計としては利用できません。理由は主に2点あげられます。
POST /graphql になるため機能単位での集計ができないこれらの問題に対処するため、 GraphQL 用の集計基盤を新しく設計することにしました。
まず機能ごとに集計できるようにするため、計測するポイントをロードバランサーからアプリケーションのログに変更しました。アプリケーションのログを取る基盤は servicex という社内共通ライブラリで既に整備されていたため、これを利用して集計をすることになりました。
何をエラーとして扱うかはアプリケーションが「SLI/SLO でエラーとして扱うべきか」を servicex のログに追加することでクリアしました。デフォルトで全てのエラーが SLI/SLO でエラーとして扱われるようになっており、 SLI/SLO にエラーとして算入したくないリクエスト (例: Not Found Error) が発生した場合はホワイトリストに追加するという運用にしています。
しばらく GraphQL を利用した機能を監視できていない状態がありましたが、集計基盤の整備により再びコア機能の信頼性が維持できていることを確認できるようになりました。
ここまでは SLO 運用について過去に取り組んだ施策について紹介しましたが、最後に1つ現在の課題を紹介したいと思います。
現在の SLO 運用は毎週エンジニアがダッシュボードを確認することで回しています。また集計には1日かかるシステムになっており、その日のうちに発生した問題については検知できないという課題があります。
これに対処するため、 SLO 対象の機能をリアルタイムに近い間隔で監視し自動で通知するような仕組みを導入しようとしています。いくつかの機能に対して自動アラート設定を有効化したところユーザー体験を損なう問題に早いタイミングで気付けるケースが複数確認できており、全体への適用を進めています。
以上、 Wantedly での SLO の取り組みについて紹介しました。これからも Infrastructure Squad では Wantedly のサービス信頼性を維持するために運用改善を続けていく予定です。
ここには書ききれなかった話もあるので、興味があればぜひ下記の募集から「話を聞きに行きたい」をクリックしてもらえると嬉しいです。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()
/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

